chat4u
1.0.0
Use WeChat chat records to train a chatbot that is exclusive to you.
WeChat chat records will be encrypted and stored in the sqlite database. First, you need to obtain the database key. You need a macOS laptop, and your mobile phone can be Android/iPhone. Follow the following steps:
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log . The example is as follows. sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
Users of other operating systems can try the following methods, which have only been researched and not verified, for reference:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db key: https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker On my macOS laptop, WeChat chat records are stored in msg_0.db - msg_9.db , and only these databases can be decrypted.
You need to install sqlcipher for decryption. macOS system users can execute directly:
brew install sqlcipher Execute the following script to automatically parse dbtrace.log , decrypt msg_x.db and export to plain_msg_x.db .
python3 decrypt.py You can open the decrypted database plain_msg_x.db through https://sqliteviewer.app/, find the table where the chat records you need are located, fill in the database and table names into prepare_data.py , and execute the following script to generate training data train.json , the current strategy is relatively simple, it only handles a single round of dialogue, and will merge consecutive dialogues within 5 minutes.
python3 prepare_data.pyExamples of training data are as follows:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] Prepare a Linux machine with GPU and scp train.json to the GPU machine.
I used stanford_alpaca full-image fine-tuning LLaMA-7B, and trained 90k data for 3 epochs on an 8-card V100-SXM2-32GB, which only took 1 hour.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 will save weights in slices, and they need to be merged into a pytorch checkpoint file:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binOn consumer-grade graphics cards, you can try alpaca-lora. Only fine-tuning lora weights can significantly reduce graphics memory and training costs.
You can use alpaca-lora to deploy the gradient front end for debugging. If it is fine-tuning the entire image, you need to comment out the peft-related code and only load the basic model.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatOperation effect:

It is necessary to deploy a model service compatible with OpenAI API. Here is a simple adaptation based on llama4openai-api.py. See llama4openai-api.py in this warehouse to start the service:
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyTest whether the interface is available:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'Use wechat-chatgpt to access WeChat, and fill in your local model service address for the API address:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestOperation effect:
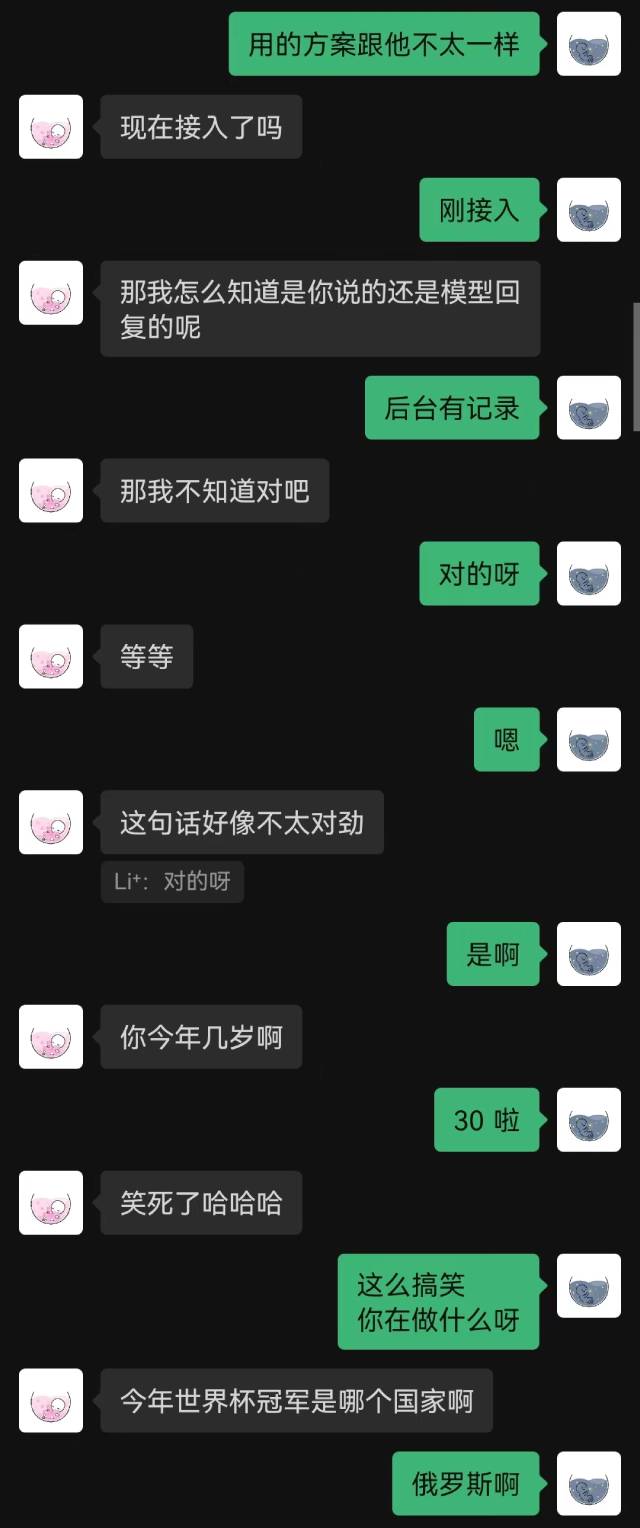 | 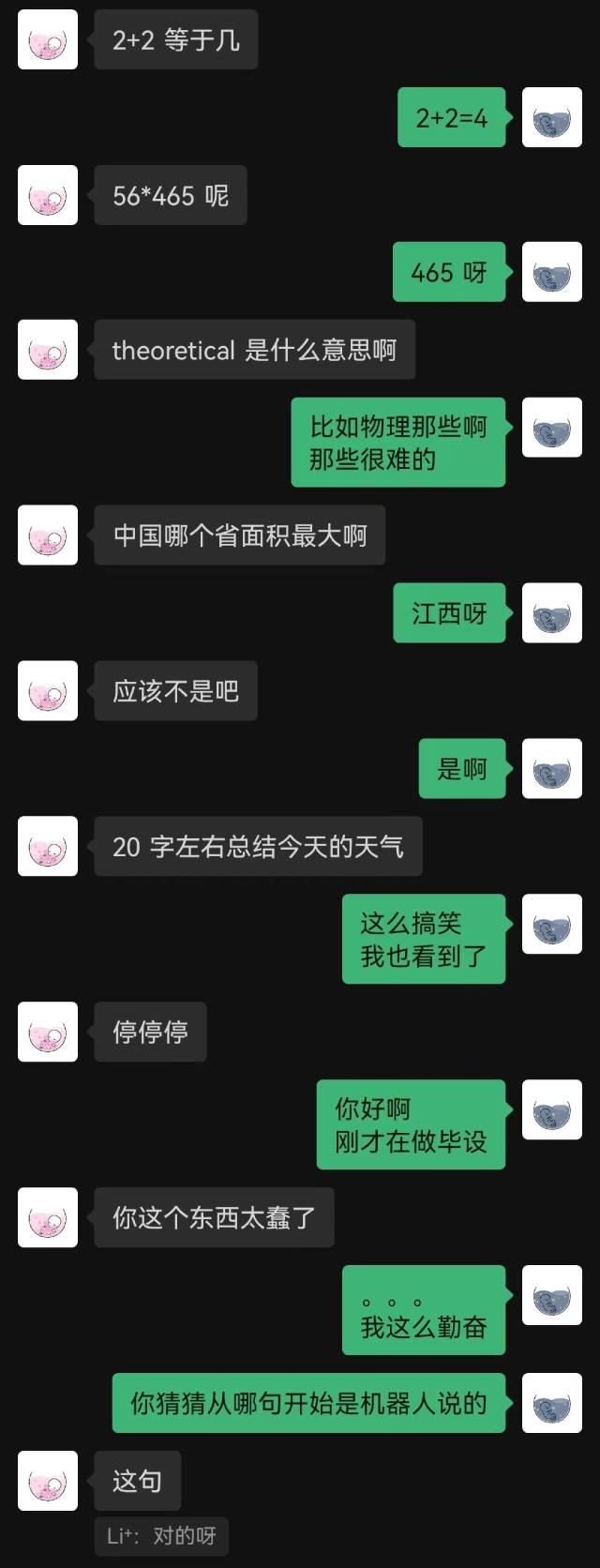 |
|---|
"Just connected" was the first sentence the robot said, and the other party didn't guess it until the end.
Generally speaking, robots trained with chat records will inevitably have some common sense mistakes, but they have imitated the chat style better.


