BLIVA
1.0.0
Wenbo Hu*, Yifan Xu*, Yi Li, Weiyue Li, Zeyuan Chen, and Zhuowen Tu. *Equal Contribution
UC San Diego, Coinbase Global, Inc.
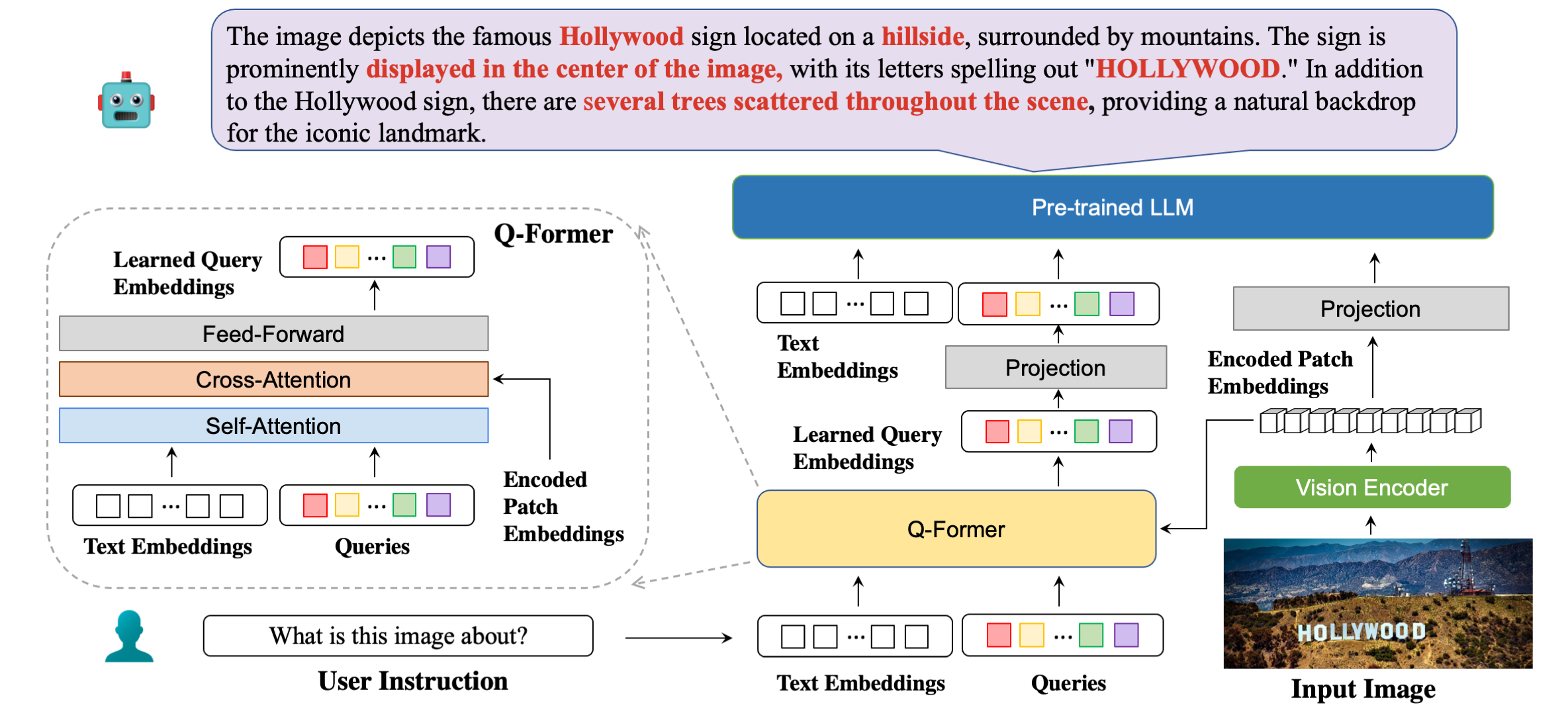
Our model architecture in detail with example responses.
| Method | STVQA | OCRVQA | TextVQA | DocVQA | InfoVQA | ChartQA | ESTVQA | FUNSD | SROIE | POIE | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenFlamingo | 19.32 | 27.82 | 29.08 | 5.05 | 14.99 | 9.12 | 28.20 | 0.85 | 0.12 | 2.12 | 13.67 |
| BLIP2-OPT | 13.36 | 10.58 | 21.18 | 0.82 | 8.82 | 7.44 | 27.02 | 0.00 | 0.00 | 0.02 | 8.92 |
| BLIP2-FLanT5XXL | 21.38 | 30.28 | 30.62 | 4.00 | 10.17 | 7.20 | 42.46 | 1.19 | 0.20 | 2.52 | 15.00 |
| MiniGPT4 | 14.02 | 11.52 | 18.72 | 2.97 | 13.32 | 4.32 | 28.36 | 1.19 | 0.04 | 1.31 | 9.58 |
| LLaVA | 22.93 | 15.02 | 28.30 | 4.40 | 13.78 | 7.28 | 33.48 | 1.02 | 0.12 | 2.09 | 12.84 |
| mPLUG-Owl | 26.32 | 35.00 | 37.44 | 6.17 | 16.46 | 9.52 | 49.68 | 1.02 | 0.64 | 3.26 | 18.56 |
| InstructBLIP (FLANT5XXL) | 26.22 | 55.04 | 36.86 | 4.94 | 10.14 | 8.16 | 43.84 | 1.36 | 0.50 | 1.91 | 18.90 |
| InstructBLIP (Vicuna-7B) | 28.64 | 47.62 | 39.60 | 5.89 | 13.10 | 5.52 | 47.66 | 0.85 | 0.64 | 2.66 | 19.22 |
| BLIVA (FLANT5XXL) | 28.24 | 61.34 | 39.36 | 5.22 | 10.82 | 9.28 | 45.66 | 1.53 | 0.50 | 2.39 | 20.43 |
| BLIVA (Vicuna-7B) | 29.08 | 65.38 | 42.18 | 6.24 | 13.50 | 8.16 | 48.14 | 1.02 | 0.88 | 2.91 | 21.75 |
| Method | VSR | IconQA | TextVQA | Visdial | Flickr30K | HM | VizWiz | MSRVTT |
|---|---|---|---|---|---|---|---|---|
| Flamingo-3B | - | - | 30.1 | - | 60.6 | - | - | - |
| Flamingo-9B | - | - | 31.8 | - | 61.5 | - | - | - |
| Flamingo-80B | - | - | 35.0 | - | 67.2 | - | - | - |
| MiniGPT-4 | 50.65 | - | 18.56 | - | - | 29.0 | 34.78 | - |
| LLaVA | 56.3 | - | 37.98 | - | - | 9.2 | 36.74 | - |
| BLIP-2 (Vicuna-7B) | 50.0 | 39.7 | 40.1 | 44.9 | 74.9 | 50.2 | 49.34 | 4.17 |
| InstructBLIP (Vicuna-7B) | 54.3 | 43.1 | 50.1 | 45.2 | 82.4 | 54.8 | 43.3 | 18.7 |
| BLIVA (Vicuna-7B) | 62.2 | 44.88 | 57.96 | 45.63 | 87.1 | 55.6 | 42.9 | 23.81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e .BLIVA Vicuna 7B
Our Vicuna version model is released at here. Download our model weight and specify the path in the model config here at line 8.
The LLM we used is the v0.1 version from Vicuna-7B. To prepare Vicuna's weight, please refer to our instruction here. Then, set the path to the vicuna weight in the model config file here at Line 21.
BLIVA FlanT5 XXL (Available for Commercial Use)
The FlanT5 version model is released at here. Download our model weight and specify the path in the model config here at line 8.
The LLM weight for Flant5 will automatically begin to download from huggingface when running our inference code.
To answer one question from the image, run the following evaluation code. For example,
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question "what is this image about?"We also support answer multiple choice question, which is the same as we used for evaluation tasks in paper. To provide a list of chioce, it should be a string split by comma. For example,
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question "Which genre does this image belong to?"
--candidates "play, tv show, movie"Our Demo is publicly available at here. To run our demo locally on your machine. Run:
python demo.pyAfter downloading the training datasets and specify their path in dataset configs, we are ready for training. We utilized 8x A6000 Ada in our experiments. Please adjust hyperparamters according to your GPU resources. It may take transformers around 2 minutes to load the model, give some time for the model to start training. Here we give an example of traning BLIVA Vicuna version, the Flant5 version follows the same format.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yamlOr, we also support training Vicuna7b together with BLIVA using LoRA during the second step, by default we don't use this version.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yamlIf you find BLIVA useful for your research and applications, please cite using this BibTeX:
@misc{hu2023bliva,
title={BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions},
author={Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu},
publisher={arXiv:2308.09936},
year={2023},
}This repository's code is under BSD 3-Clause License. Many codes are based on Lavis with BSD 3-Clause License here.
For our model parameters of BLIVA Vicuna Version, it's should be used under LLaMA's model license. For the model weight of BLIVA FlanT5, it's under Apache 2.0 License. For our YTTB-VQA data, it's under CC BY NC 4.0


