ThinkRAG
1.0.0
English | Simplified Chinese
The ThinkRAG large model retrieval enhancement generation system can be easily deployed on a laptop to realize intelligent question answering in a local knowledge base.
The system is built based on LlamaIndex and Streamlit, and has been optimized for domestic users in many areas such as model selection and text processing.
ThinkRAG is a large model application system developed for professionals, researchers, students and other knowledge workers. It can be used directly on laptops, and the knowledge base data is saved locally on the computer.
ThinkRAG has the following features:
In particular, ThinkRAG has also done a lot of customization and optimization for domestic users:
ThinkRAG can use all models supported by the LlamaIndex data frame. For model list information, please refer to the relevant documentation.
ThinkRAG is committed to creating an application system that is directly usable, useful and easy to use.
Therefore, we have made careful choices and trade-offs among various models, components and technologies.
First, using large models, ThinkRAG supports OpenAI API and all compatible LLM APIs, including domestic mainstream large model manufacturers, such as:
If you want to deploy large models locally, ThinkRAG chooses Ollama, which is simple and easy to use. We can download large models to run locally through Ollama.
Currently, Ollama supports the localized deployment of almost all mainstream large models, including Llama, Gemma, GLM, Mistral, Phi, Llava, etc. For details, please visit the Ollama official website below.
The system also uses embedding models and rearranged models, and supports most models from Hugging Face. Currently, ThinkRAG mainly uses BAAI’s BGE series models. Domestic users can visit the mirror website to learn and download.
After downloading the code from Github, use pip to install the required components.
pip3 install -r requirements.txtTo run the system offline, please first download Ollama from the official website. Then, use the Ollama command to download large models such as GLM, Gemma, and QWen.
Synchronously, download the embedding model (BAAI/bge-large-zh-v1.5) and reranking model (BAAI/bge-reranker-base) from Hugging Face to the localmodels directory.
For specific steps, please refer to the document in the docs directory: HowToDownloadModels.md
In order to obtain better performance, it is recommended to use the commercial large model LLM API with hundreds of billions of parameters.
First, obtain the API key from the LLM service provider and configure the following environment variables.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "You can skip this step and configure the API key through the application interface after the system is running.
If you choose to use one or more of the LLM APIs, please delete the service provider you no longer use in the config.py configuration file.
Of course, you can also add other service providers compatible with OpenAI API in the configuration file.
ThinkRAG runs in development mode by default. In this mode, the system uses local file storage and you do not need to install any database.
To switch to production mode, you can configure the environment variables as follows.
THINKRAG_ENV = productionIn production mode, the system uses the vector database Chroma and the key-value database Redis.
If you do not have Redis installed, it is recommended to install it through Docker or use an existing Redis instance. Please configure the parameter information of the Redis instance in the config.py file.
Now, you are ready to run ThinkRAG.
Please run the following command in the directory containing the app.py file.
streamlit run app.pyThe system will run and automatically open the following URL on the browser to display the application interface.
http://localhost:8501/
The first run may take a while. If the embedded model on Hugging Face is not downloaded in advance, the system will automatically download the model and you will need to wait longer.
ThinkRAG supports the configuration and selection of large models in the user interface, including the Base URL and API key of the large model LLM API, and you can select the specific model to use, such as glm-4 of ThinkRAG.
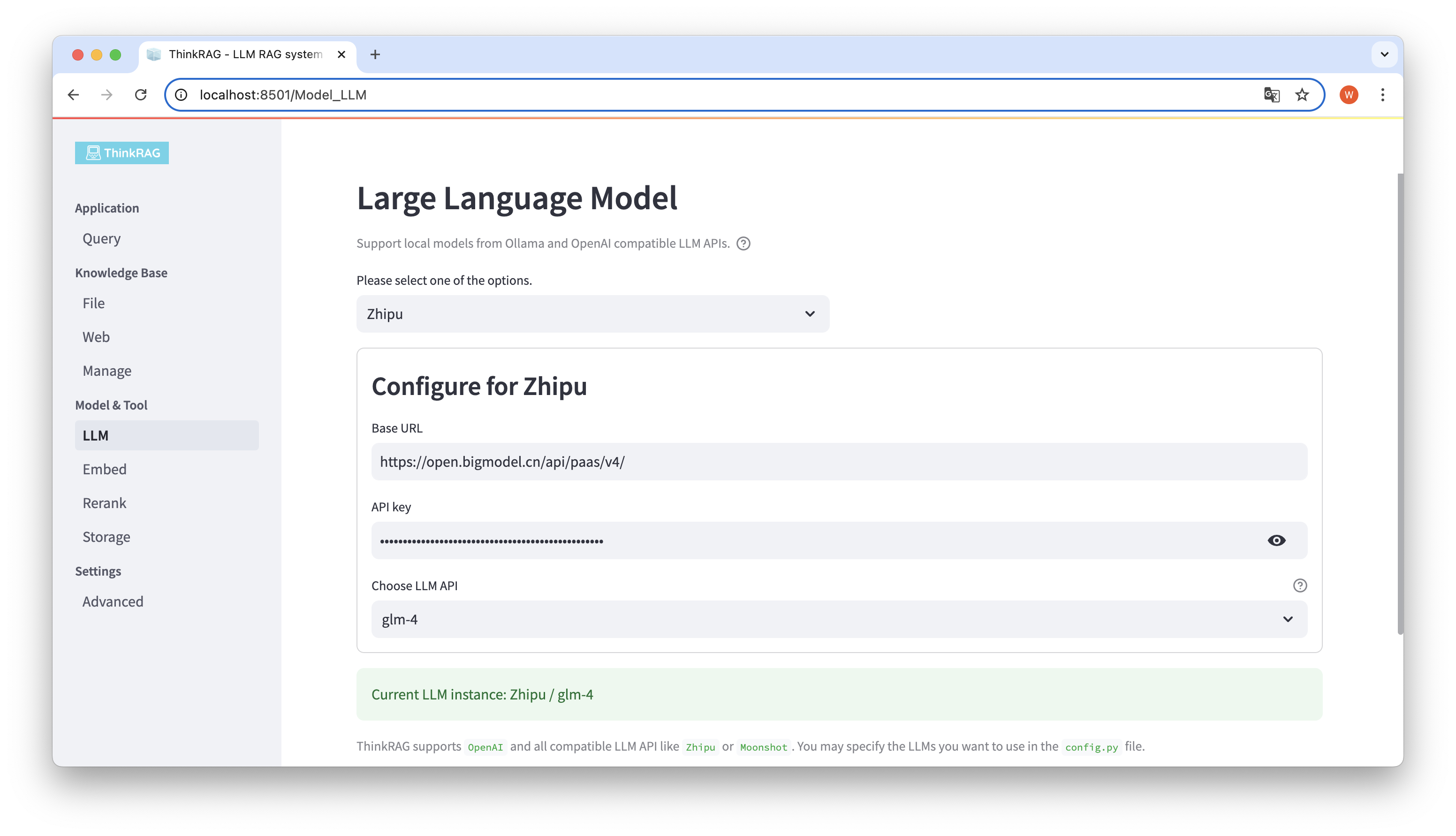
The system will automatically detect whether the API and key are available. If available, the currently selected large model instance will be displayed in green text at the bottom.
Similarly, the system can automatically obtain the models downloaded by Ollama, and the user can select the desired model on the user interface.
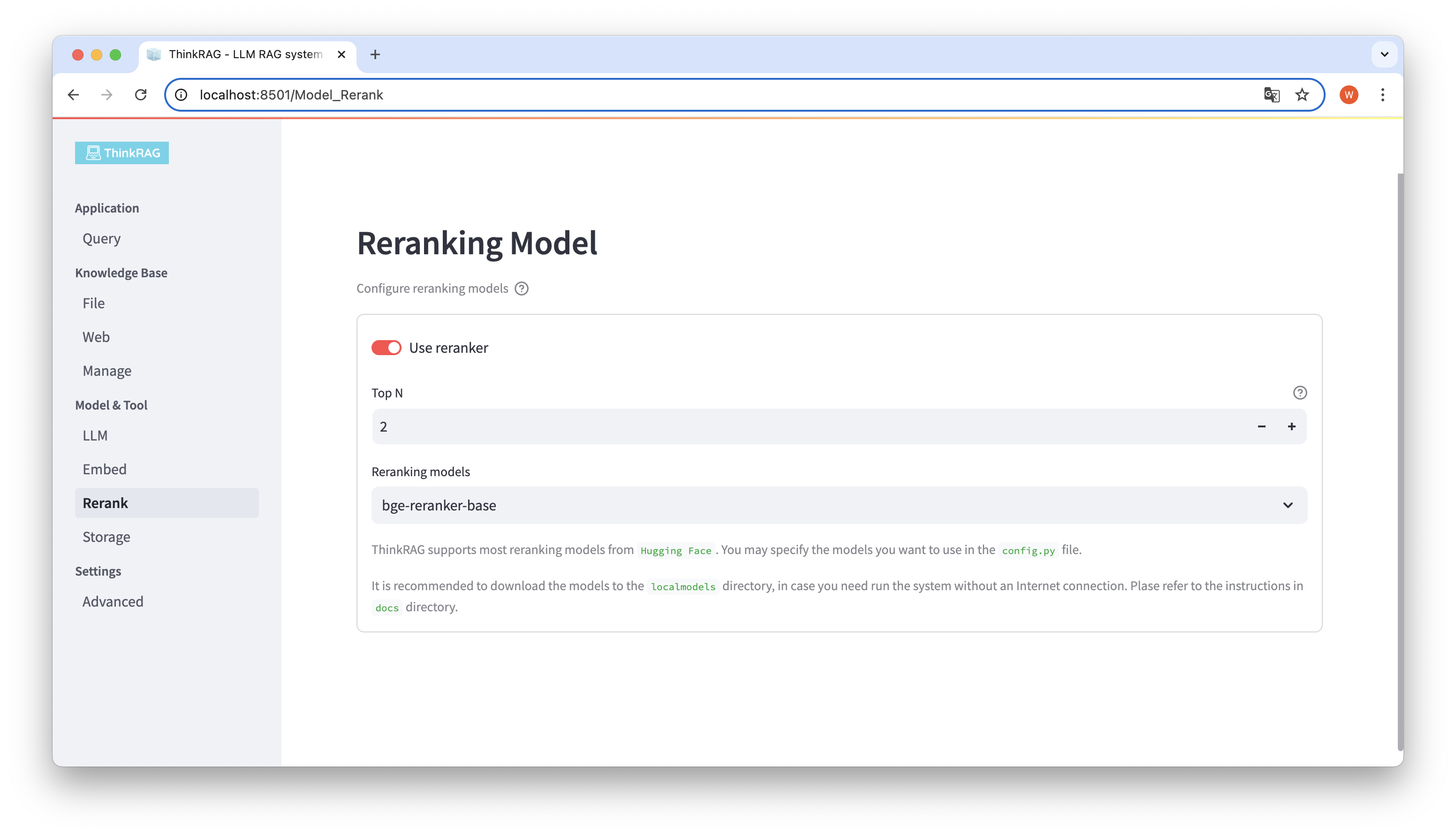
If you have downloaded the embedded model and rearranged model to the local localmodels directory. On the user interface, you can switch the selected model and set the parameters of the rearranged model, such as Top N.
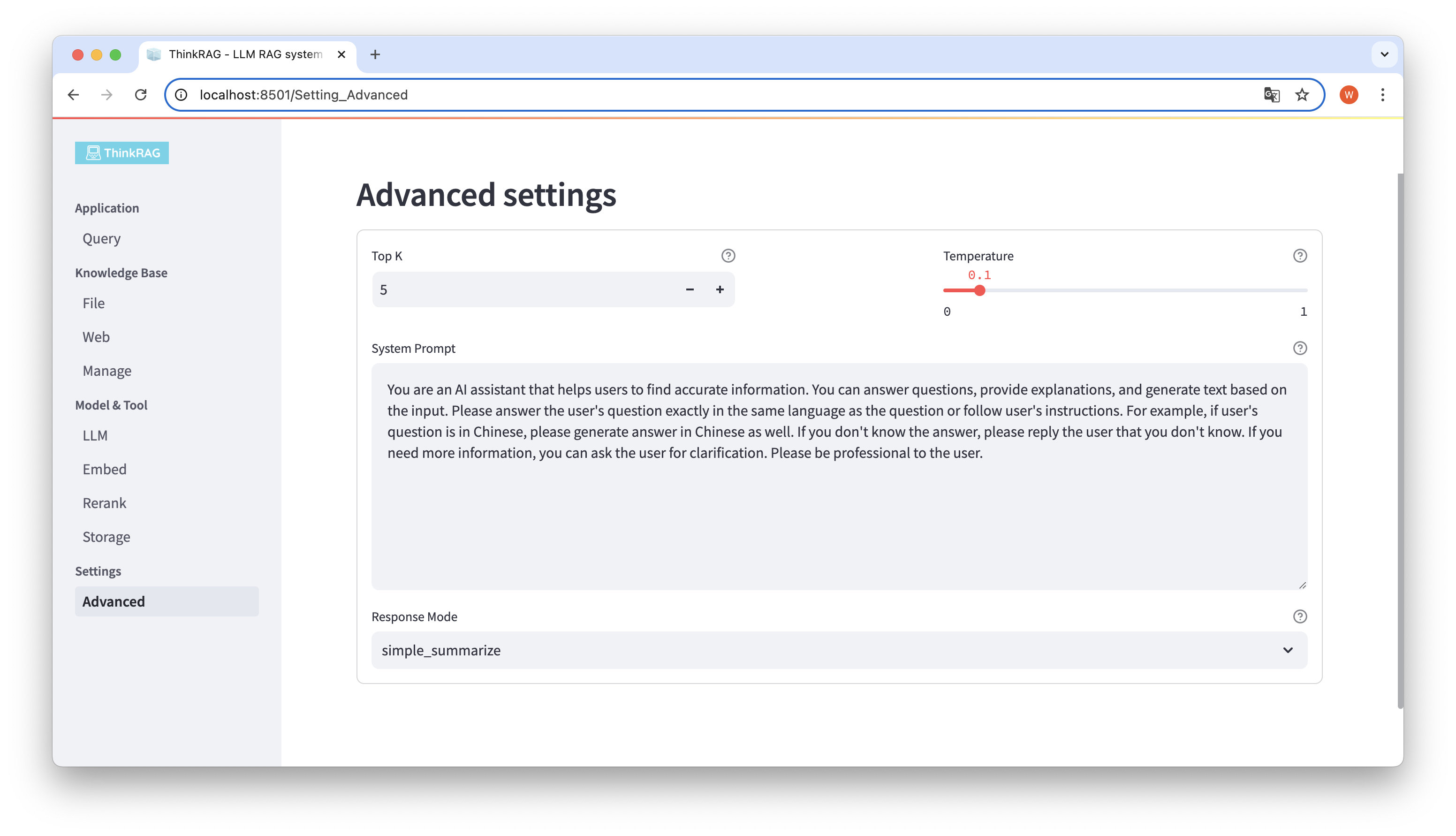
In the left navigation bar, click Advanced Settings (Settings-Advanced). You can also set the following parameters:
By using different parameters, we can compare large model outputs and find the most effective combination of parameters.
ThinkRAG supports uploading various files such as PDF, DOCX, PPTX, etc., and also supports uploading web page URLs.
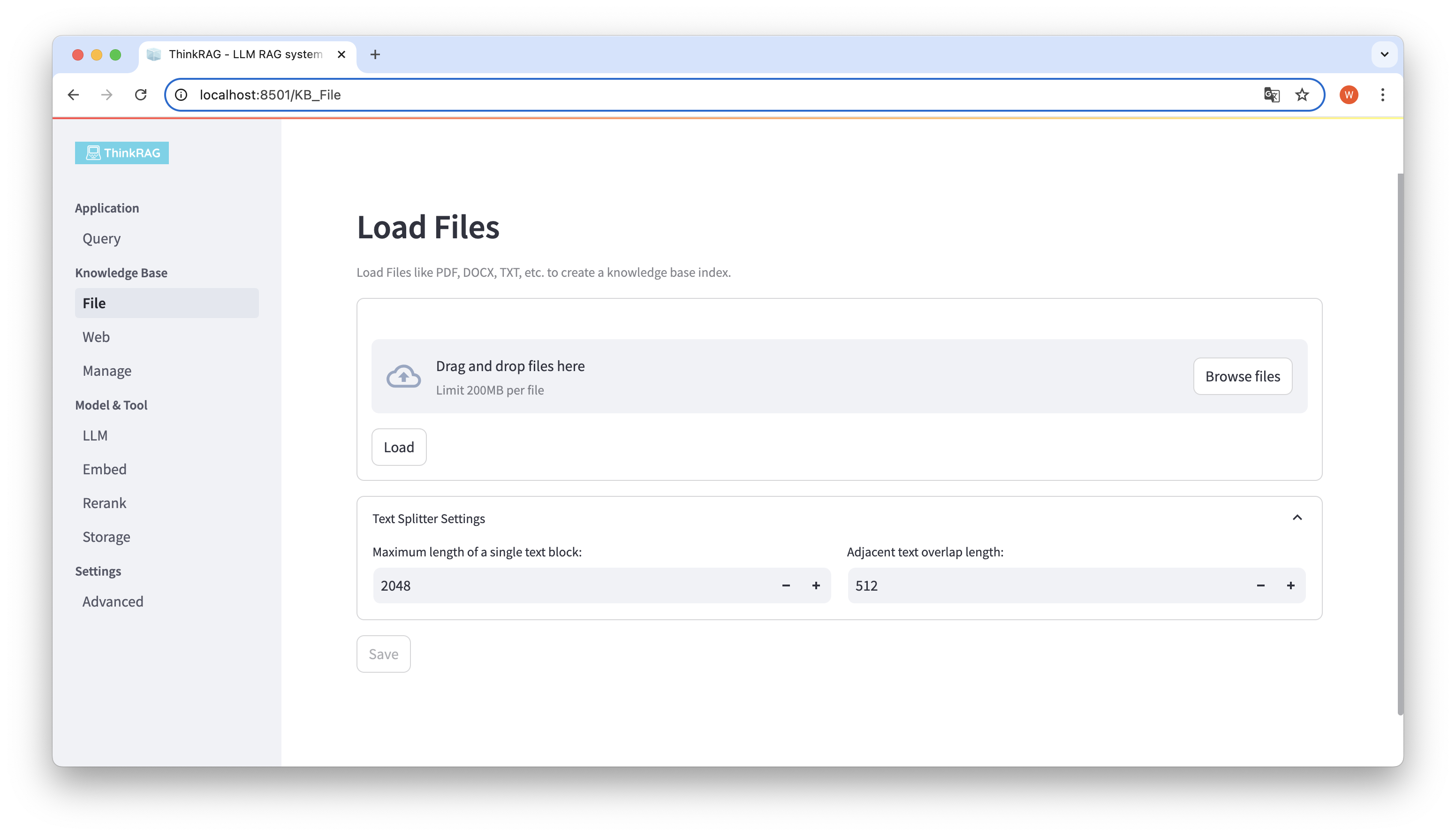
Click the Browse files button, select the file on your computer, and then click the Load button to load. All loaded files will be listed.
Then, click the Save button, and the system will process the file, including text segmentation and embedding, and save it to the knowledge base.
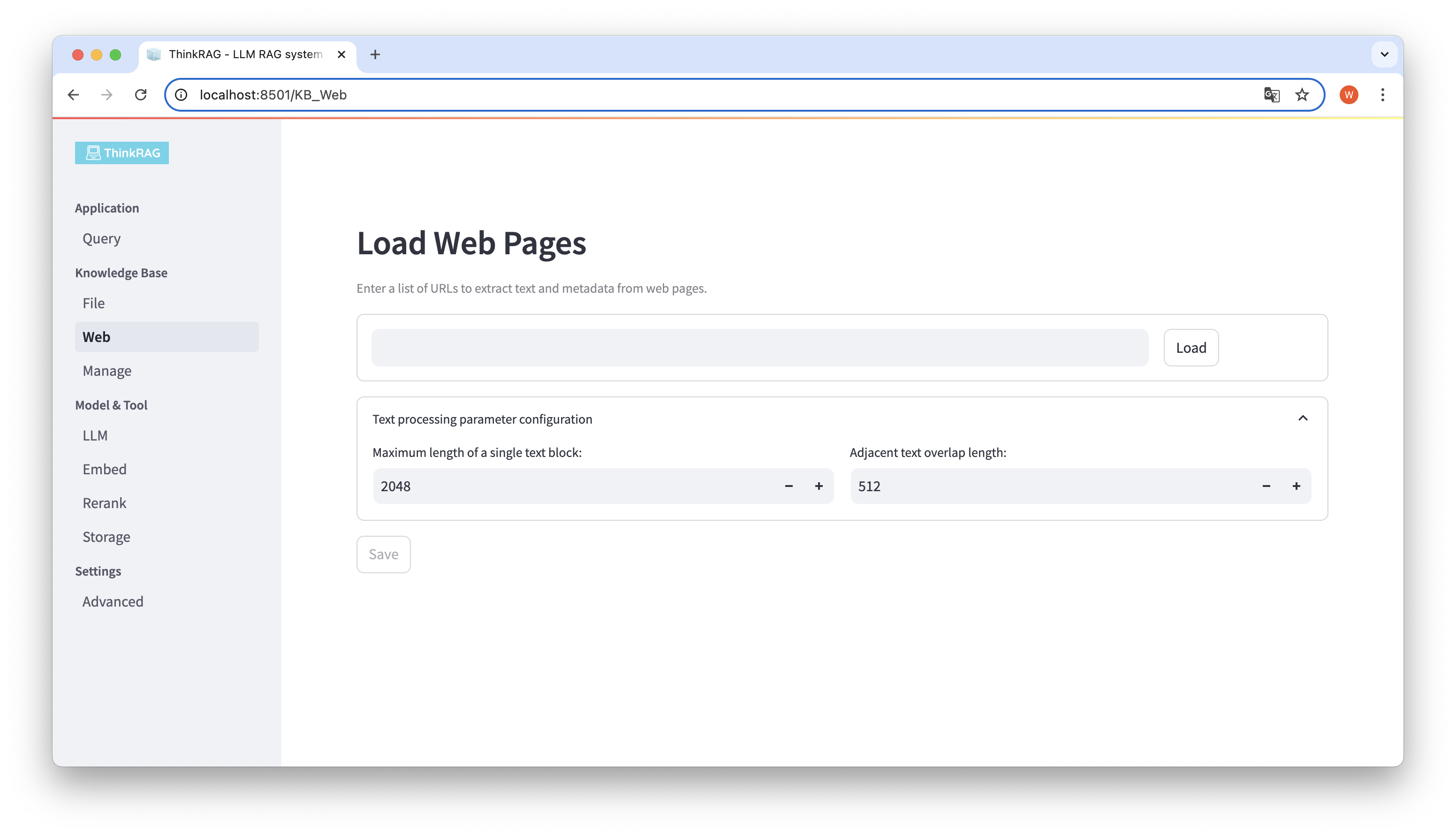
Similarly, you can enter or paste the web page URL, obtain the web page information, and save it to the knowledge base after processing.
The system supports the management of knowledge base.
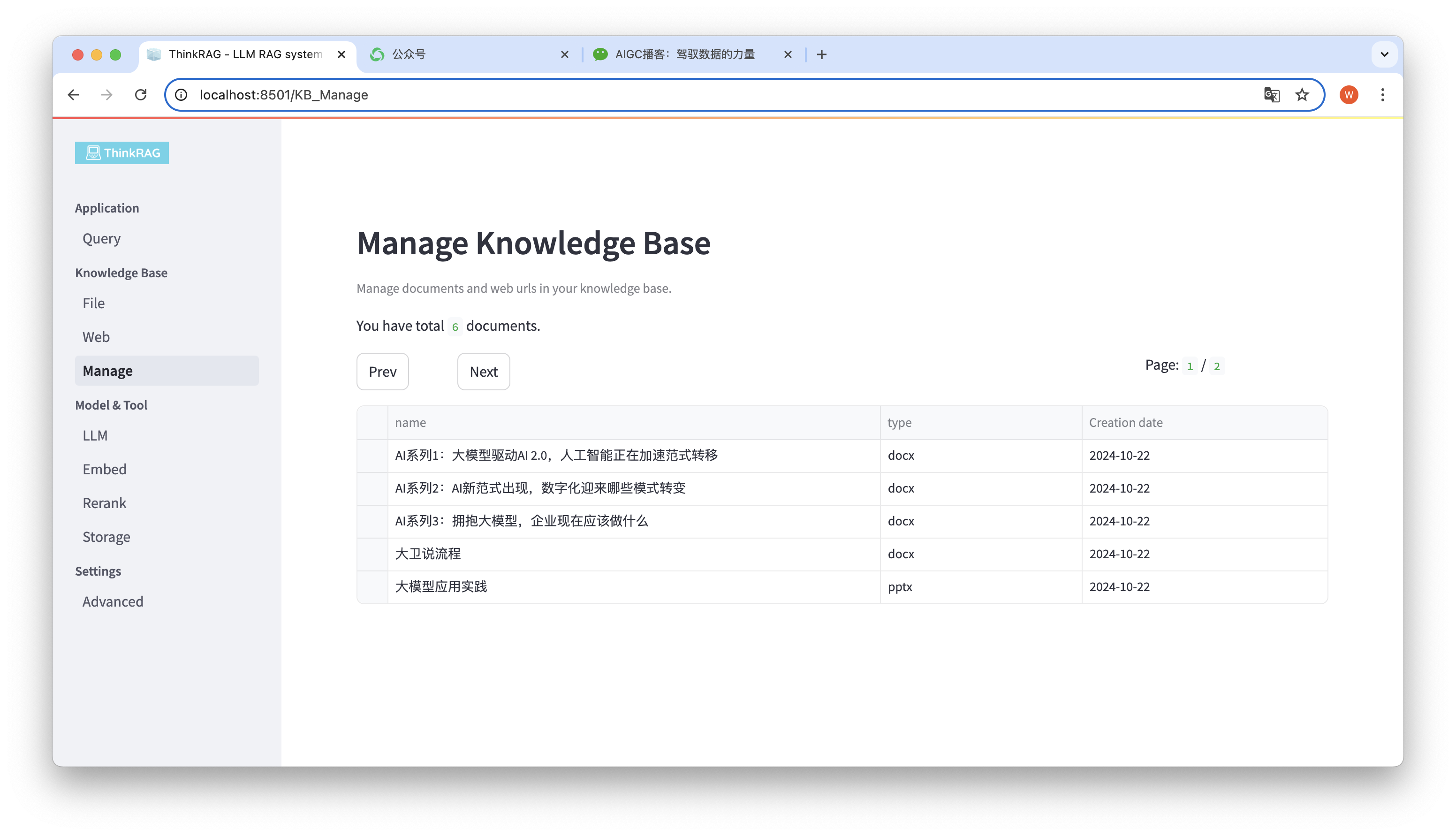
As shown in the figure above, ThinkRAG can list all documents in the knowledge base in pages.
Select the documents to be deleted, and the Delete selected documents button will appear. Click this button to delete the documents from the knowledge base.
In the left navigation bar, click Query, and the intelligent question and answer page will appear.
After entering the question, the system will search the knowledge base and provide an answer. During this process, the system will use technologies such as hybrid retrieval and rearrangement to obtain accurate content from the knowledge base.
For example, we have uploaded a Word document in the knowledge base: "David Says Process.docx".
Now enter the question: "What are three characteristics of a process?"
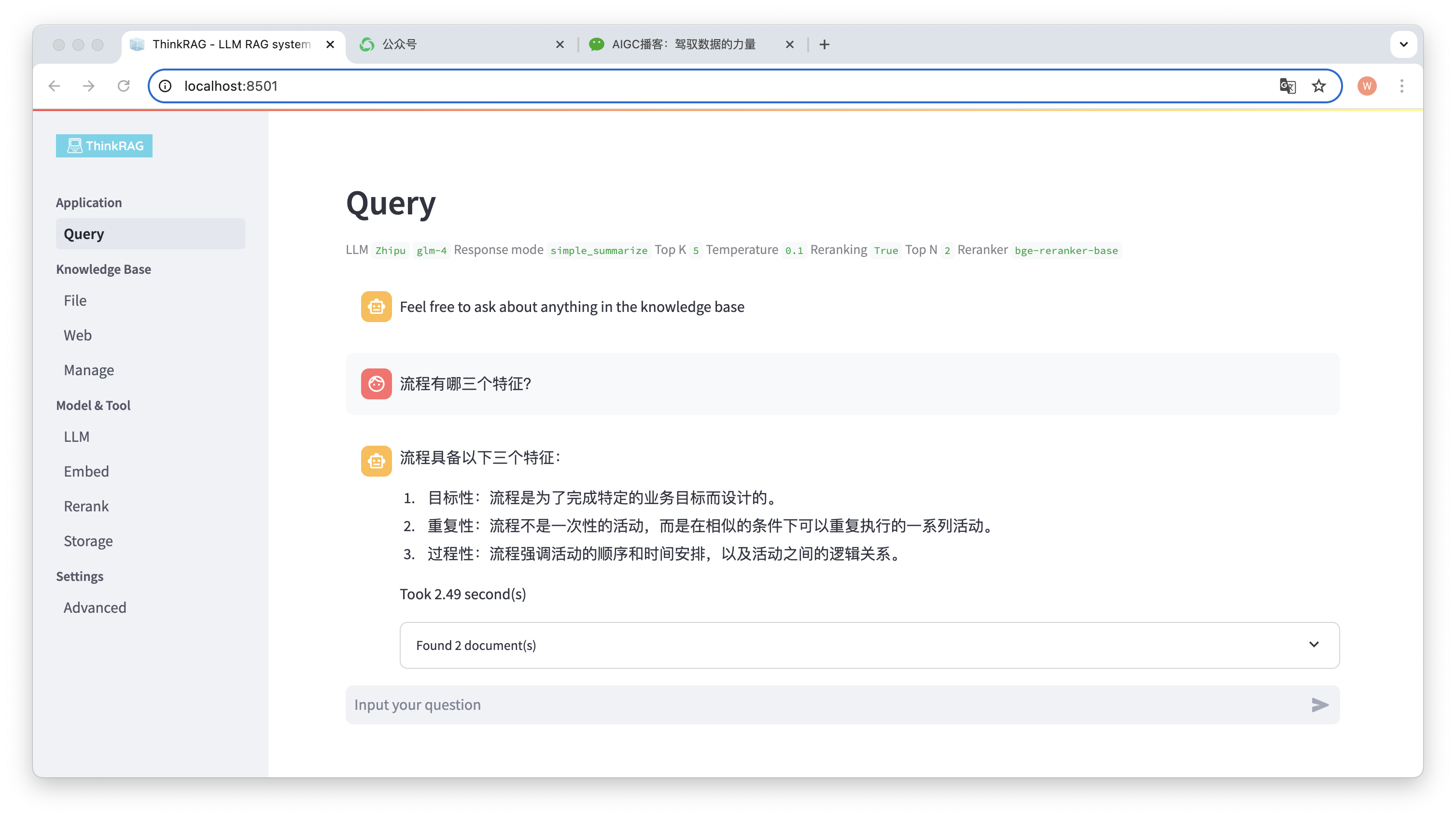
As shown in the figure, the system took 2.49 seconds to give an accurate answer: the process is targeted, repetitive and procedural. At the same time, the system also provides 2 related documents retrieved from the knowledge base.
It can be seen that ThinkRAG completely and effectively implements the function of enhanced generation of large model retrieval based on local knowledge base.
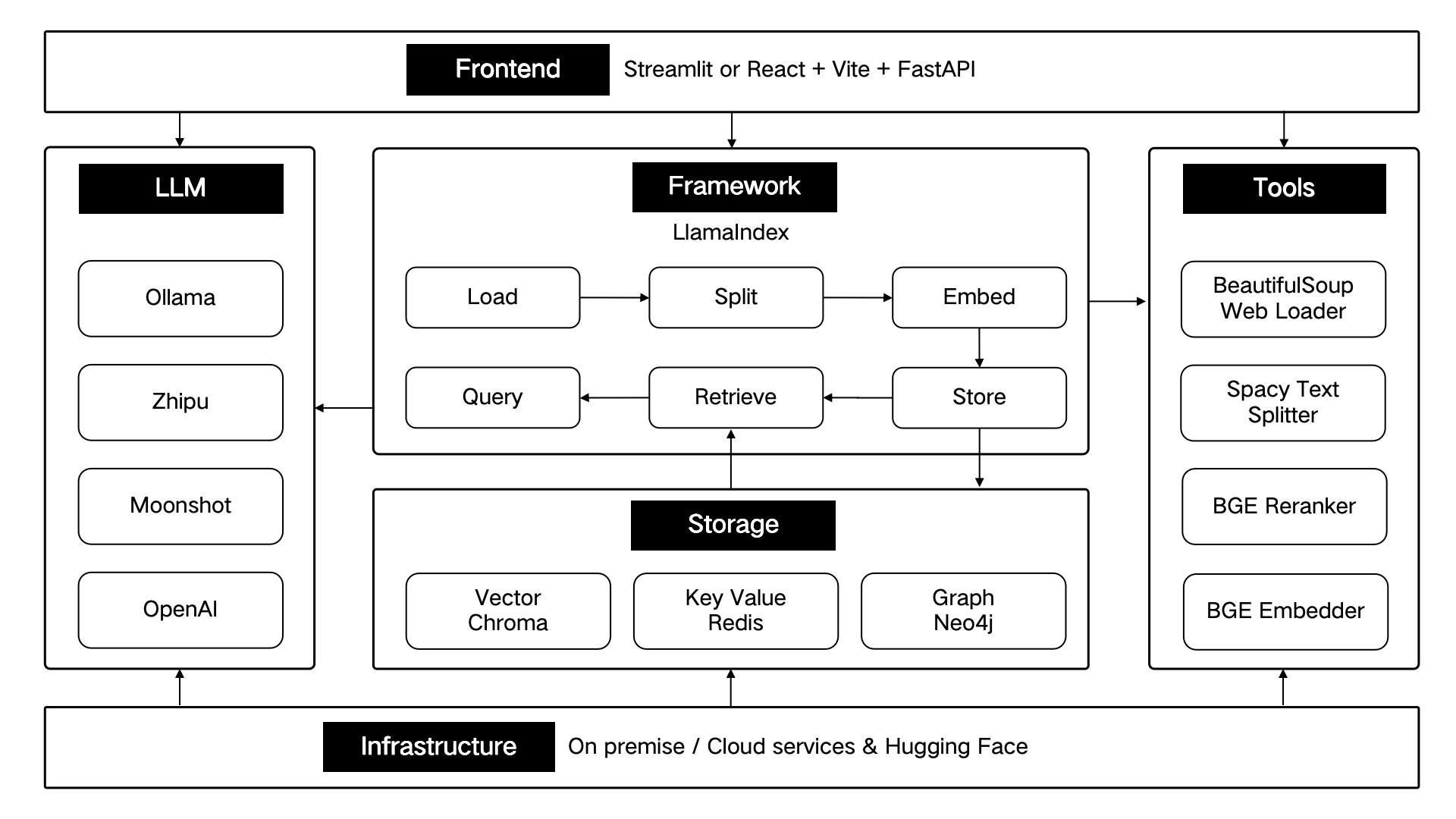
ThinkRAG is developed using the LlamaIndex data framework and uses Streamlit for the front end. The development mode and production mode of the system use different technical components respectively, as shown in the following table:
| development mode | production mode | |
|---|---|---|
| RAG framework | LlamaIndex | LlamaIndex |
| front-end framework | Streamlit | Streamlit |
| embedded model | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| rearrange model | BAAI/bge-reranker-base | BAAI/bge-reranker-large |
| text splitter | SentenceSplitter | SpacyTextSplitter |
| Conversation storage | SimpleChatStore | Redis |
| Document storage | SimpleDocumentStore | Redis |
| Index storage | SimpleIndexStore | Redis |
| vector storage | SimpleVectorStore | LanceDB |
These technical components are architecturally designed according to six parts: front-end, framework, large model, tools, storage, and infrastructure.
As shown below:
ThinkRAG will continue to optimize core functions and continue to improve the efficiency and accuracy of retrieval, mainly including:
At the same time, we will further improve the application architecture and enhance user experience, mainly including:
You are welcome to join the ThinkRAG open source project and work together to create AI products that users love!
ThinkRAG uses the MIT license.


