lance
v0.20.0

Modern columnar data format for ML. Convert from Parquet in 2-lines of code for 100x faster random access, a vector index, data versioning, and more.
Compatible with pandas, DuckDB, Polars, and pyarrow with more integrations on the way.
Documentation • Blog • Discord • Twitter
Lance is a modern columnar data format that is optimized for ML workflows and datasets. Lance is perfect for:
The key features of Lance include:
High-performance random access: 100x faster than Parquet without sacrificing scan performance.
Vector search: find nearest neighbors in milliseconds and combine OLAP-queries with vector search.
Zero-copy, automatic versioning: manage versions of your data without needing extra infrastructure.
Ecosystem integrations: Apache Arrow, Pandas, Polars, DuckDB and more on the way.
Tip
Lance is in active development and we welcome contributions. Please see our contributing guide for more information.
Installation
pip install pylanceTo install a preview release:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceTip
Preview releases are released more often than full releases and contain the latest features and bug fixes. They receive the same level of testing as full releases. We guarantee they will remain published and available for download for at least 6 months. When you want to pin to a specific version, prefer a stable release.
Converting to Lance
import lance
import pandas as pd
import pyarrow as pa
import pyarrow.dataset
df = pd.DataFrame({"a": [5], "b": [10]})
uri = "/tmp/test.parquet"
tbl = pa.Table.from_pandas(df)
pa.dataset.write_dataset(tbl, uri, format='parquet')
parquet = pa.dataset.dataset(uri, format='parquet')
lance.write_dataset(parquet, "/tmp/test.lance")Reading Lance data
dataset = lance.dataset("/tmp/test.lance")
assert isinstance(dataset, pa.dataset.Dataset)Pandas
df = dataset.to_table().to_pandas()
dfDuckDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb.query("SELECT * FROM dataset LIMIT 10").to_df()Vector search
Download the sift1m subset
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzConvert it to Lance
import lance
from lance.vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open("sift/sift_base.fvecs", mode="rb") as fobj:
buf = fobj.read()
data = np.array(struct.unpack("<128000000f", buf[4 : 4 + 4 * nvecs * ndims])).reshape((nvecs, ndims))
dd = dict(zip(range(nvecs), data))
table = vec_to_table(dd)
uri = "vec_data.lance"
sift1m = lance.write_dataset(table, uri, max_rows_per_group=8192, max_rows_per_file=1024*1024)Build the index
sift1m.create_index("vector",
index_type="IVF_PQ",
num_partitions=256, # IVF
num_sub_vectors=16) # PQSearch the dataset
# Get top 10 similar vectors
import duckdb
dataset = lance.dataset(uri)
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb.query("SELECT vector FROM dataset USING SAMPLE 100").to_df()
query_vectors = np.array([np.array(x) for x in sample.vector])
# Get nearest neighbors for all of them
rs = [dataset.to_table(nearest={"column": "vector", "k": 10, "q": q})
for q in query_vectors]| Directory | Description |
|---|---|
| rust | Core Rust implementation |
| python | Python bindings (pyo3) |
| docs | Documentation source |
Here we will highlight a few aspects of Lance’s design. For more details, see the full Lance design document.
Vector index: Vector index for similarity search over embedding space.
Support both CPUs (x86_64 and arm) and GPU (Nvidia (cuda) and Apple Silicon (mps)).
Encodings: To achieve both fast columnar scan and sub-linear point queries, Lance uses custom encodings and layouts.
Nested fields: Lance stores each subfield as a separate column to support efficient filters like “find images where detected objects include cats”.
Versioning: A Manifest can be used to record snapshots. Currently we support creating new versions automatically via appends, overwrites, and index creation .
Fast updates (ROADMAP): Updates will be supported via write-ahead logs.
Rich secondary indices (ROADMAP):
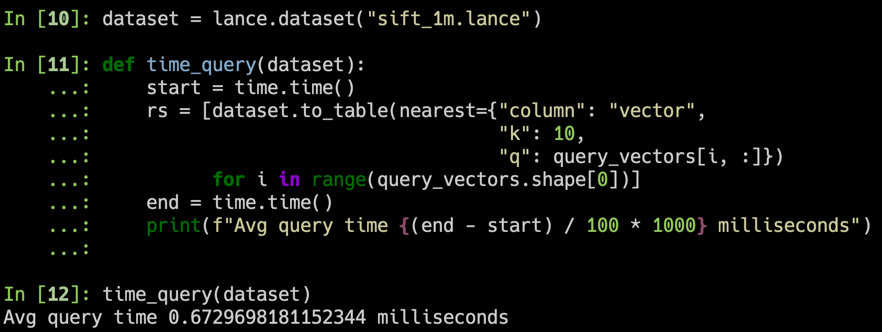
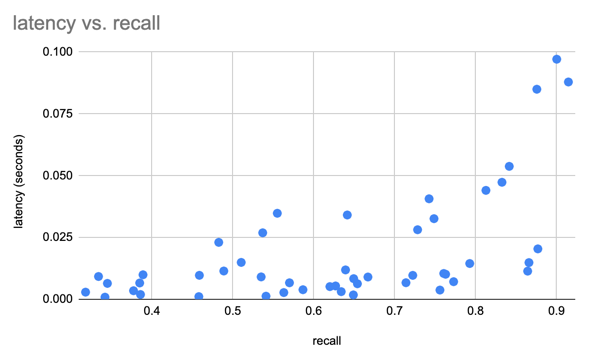
We used the SIFT dataset to benchmark our results with 1M vectors of 128D
We create a Lance dataset using the Oxford Pet dataset to do some preliminary performance testing of Lance as compared to Parquet and raw image/XMLs. For analytics queries, Lance is 50-100x better than reading the raw metadata. For batched random access, Lance is 100x better than both parquet and raw files.

The machine learning development cycle involves the steps:
graph LR
A[Collection] --> B[Exploration];
B --> C[Analytics];
C --> D[Feature Engineer];
D --> E[Training];
E --> F[Evaluation];
F --> C;
E --> G[Deployment];
G --> H[Monitoring];
H --> A;
People use different data representations to varying stages for the performance or limited by the tooling available. Academia mainly uses XML / JSON for annotations and zipped images/sensors data for deep learning, which is difficult to integrated into data infrastructure and slow to train over cloud storage. While industry uses data lakes (Parquet-based techniques, i.e., Delta Lake, Iceberg) or data warehouses (AWS Redshift or Google BigQuery) to collect and analyze data, they have to convert the data into training-friendly formats, such as Rikai/Petastorm or TFRecord. Multiple single-purpose data transforms, as well as syncing copies between cloud storage to local training instances have become a common practice.
While each of the existing data formats excels at the workload it was originally designed for, we need a new data format tailored for multistage ML development cycles to reduce and data silos.
A comparison of different data formats in each stage of ML development cycle.
| Lance | Parquet & ORC | JSON & XML | TFRecord | Database | Warehouse | |
|---|---|---|---|---|---|---|
| Analytics | Fast | Fast | Slow | Slow | Decent | Fast |
| Feature Engineering | Fast | Fast | Decent | Slow | Decent | Good |
| Training | Fast | Decent | Slow | Fast | N/A | N/A |
| Exploration | Fast | Slow | Fast | Slow | Fast | Decent |
| Infra Support | Rich | Rich | Decent | Limited | Rich | Rich |
Lance is currently used in production by:


