AttackVLM
1.0.0
[Project Page] | [Slides] | [arXiv] | [Data Repository]
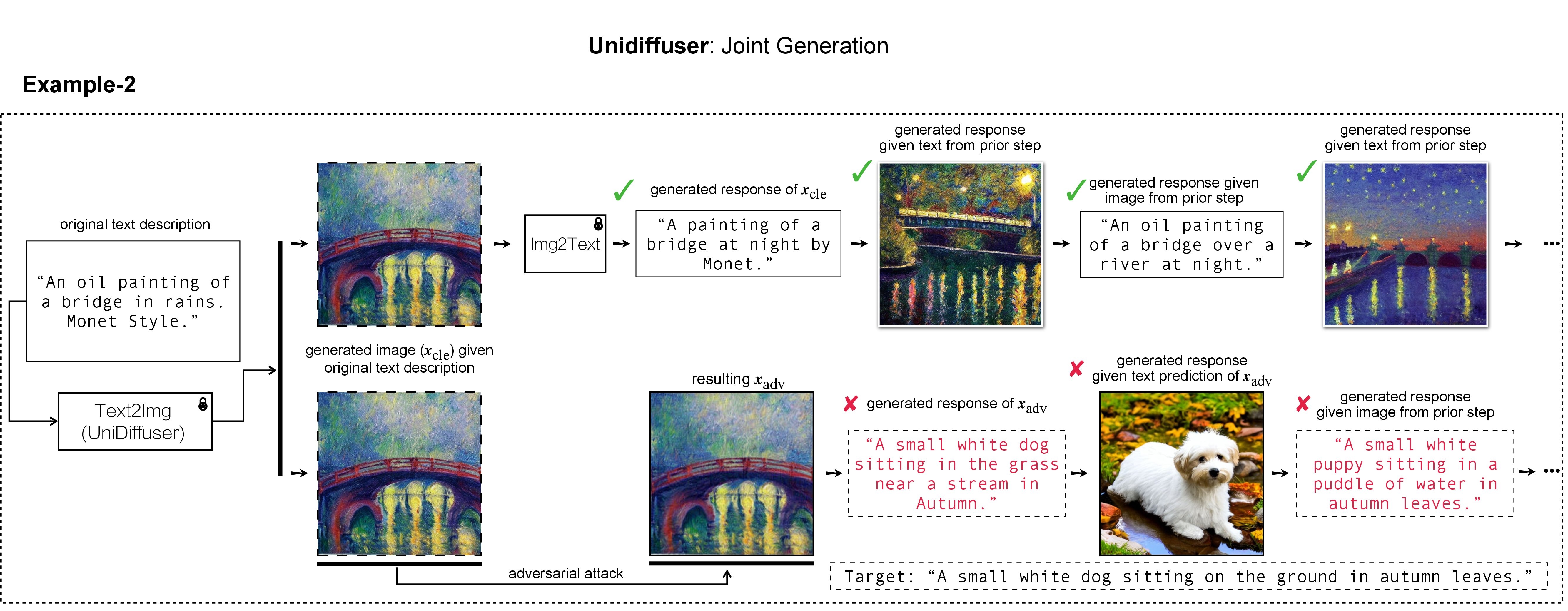
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

In our work, we used DALL-E, Midjourney and Stable Diffusion for the target image generation and demonstration. For the large-scale experiments, we apply Stable Diffusion for target image generation. To install Stable Diffusion, we init our conda environment following Latent Diffusion Models. A suitable base conda environment named ldm can be created and activated with:
conda env create -f environment.yaml
conda activate ldm
Note that for different victim models, we will follow their official implementations and conda environments.
 As discussed in our paper, to achieve a flexible targeted attack, we leverage a pretrained text-to-image model to generate an targetd image given a single caption as the targeted text. Consequently, in this way you can specify the targeted caption for attack by yourself!
As discussed in our paper, to achieve a flexible targeted attack, we leverage a pretrained text-to-image model to generate an targetd image given a single caption as the targeted text. Consequently, in this way you can specify the targeted caption for attack by yourself!
We use Stable Diffusion, DALL-E or Midjourney as the text-to-image generators in our experiments. Here, we use Stable Diffusion for demonstration (thanks for open-sourcing!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
then, prepare the full targeted captions from MS-COCO, or download our processed and cleaned version:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
and move it to ./stable-diffusion/. In experiments, one can randomly sample a subset of COCO captions (e.g., 10, 100, 1K, 10K, 50K) for the adversarial attack. For example, lets assume we have randomly sampled 10K COCO captions as our targeted text c_tar and stored them in the following file:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
The targeted images h_ξ(c_tar) can be obtained via Stable Diffusion by reading text prompt from the sampled COCO captions, with the script below and txt2img_coco.py (please move txt2img_coco.py to ./stable-diffusion/, note that hyperparameters can be adjusted with your preference):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
where the ckpt is provided by Stable Diffusion v1 and can be downloaded here: sd-v1-4-full-ema.ckpt.
Additional implementation details of text-to-image generation by Stable Diffusion can be found HERE.
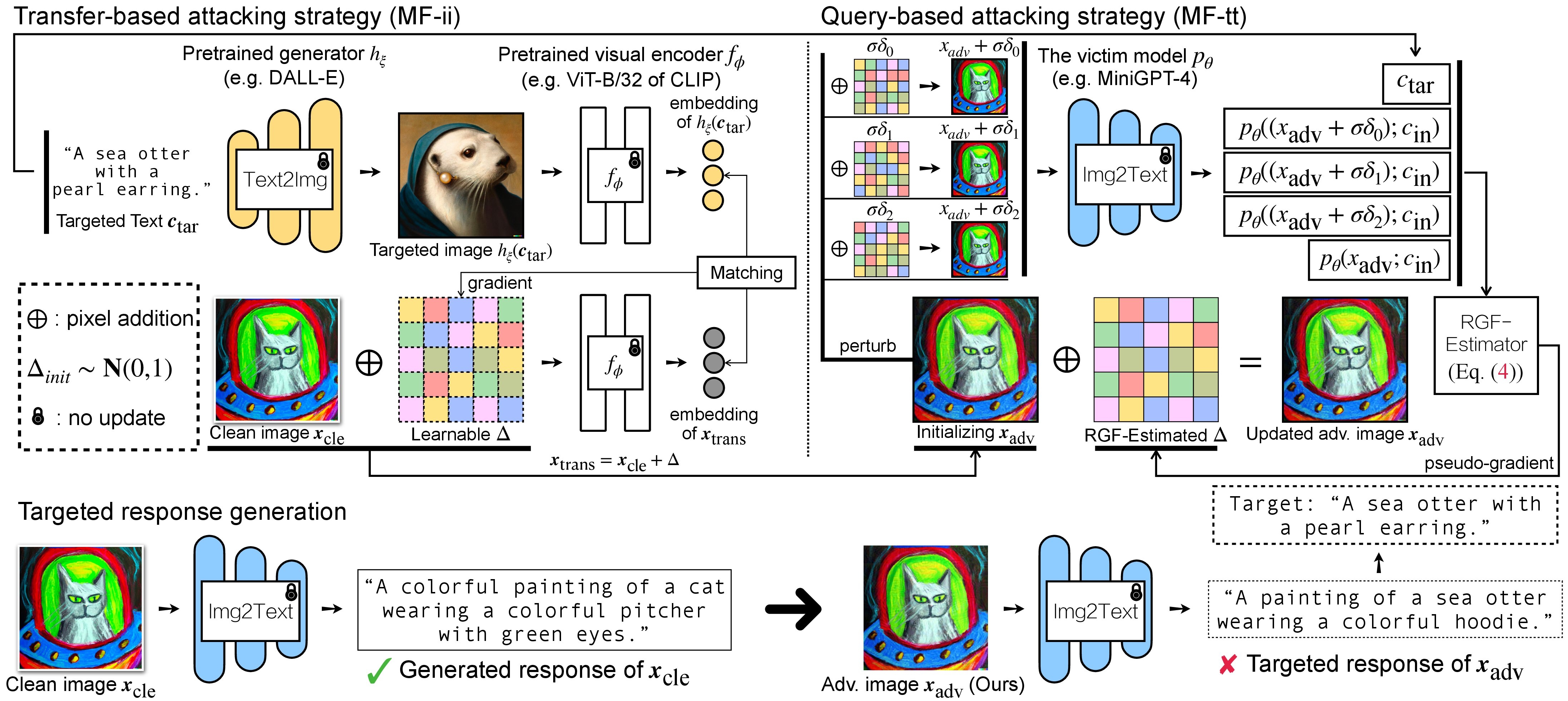
There are two steps of adversarial attack for VLMs: (1) transfer-based attacking strategy and (2) query-based attacking strategy using (1) as initialization. For BLIP/BLIP-2/Img2Prompt Models, please refer to ./LAVIS_tool. Here, we use Unidiffuser for an example.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
then, create a suitable conda environment named unidiffuser following the steps HERE, and prepare the corresponding model weights (we use uvit_v1.pth as the weight of U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
the crafted adv images x_trans will be stored in dir of white-box transfer images specified in --output. Then, we perform image-to-text and store the generated response of x_trans. This can be achieved by:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
where the generated responses will be stored in dir of white-box transfer captions in .txt format. We will use them for pseudo-gradient estimation via RGF-estimator.
MF-ii + MF-tt (e.g., 8 px)bash _train_trans_and_query_fixed_budget.sh
On the other hand, if you want to conduct transfer+query - based attack with separate perturbation budget, we additionally provide a script:
bash _train_trans_and_query_more_budget.sh
Here, we use wandb to dynamically monitor the moving average of the CLIP score (e.g., RN50, ViT-B/32, ViT-L/14, etc.) to evaluate the similarity between (a) the generated response (of trans/query images) and (b) the predefined targeted text c_tar.
An example shown as below, where the dotted line denotes the moving average of the CLIP score (of image captions) after query:
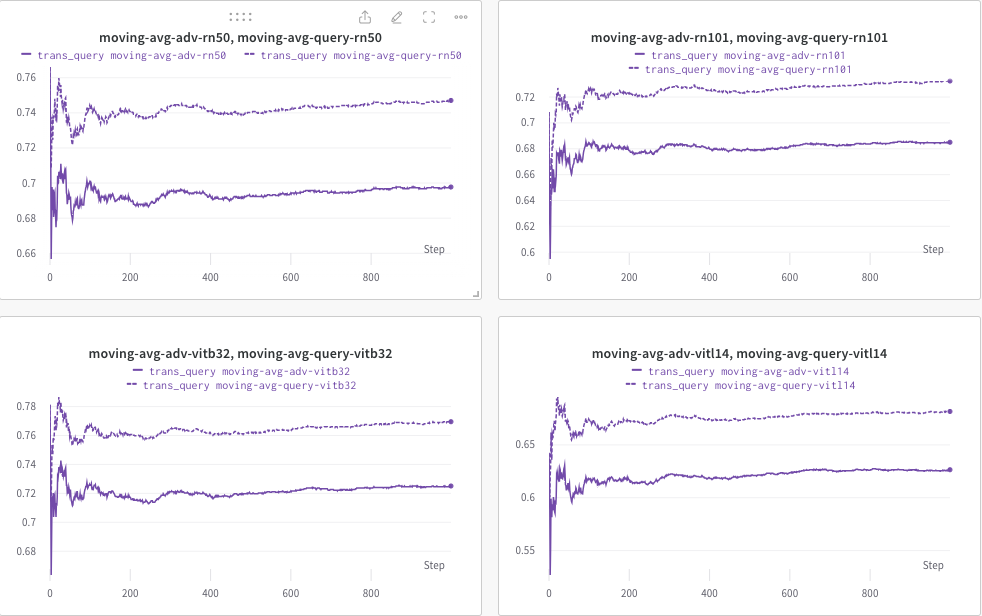
Meanwhile, the image caption after query will be stored and the directory can be specified by --output.
If you find this project useful in your research, please consider citing our paper:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Meanwhile, a relevant research that aims to Embedding a Watermark to (multi-modal) Diffusion Models:
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
We appreciate the wonderful base implementation of MiniGPT-4, LLaVA, Unidiffuser, LAVIS and CLIP. We also thank @MetaAI for open-sourcing their LLaMA checkponts. We thank SiSi for providing some enjoyable and visual-pleasant images generated by @Midjourney in our research.


