Synonyms
Synonyms
Chinese Synonyms for Natural Language Processing and Understanding.
Better Chinese synonyms: chatbot, intelligent question and answer toolkit.
synonyms can be used for many tasks in natural language understanding: text alignment, recommendation algorithms, similarity calculations, semantic offset, keyword extraction, concept extraction, automatic summarization, search engines, etc.
In order to provide stable, reliable, and long-term optimized services, Synonyms changed to use the Chunsong license, v1.0 and charges for downloading machine learning models, see the certificate store for details. Previous contributors (code contributors with outstanding contributions) can contact us to discuss charging issues. -- Chatopera Inc. @ Oct. 2023
Follow steps below to install and activate packages.
pip install -U synonymsThe current stable version is v3.x.
Synonyms's machine learning model package(s) requires a License from Chatopera License Store, first purchase a License and get the license id from Licenses page on Chatopera License Store( license id : In the certificate store, on the certificate details page, click [Copy Certificate Identity] ).
Secondly, set environment variable in your terminal or shell scripts as below.
eg Shell, CMD Scripts on Linux, Windows, macOS.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Jupyter Notebook, etc.
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )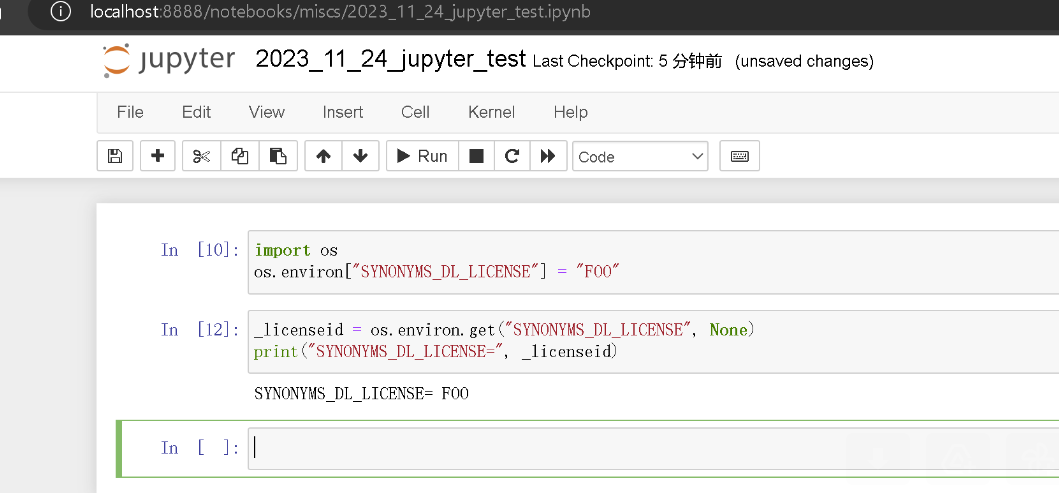
Tip: The word vector file will be downloaded for the first time after installation, and the download speed depends on the network conditions.
Last, download the model package by command or script -
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
Supports using environment variables to configure word segmentation vocabulary and word2vec word vector files.
| environment variables | describe |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | Word vector file trained using word2vec, binary format. |
| SYNONYMS_WORDSEG_DICT | Chinese word segmentation master dictionary , format and usage reference |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"], whether to output debugging logs, set to "TRUE" output, the default is "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) returns a tuple. The tuple contains two items: ([nearby_words], [nearby_words_score]) . nearby_words are synonyms of WORD. They are also stored in the form of a list and are based on distance. The lengths are arranged from near to far, nearby_words_score is the score of the distance between the words at the corresponding position in nearby_words . The score is in the (0-1) interval. The closer it is to 1, the closer it is; SIZE is the number of words returned, and the default is 10. for example:
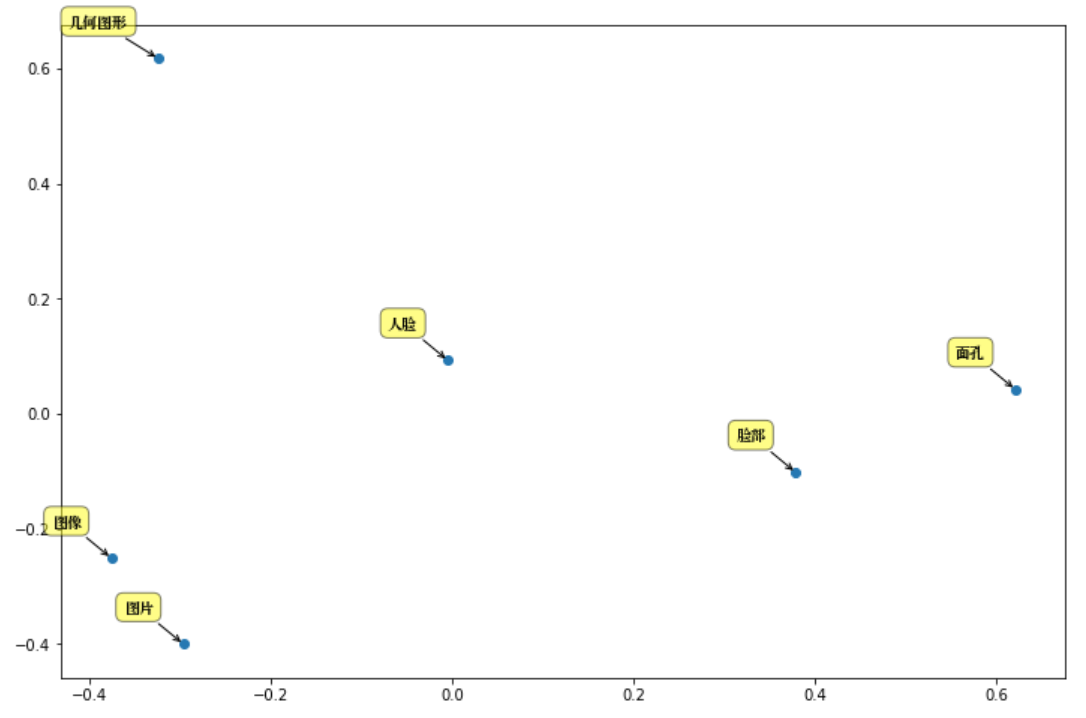
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) In case of OOV, ([], []) is returned, current dictionary size: 435,729.
Comparison of similarity between two sentences
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )Among them, the parameter seg indicates whether synonyms.compare performs word segmentation on sen1 and sen2, and the default is True. Return value: [0-1], and the closer it is to 1, the more similar the two sentences are.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 Print synonyms in a friendly way to facilitate debugging. display(WORD [, SIZE]) calls synonyms#nearby method.
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE is the number of printed vocabulary lists, the default is 10.
Print the description information of the current package:
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
Get a word vector, which is a numpy array. When the word is an unregistered word, a KeyError exception is thrown.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )Obtain a vector of the sentence after word segmentation. The vector is composed in BoW mode.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量Chinese word segmentation
synonyms . seg ( "中文近义词工具包" )The word segmentation result is a tuple consisting of two lists, which are words and corresponding parts of speech.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])This participle does not remove stop words and punctuation.
Extract keywords. By default, keywords are extracted according to importance.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
Get more logs for debugging, set environment variable.
SYNONYMS_DEBUG=TRUE
Taking "human face" as an example to analyze the main components:
$ pip install -r Requirements.txt
$ python demo.pyUpdated status statement.
What users say:
data is built based on wikidata-corpus.
"Synonyms Ci Lin" was compiled by Mei Jiaju and others in 1983. Nowadays, the widely used version is "Synonym Ci Lin Expanded Edition" maintained by the Social Computing and Information Retrieval Research Center of Harbin Institute of Technology. It finely divides Chinese vocabulary into large Categories and subcategories sort out the relationship between words. The expanded version of Synonyms Cilin contains more than 70,000 words, of which more than 30,000 are shared in the form of open data.
HowNet, also known as HowNet, is not just a semantic dictionary, but a knowledge system. The relationship between words is one of its basic usage scenarios. CNKI contains more than 8 words.
The international evaluation standard for word similarity algorithms generally adopts the manual judgment value of the English word pair set published by Miller&Charles. The word pair set consists of ten pairs of highly related, ten pairs of moderately related, and ten pairs of lowly related English word pairs, and then 38 subjects are asked to judge the semantic relevance of these 30 pairs, and finally take their The average value serves as the manual criterion. Then different synonym tools also score the similarity of these words and compare them with manual judgment criteria, such as using the Pearson correlation coefficient. In the Chinese field, it is also a common method to use the translated version of this vocabulary list to compare Chinese synonyms.
The vocabulary list capacity of Synonyms is 435,729. Below we select some words that exist in Synonyms Cilin, CNKI and Synonyms to compare their similarity:
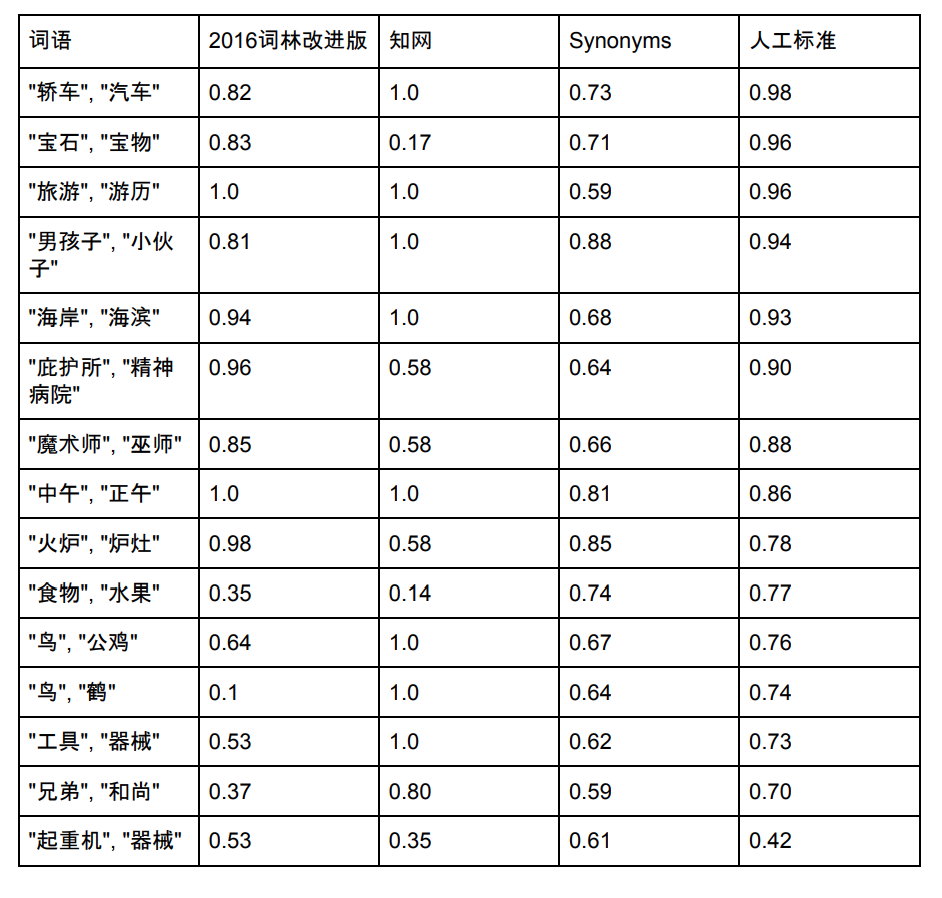
Note: Sources of Synonym Forest and CNKI data and scores. Synonyms is also constantly being optimized, and the new scores may be inconsistent with the picture above.
More comparison results.
Github associated user list
Test with py3, MacBook Pro.
python benchmark.py
++++++++++ OS Name and version ++++++++++
Platform: Darwin
Kernel: 16.7.0
Architecture: ('64bit', '')
++++++++++ CPU Cores ++++++++++
Cores: 4
CPU Load: 60
++++++++++ System Memory ++++++++++
meminfo 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
Heart of the machine
Online sharing record: Synonyms Chinese synonym toolkit @ 2018-02-07
Synonyms publishes certificate MIT. Data and procedures may be used in research and commercial products and must be cited and addressed, such as in any media, journals, magazines or blogs published.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
wikidata-corpus
word2vec principle derivation and code analysis
Not supported, see #5 for more information
Word2vec released by Google, this library is written in C language, has high memory usage efficiency and fast training speed. gensim can load model files output by word2vec.
See #64 for details
Hai Liang Wang
Hu Yingxi
This book was co-authored by Synonyms authors.
Quick book purchase link 
"Intelligent Question Answering and Deep Learning" This book is for students and software engineers who are preparing to get started with machine learning and natural language processing. It introduces many principles and algorithms in theory, and also provides many example programs to increase practicality. They are summarized in the sample program code library. These programs are mainly to help everyone understand the principles and algorithms. You are welcome to download and execute them. The address of the code base is:
https://github.com/l11x0m7/book-of-qna-code
Word2vec by Google
Wikimedia: Training corpus source
gensim: word2vec.py
SentenceSim: Similarity evaluation corpus
jieba: Chinese word segmentation
Chunsong Public License, version 1.0
https://bot.chatopera.com/
Chatopera cloud service is a one-stop cloud service for implementing chat robots, and is billed based on the number of interface calls. Chatopera Cloud Service is a software-as-a-service instance of the Chatopera bot platform. Based on cloud computing, Chatopera cloud service is a chatbot-as-a-service cloud service.
The Chatopera robot platform includes components such as knowledge base, multi-round dialogue, intent recognition and speech recognition, standardized chat robot development, and supports scenarios such as enterprise OA intelligent Q&A, HR intelligent Q&A, intelligent customer service and online marketing. Enterprise IT departments and business departments use Chatopera cloud services to quickly bring chatbots online!


