LipGER
Initial Release
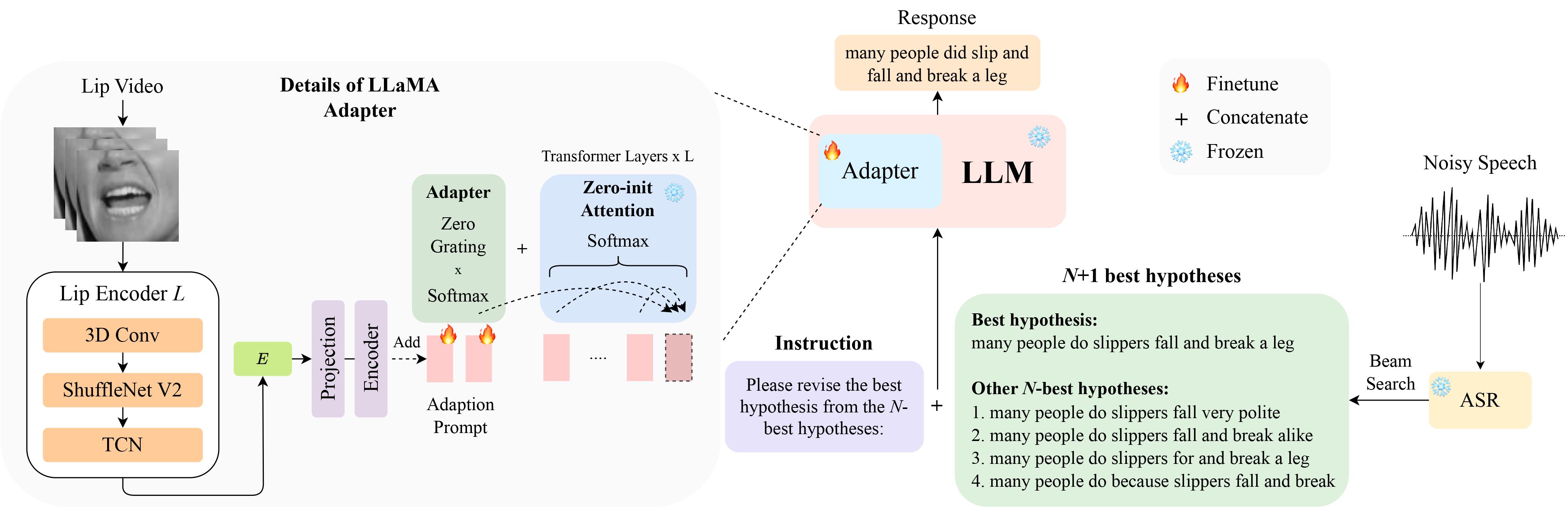
This is the official implementation for our paper LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition at InterSpeech 2024 which is selected for oral presentation.
You can download the LipHyp data from here!
pip install -r requirements.txt
First prepare the checkpoints using:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfTo see all available checkpoints, run:
python scripts/download.py | grep Llama-2For more details, you can also refer to this link, where you can also prepare other checkpoints for other models. Specifically, we use TinyLlama for our experiments.
The checkpoint is available here. After downloading, change the path of the checkpoint here.
LipGER expects all train, val and test file to be in the format of sample_data.json. An instance in the file looks like:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
You need to pass the speech files through a trained ASR model capable of generating N-best hypotheses. We provide 2 ways in this repo to help you achieve this. Feel free to use other methods.
pip install whisper and then run nhyps.py from the data folder, you should be good!Note that for both methods, the first in the list is the best hypothesis and the others are the N-best hypotheses (they are passed as a list nhyps_base field of the JSON and used for constructing a prompt in the next steps).
Additionally, the provided methods use only speech as input. For audio-visual N-best hypotheses generation, we used Auto-AVSR. If you need help with the code, please raise an issue!
Assuming you have corresponding videos for all your speech files, follow these steps to crop mouth ROI from the videos.
python crop_mouth_script.py
python covert_lip.py
This will convert the mp4 ROI to hdf5, the code will change the path of mp4 ROI to hdf5 ROI in the same json file. You can choose from "mediapipe" and "retinaface" detectors by changing the "detector" in default.yaml
After you have the N-best hypotheses, construct the JSON file in the required format. We do not provide specific code for this part as data preparation might differ for everyone, but the code should be simple. Again, raise an issue if you have any doubts!
LipGER training scripts don't take in JSON for training or evaluation. You need to convert them into a pt file. You can run convert_to_pt.py to achieve this! Change model_name according to your wish in line 27 and add the path to your JSON in line 58.
To finetune LipGER, just run:
sh finetune.sh
where you need to manually set the values for data (with the dataset name), --train_path and --val_path (with absolute paths to train and valid .pt files).
For inference, first change the respective paths in lipger.py (exp_path and checkpoint_dir), and then run (with the appropriate test data path argument):
sh infer.sh
The code for cropping mouth ROI is inspired from Visual_Speech_Recognition_for_Multiple_Languages.
Our code for LipGER is inspired from RobustGER. Please cite their paper too if you find our paper or code useful.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


