ChatRWKV
1.0.0
RWKV homepage: https://www.rwkv.com
ChatRWKV is like ChatGPT but powered by my RWKV (100% RNN) language model, which is the only RNN (as of now) that can match transformers in quality and scaling, while being faster and saves VRAM. Training sponsored by Stability EleutherAI :)
Our latest version is RWKV-6 https://arxiv.org/abs/2404.05892 (Preview models: https://huggingface.co/BlinkDL/temp )
RWKV-6 3B Demo: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
RWKV-6 7B Demo: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
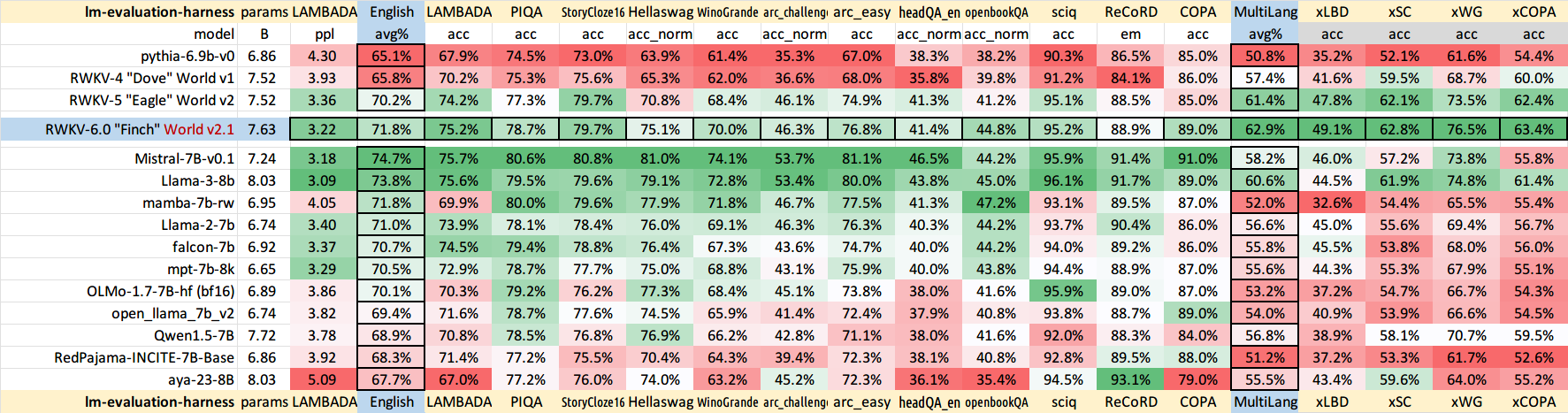
RWKV-LM main repo: https://github.com/BlinkDL/RWKV-LM (explanation, fine-tuning, training, etc.)
Chat Demo for developers: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
Twitter: https://twitter.com/BlinkDL_AI
Homepage: https://www.rwkv.com/
Raw cutting-edge RWKV weights: https://huggingface.co/BlinkDL
HF-compatible RWKV weights: https://huggingface.co/RWKV
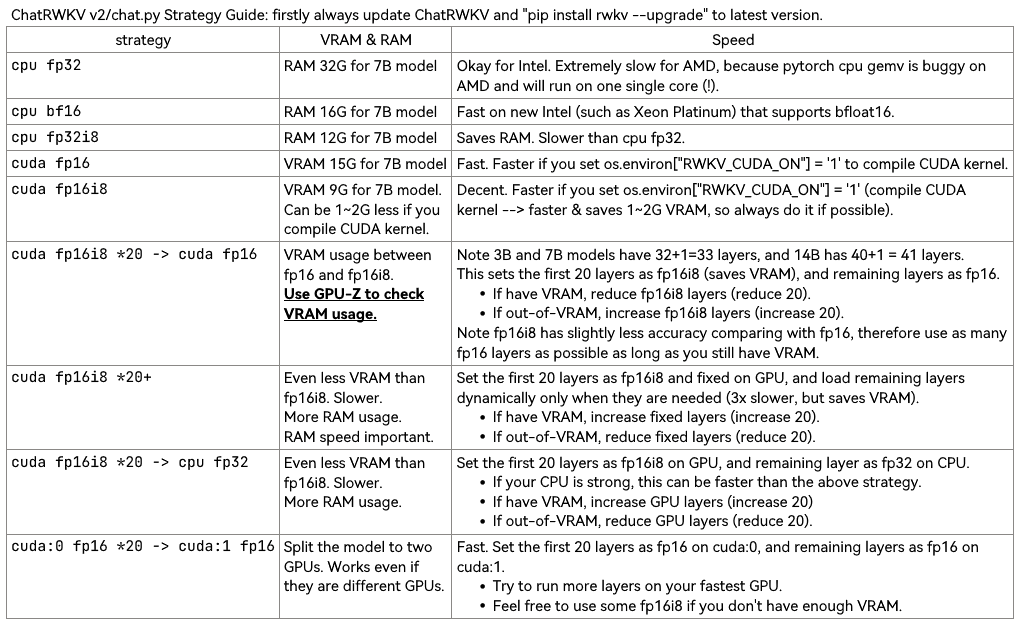
Use v2/convert_model.py to convert a model for a strategy, for faster loading & saves CPU RAM.
Note RWKV_CUDA_ON will build a CUDA kernel (much faster & saves VRAM). Here is how to build it ("pip install ninja" first):
# How to build in Linux: set these and run v2/chat.py
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# How to build in win:
Install VS2022 build tools (https://aka.ms/vs/17/release/vs_BuildTools.exe select Desktop C++). Reinstall CUDA 11.7 (install VC++ extensions). Run v2/chat.py in "x64 native tools command prompt".
RWKV pip package: https://pypi.org/project/rwkv/ (please always check for latest version and upgrade)
https://github.com/cgisky1980/ai00_rwkv_server Fastest GPU inference API with vulkan (good for nvidia/amd/intel)
https://github.com/cryscan/web-rwkv backend for ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp Fast CPU/cuBLAS/CLBlast inference: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state tuning
https://github.com/RWKV/RWKV-infctx-trainer Infctx trainer
World demo script: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_WORLD.py
Raven Q&A demo script: https://github.com/BlinkDL/ChatRWKV/blob/main/v2/benchmark_more.py
RWKV in 150 lines (model, inference, text generation): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
RWKV v5 in 250 lines (with tokenizer too): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
Building your own RWKV inference engine : begin with https://github.com/BlinkDL/ChatRWKV/blob/main/src/model_run.py which is easier to understand (used by https://github.com/BlinkDL/ChatRWKV/blob/main/chat.py).
RWKV preprint https://arxiv.org/abs/2305.13048
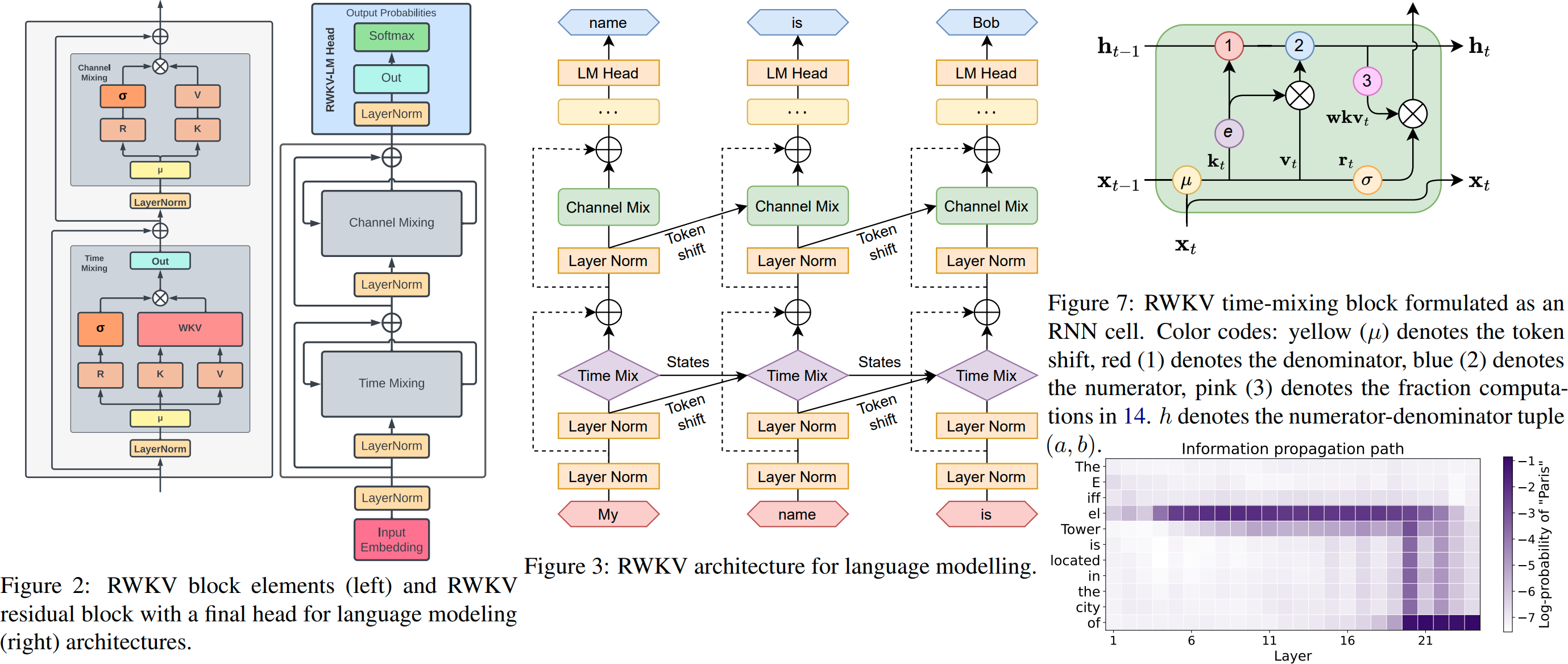
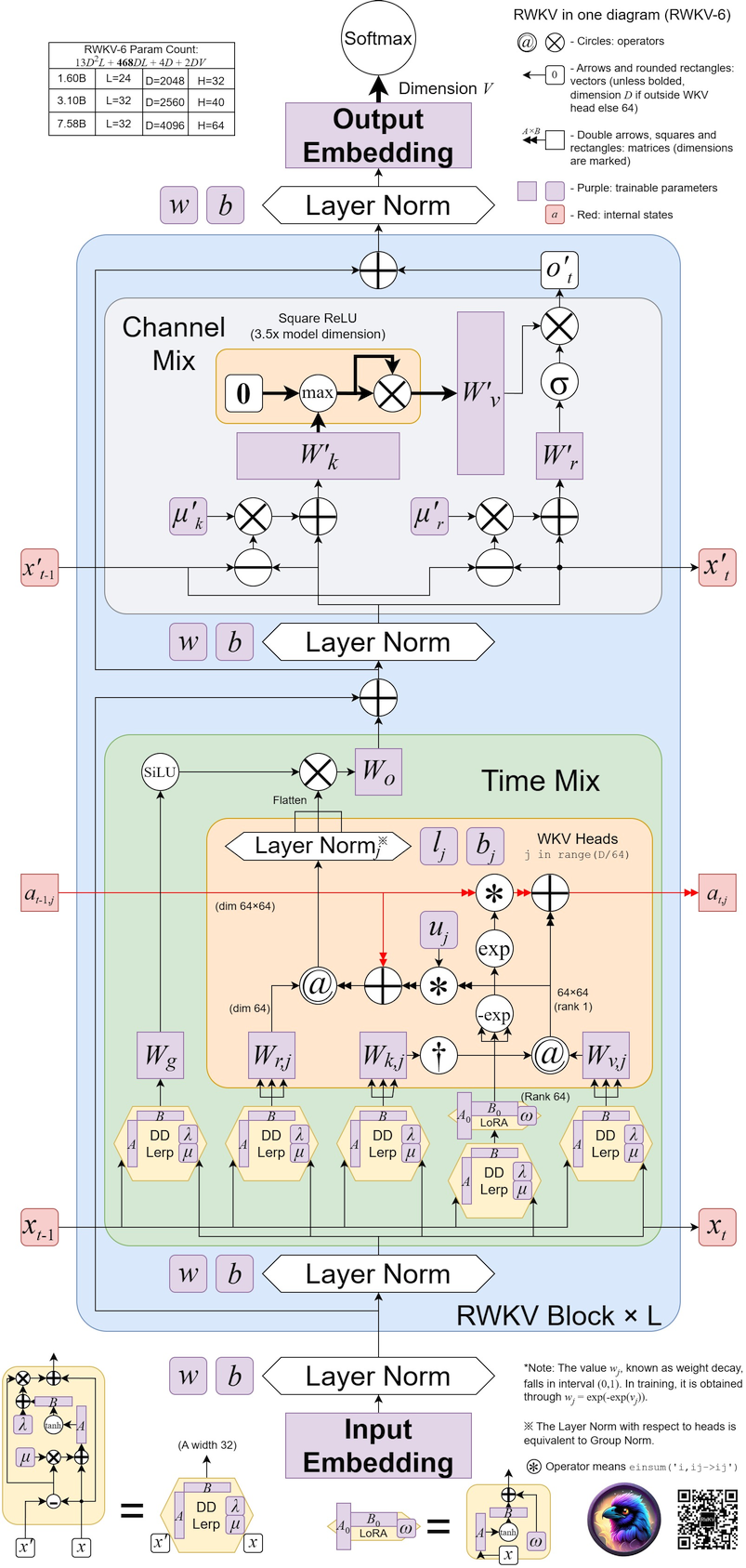
RWKV v6 illustrated:
Cool Community RWKV Projects:
https://github.com/saharNooby/rwkv.cpp fast i4 i8 fp16 fp32 CPU inference using ggml
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda fast windows/linux & cuda/rocm/vulkan GPU inference (no need for python & pytorch)
https://github.com/Blealtan/RWKV-LM-LoRA LoRA fine-tuning
https://github.com/josStorer/RWKV-Runner cool GUI
More RWKV projects: https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
ChatRWKV v2: with "stream" and "split" strategies, and INT8. 3G VRAM is enough to run RWKV 14B :) https://github.com/BlinkDL/ChatRWKV/tree/main/v2
os.environ["RWKV_JIT_ON"] = '1'
os.environ["RWKV_CUDA_ON"] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv.model import RWKV # pip install rwkv
model = RWKV(model='/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040', strategy='cuda fp16')
out, state = model.forward([187, 510, 1563, 310, 247], None) # use 20B_tokenizer.json
print(out.detach().cpu().numpy()) # get logits
out, state = model.forward([187, 510], None)
out, state = model.forward([1563], state) # RNN has state (use deepcopy if you want to clone it)
out, state = model.forward([310, 247], state)
print(out.detach().cpu().numpy()) # same result as above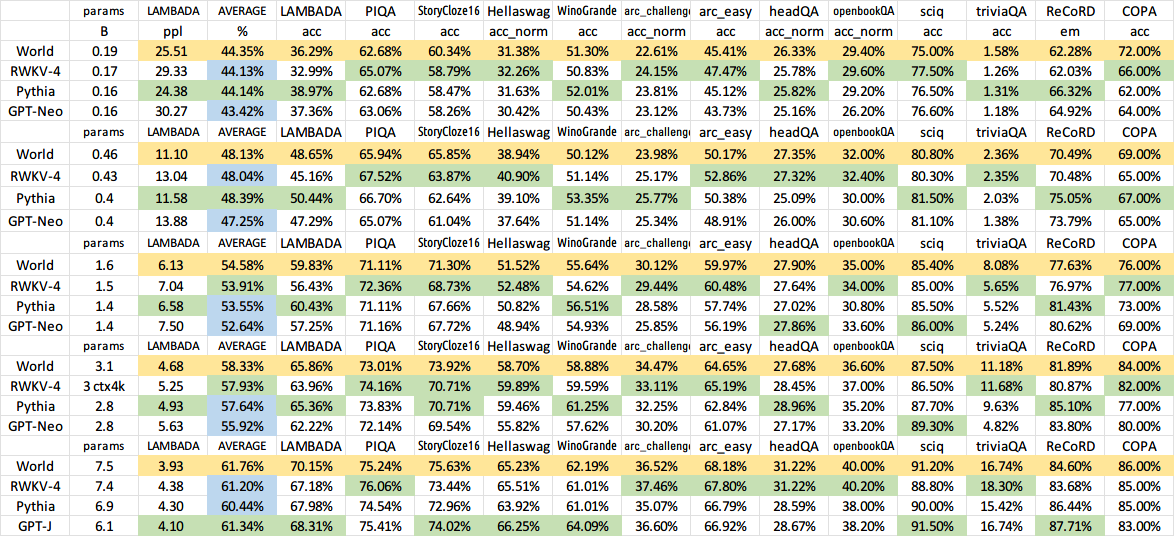
Here is https://huggingface.co/BlinkDL/rwkv-4-raven/blob/main/RWKV-4-Raven-14B-v7-Eng-20230404-ctx4096.pth in action:
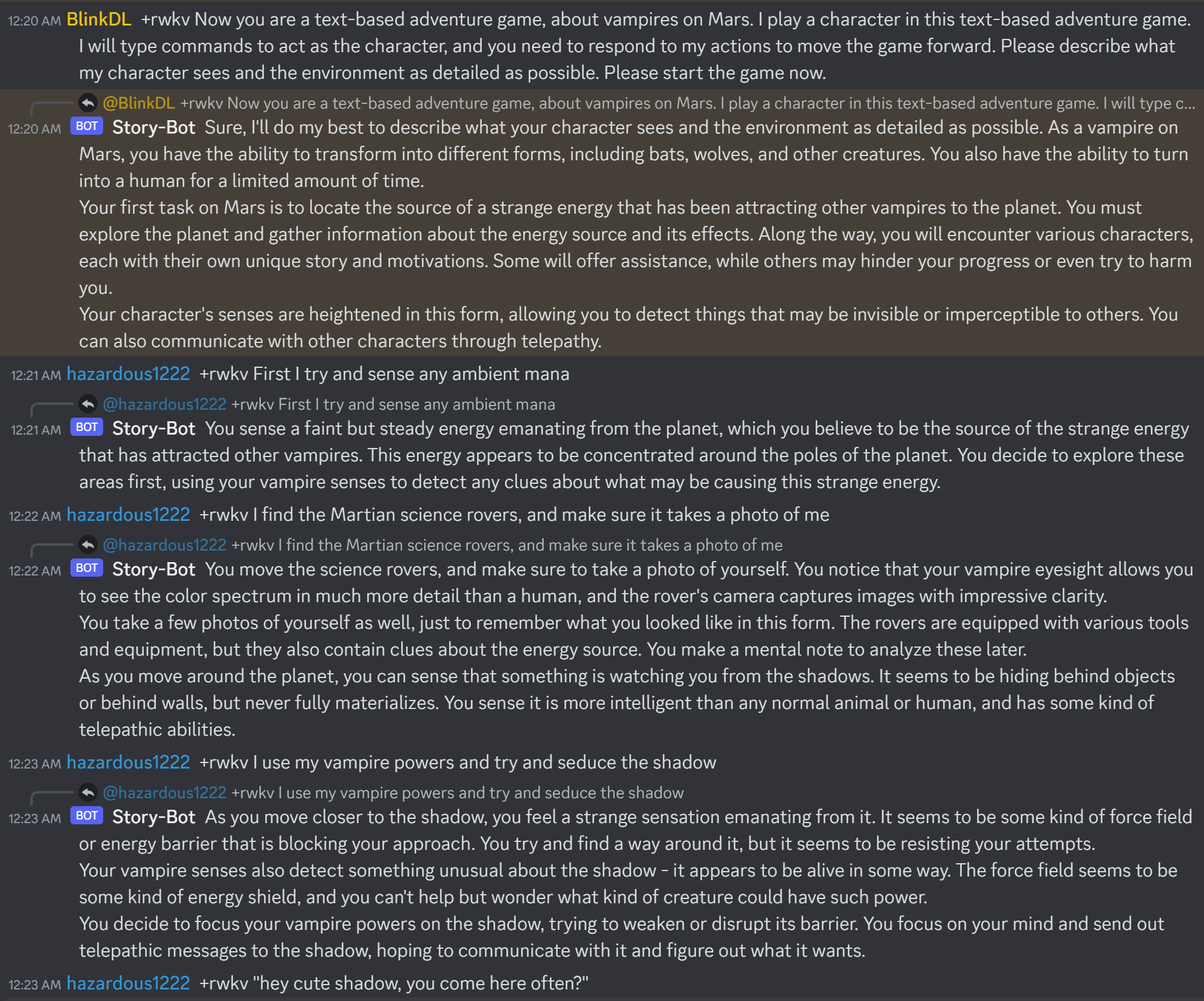
When you build a RWKV chatbot, always check the text corresponding to the state, in order to prevent bugs.
(For v4-raven models, use Bob/Alice. For v4/v5/v6-world models, use User/Assistant)
Bob: xxxxxxxxxxxxxxxxxxnnAlice: xxxxxxxxxxxxxnnBob: xxxxxxxxxxxxxxxxnnAlice:
xxxxx = xxxxx.strip().replace('rn','n').replace('nn','n')
If you are building your own RWKV inference engine, begin with https://github.com/BlinkDL/ChatRWKV/blob/main/src/model_run.py which is easier to understand (used by https://github.com/BlinkDL/ChatRWKV/blob/main/chat.py)
The lastest "Raven"-series Alpaca-style-tuned RWKV 14B & 7B models are very good (almost ChatGPT-like, good at multiround chat too). Download: https://huggingface.co/BlinkDL/rwkv-4-raven
Previous old model results:
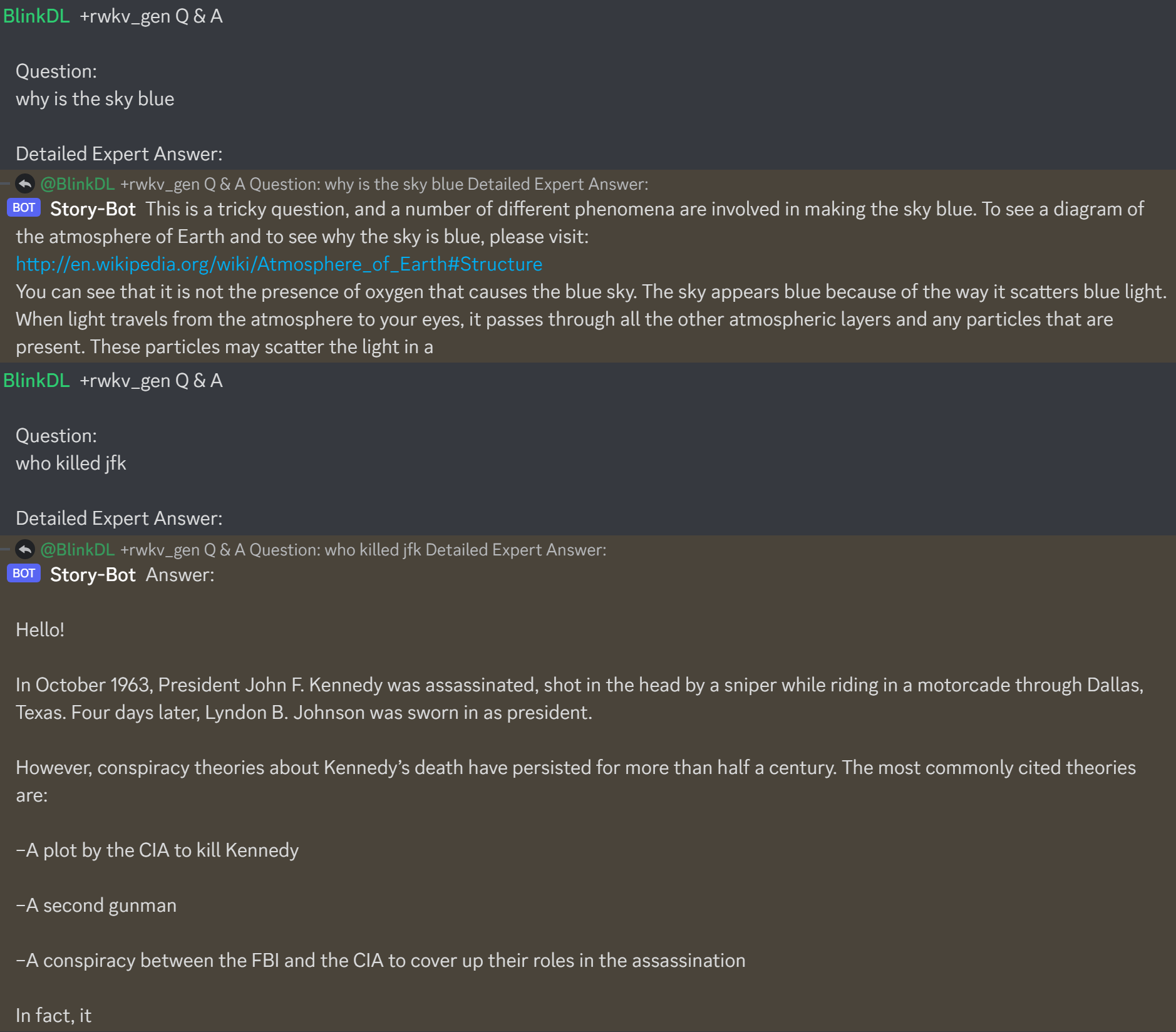
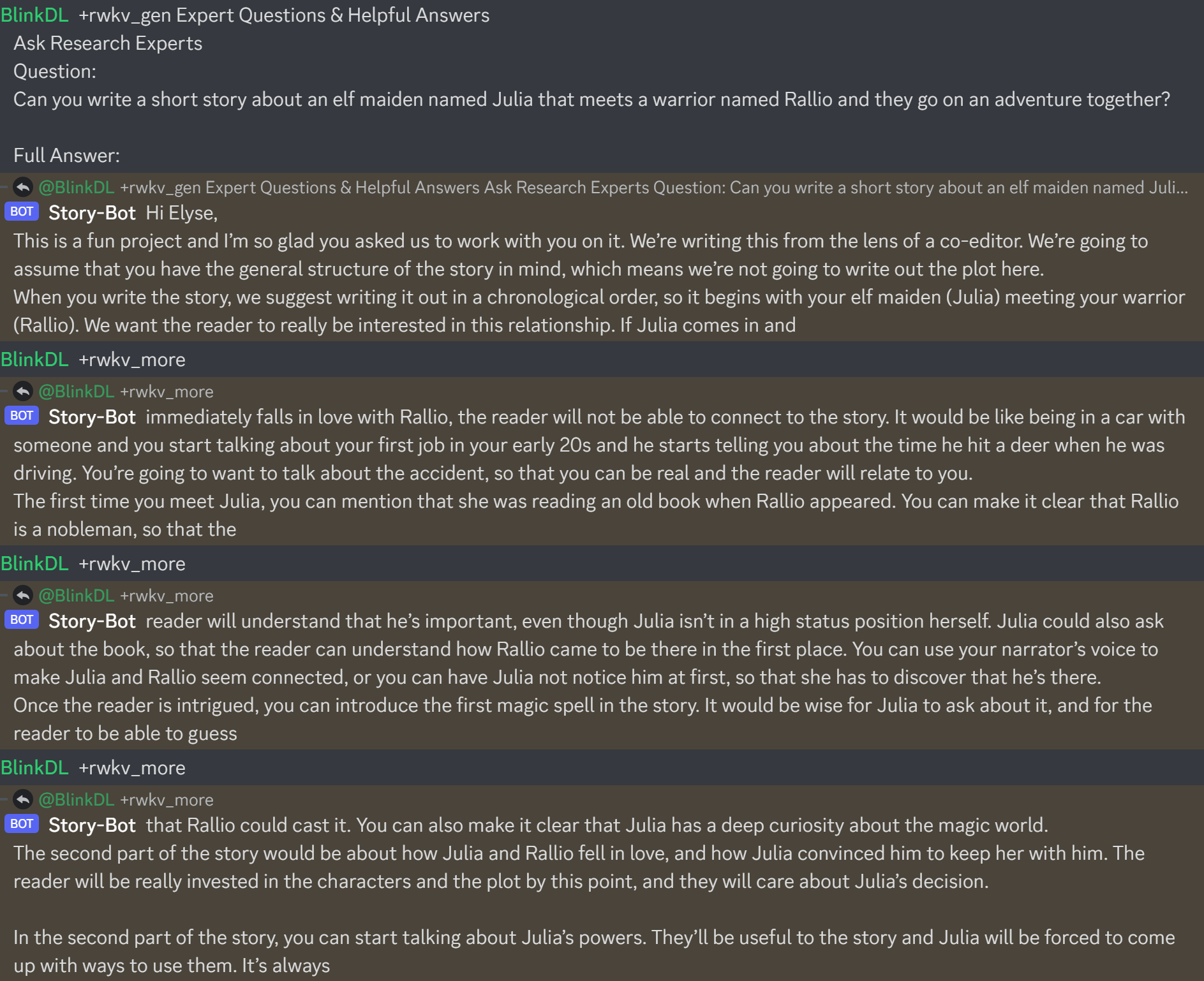

QQ群 553456870(加入时请简单自我介绍)。有研发能力的朋友加群 325154699。
中文使用教程:https://zhuanlan.zhihu.com/p/618011122 https://zhuanlan.zhihu.com/p/616351661
推荐UI:https://github.com/l15y/wenda


