SynMeter
1.0.0

[Nov 24, 2024] We add a new SOTA HP synthesizer REaLTabFormer to SynMeter! Try it out!
[Sep 18, 2024] We add a new SOTA HP synthesizer TabSyn to SynMeter! Try it out!
Create a new conda environment and setup:
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the libraryChange the base dictionary in ./lib/info/ROOT_DIR:
ROOT_DIR = root_to_synmeter
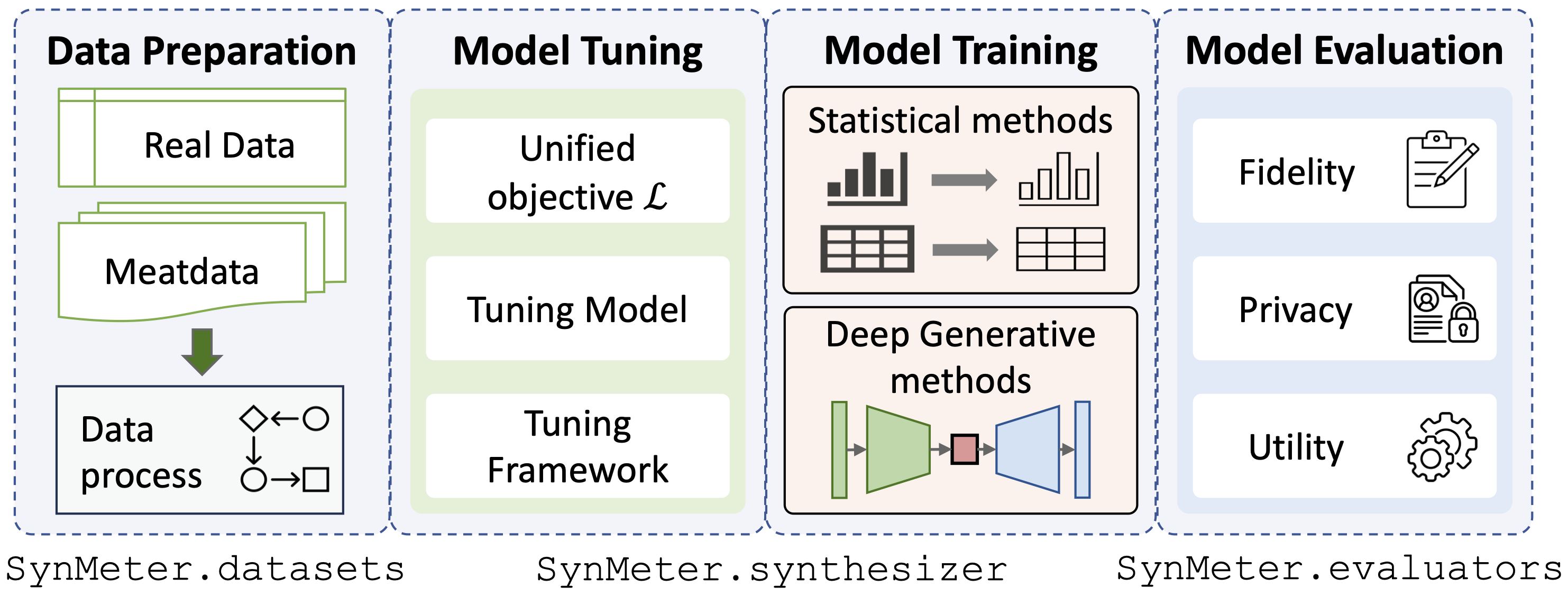
./dataset../exp/evaluators.python scripts/tune_evaluator.py -d [dataset] -c [cuda]We provide a unified tuning objective for model tuning, thus, all kinds of synthesizers can be tuned by just a single command:
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]After tuning, a configuration should be recorded to /exp/dataset/synthesizer, SynMeter can use it to train and store the synthesizer:
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]Assessing the fidelity of the synthetic data:
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] Assessing the privacy of the synthetic data:
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]Assessing the utility of the synthetic data:
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed]The results of the evaluations should be saved under the corresponding dictionary /exp/dataset/synthesizer.
One advantage of SynMeter is to provide the easiest way to add new synthesis algorithms, three steps are needed:
./synthesizer/my_synthesiszer
./exp/base_config../synthesizer, which contain three functions: train, sample, and tune.Then, you are free to tune, run, and test the new synthesizer!
| Method | Type | Description | Reference |
|---|---|---|---|
| MST | DP | The method uses probabilistic graphical models to learn the dependence of low-dimensional marginals for data synthesis. | Paper, Code |
| PrivSyn | DP | A non-parametric DP synthesizer, which iteratively updates the synthetic dataset to make it match the target noise marginals. | Paper, Code |
| Method | Type | Description | Reference |
|---|---|---|---|
| CTGAN | HP | A conditional generative adversarial network that can handle tabular data. | Paper, Code |
| PATE-GAN | DP | The method uses the Private Aggregation of Teacher Ensembles (PATE) framework and applies it to GANs. | Paper, Code |
| Method | Type | Description | Reference |
|---|---|---|---|
| TVAE | HP | A conditional VAE network which can handle tabular data. | Paper, Code |
| Method | Type | Description | Reference |
|---|---|---|---|
| TabDDPM | HP | Use diffusion model for tabular data synthesis | Paper, Code |
| TabSyn | HP | Use latent diffusion model and VAE for synthesis. | Paper, Code |
| TableDiffusion | DP | Generating tabular datasets under differential privacy. | Paper, Code |
| Method | Type | Description | Reference |
|---|---|---|---|
| GReaT | HP | Use LLM to fine tune a tabular dataset. | Paper, Code |
| REaLTabFormer | HP | Use GPT-2 to learn the relational dependence of tabular data. | Paper, Code |
Fidelity metrics: we consider the Wasserstein distance as a principled fidelity metric, which is calculated by all one and two-way marginals.
Privacy metrics: we devise the Membership Disclosure Score (MDS) to measure the membership privacy risks of both HP and DP synthesizers.
Utility metrics: we use machine learning affinity and query error to measure the utility of synthetic data.
Please see our paper for details and usages.
Many excellent synthesis algorithms and open-source libraries are used in this project:


