xTuring
0.1.8


xTuring provides fast, efficient and simple fine-tuning of open-source LLMs, such as Mistral, LLaMA, GPT-J, and more.
By providing an easy-to-use interface for fine-tuning LLMs to your own data and application, xTuring makes it
simple to build, modify, and control LLMs. The entire process can be done inside your computer or in your
private cloud, ensuring data privacy and security.
With xTuring you can,
pip install xturingfrom xturing.datasets import InstructionDataset
from xturing.models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset("./examples/models/llama/alpaca_data")
# Initialize the model
model = BaseModel.create("llama_lora")
# Finetune the model
model.finetune(dataset=instruction_dataset)
# Perform inference
output = model.generate(texts=["Why LLM models are becoming so important?"])
print("Generated output by the model: {}".format(output))You can find the data folder here.
We are excited to announce the latest enhancements to our xTuring library:
LLaMA 2 integration - You can use and fine-tune the LLaMA 2 model in different configurations: off-the-shelf, off-the-shelf with INT8 precision, LoRA fine-tuning, LoRA fine-tuning with INT8 precision and LoRA fine-tuning with INT4 precision using the GenericModel wrapper and/or you can use the Llama2 class from xturing.models to test and finetune the model.from xturing.models import Llama2
model = Llama2()
## or
from xturing.models import BaseModel
model = BaseModel.create('llama2')Evaluation - Now you can evaluate any Causal Language Model on any dataset. The metrics currently supported is perplexity.# Make the necessary imports
from xturing.datasets import InstructionDataset
from xturing.models import BaseModel
# Load the desired dataset
dataset = InstructionDataset('../llama/alpaca_data')
# Load the desired model
model = BaseModel.create('gpt2')
# Run the Evaluation of the model on the dataset
result = model.evaluate(dataset)
# Print the result
print(f"Perplexity of the evalution: {result}")INT4 Precision - You can now use and fine-tune any LLM with INT4 Precision using GenericLoraKbitModel.# Make the necessary imports
from xturing.datasets import InstructionDataset
from xturing.models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset('../llama/alpaca_data')
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel('tiiuae/falcon-7b')
# Run the fine-tuning
model.finetune(dataset)# Make the necessary imports
from xturing.models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel.create("llama2_int8")
# Once the model has been quantized, do inferences directly
output = model.generate(texts=["Why LLM models are becoming so important?"])
print(output)# Make the necessary imports
from xturing.datasets import InstructionDataset
from xturing.models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset('../llama/alpaca_data')
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel('tiiuae/falcon-7b')
# Generate outputs on desired prompts
outputs = model.generate(dataset = dataset, batch_size=10)An exploration of the Llama LoRA INT4 working example is recommended for an understanding of its application.
For an extended insight, consider examining the GenericModel working example available in the repository.

$ xturing chat -m "<path-to-model-folder>"
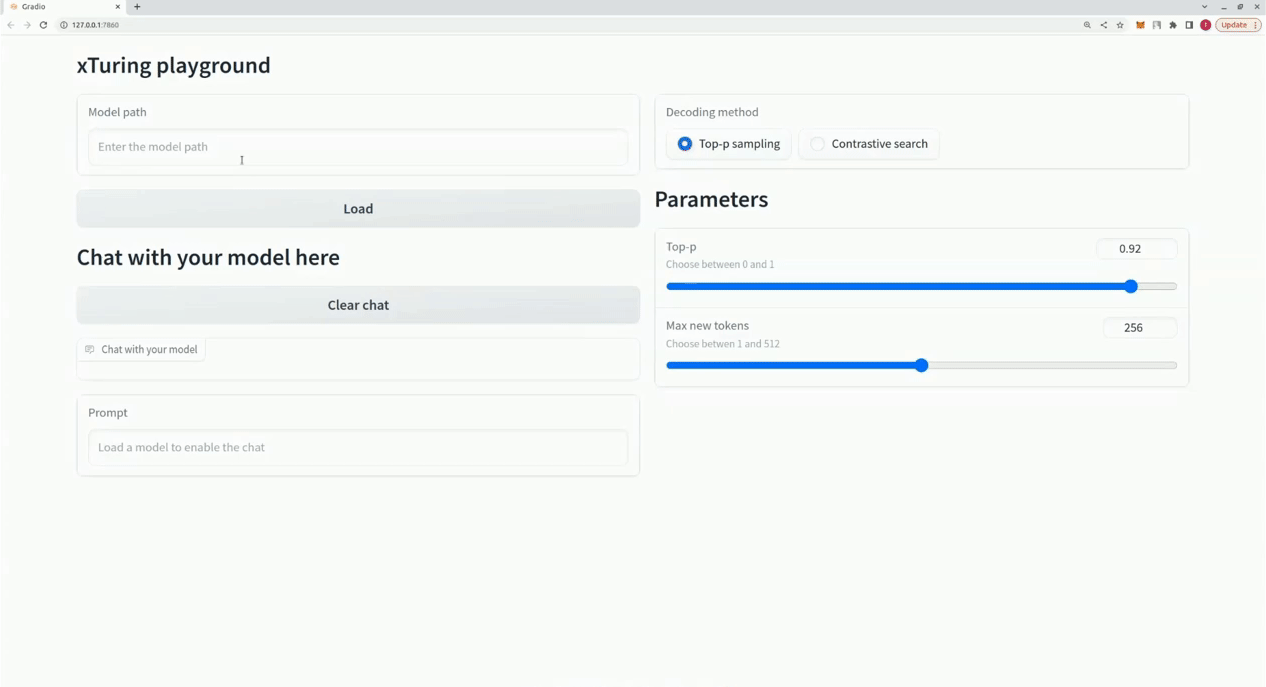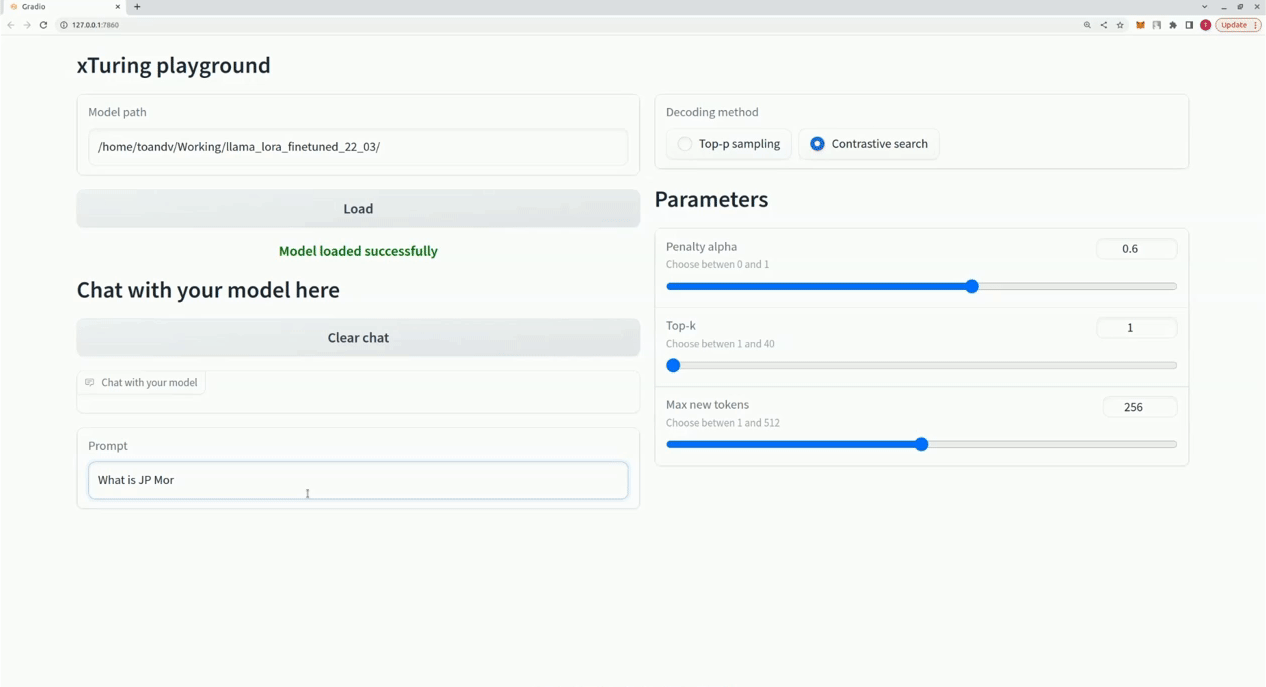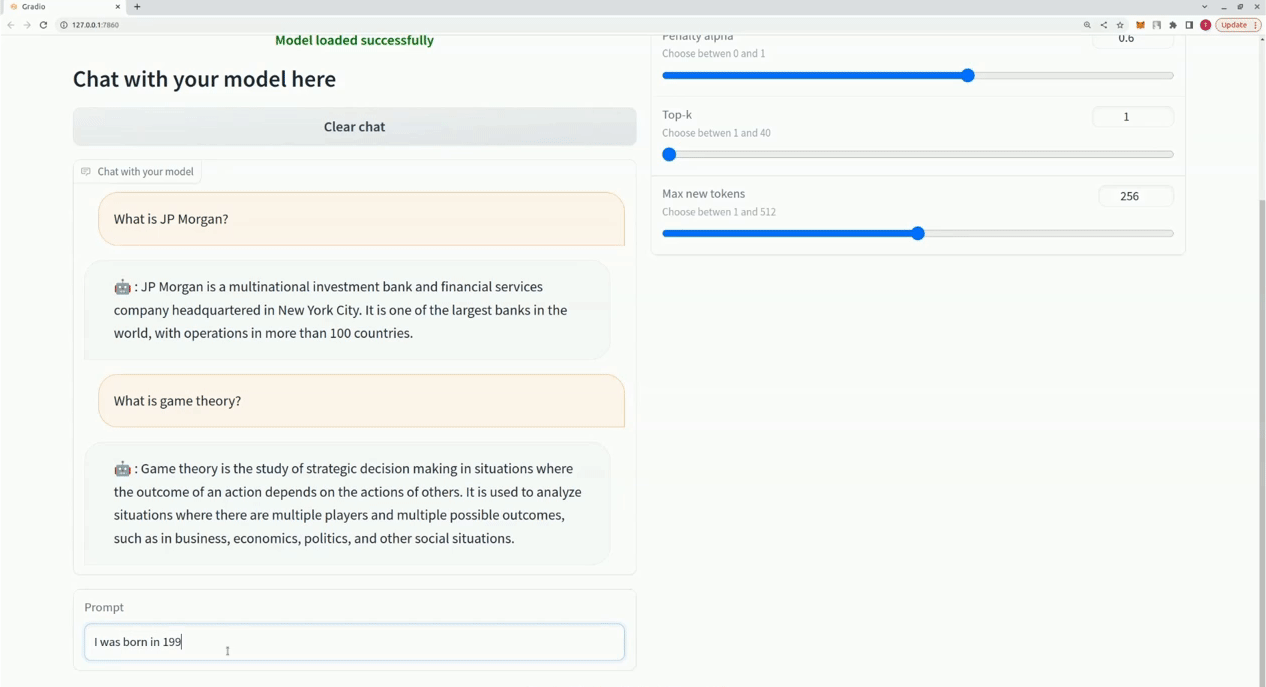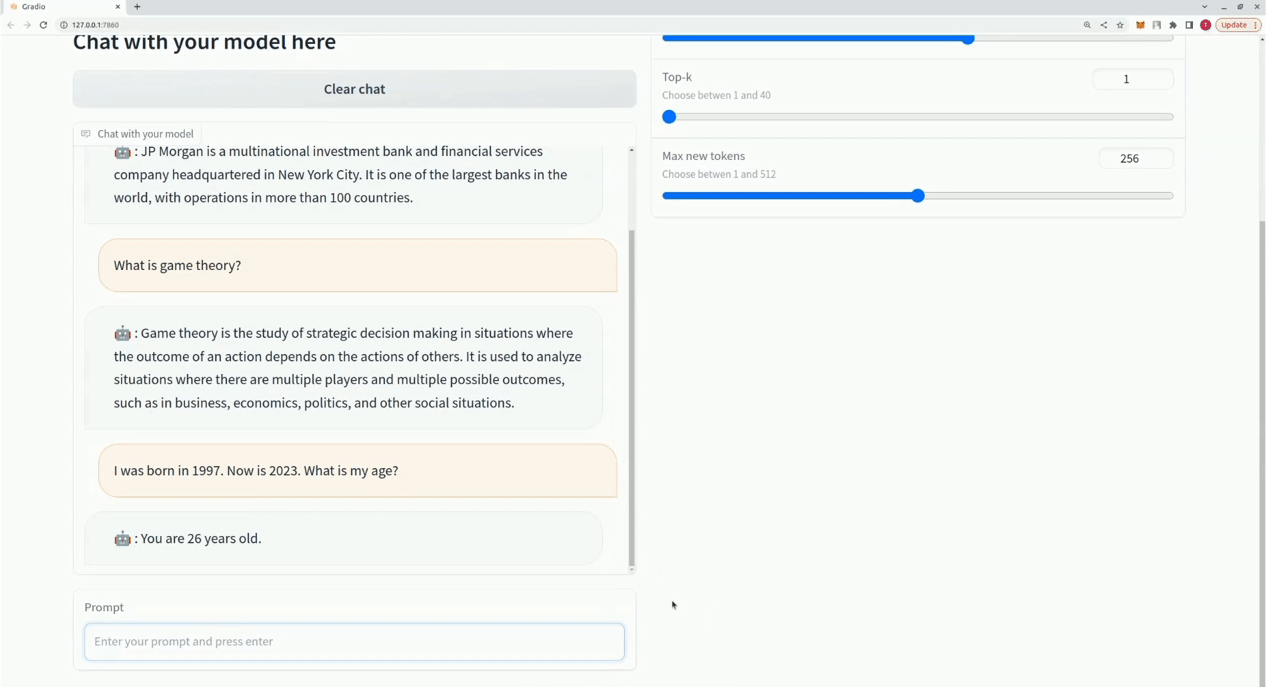
from xturing.datasets import InstructionDataset
from xturing.models import BaseModel
from xturing.ui import Playground
dataset = InstructionDataset("./alpaca_data")
model = BaseModel.create("<model_name>")
model.finetune(dataset=dataset)
model.save("llama_lora_finetuned")
Playground().launch() ## launches localhost UIHere is a comparison for the performance of different fine-tuning techniques on the LLaMA 7B model. We use the Alpaca dataset for fine-tuning. The dataset contains 52K instructions.
Hardware:
4xA100 40GB GPU, 335GB CPU RAM
Fine-tuning parameters:
{
'maximum sequence length': 512,
'batch size': 1,
}| LLaMA-7B | DeepSpeed + CPU Offloading | LoRA + DeepSpeed | LoRA + DeepSpeed + CPU Offloading |
|---|---|---|---|
| GPU | 33.5 GB | 23.7 GB | 21.9 GB |
| CPU | 190 GB | 10.2 GB | 14.9 GB |
| Time/epoch | 21 hours | 20 mins | 20 mins |
Contribute to this by submitting your performance results on other GPUs by creating an issue with your hardware specifications, memory consumption and time per epoch.
We have already fine-tuned some models that you can use as your base or start playing with. Here is how you would load them:
from xturing.models import BaseModel
model = BaseModel.load("x/distilgpt2_lora_finetuned_alpaca")| model | dataset | Path |
|---|---|---|
| DistilGPT-2 LoRA | alpaca | x/distilgpt2_lora_finetuned_alpaca |
| LLaMA LoRA | alpaca | x/llama_lora_finetuned_alpaca |
Below is a list of all the supported models via BaseModel class of xTuring and their corresponding keys to load them.
| Model | Key |
|---|---|
| Bloom | bloom |
| Cerebras | cerebras |
| DistilGPT-2 | distilgpt2 |
| Falcon-7B | falcon |
| Galactica | galactica |
| GPT-J | gptj |
| GPT-2 | gpt2 |
| LlaMA | llama |
| LlaMA2 | llama2 |
| OPT-1.3B | opt |
The above mentioned are the base variants of the LLMs. Below are the templates to get their LoRA, INT8, INT8 + LoRA and INT4 + LoRA versions.
| Version | Template |
|---|---|
| LoRA | <model_key>_lora |
| INT8 | <model_key>_int8 |
| INT8 + LoRA | <model_key>_lora_int8 |
** In order to load any model's INT4+LoRA version, you will need to make use of GenericLoraKbitModel class from xturing.models. Below is how to use it:
model = GenericLoraKbitModel('<model_path>')The model_path can be replaced with you local directory or any HuggingFace library model like facebook/opt-1.3b.
LLaMA, GPT-J, GPT-2, OPT, Cerebras-GPT, Galactica and Bloom modelsGeneric model wrapperFalcon-7B modelIf you have any questions, you can create an issue on this repository.
You can also join our Discord server and start a discussion in the #xturing channel.
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
As an open source project in a rapidly evolving field, we welcome contributions of all kinds, including new features and better documentation. Please read our contributing guide to learn how you can get involved.


