local LLM with RAG
1.0.0

This project is an experimental sandbox for testing out ideas related to running local Large Language Models (LLMs) with Ollama to perform Retrieval-Augmented Generation (RAG) for answering questions based on sample PDFs. In this project, we are also using Ollama to create embeddings with the nomic-embed-text to use with Chroma. Please note that the embeddings are reloaded each time the application runs, which is not efficient and is only done here for testing purposes.
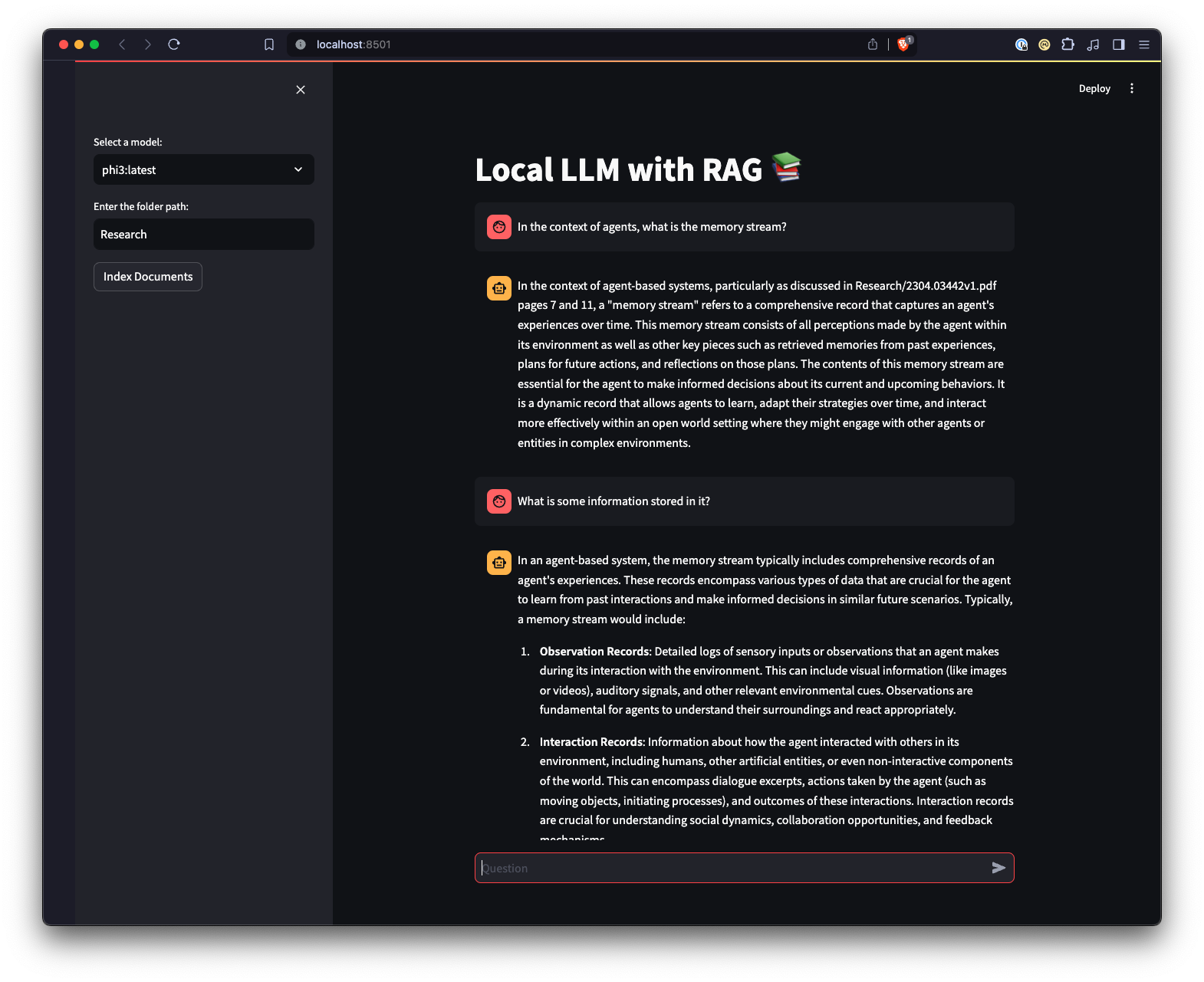
There is also a web UI created using Streamlit to provide a different way to interact with Ollama.
python3 -m venv .venv.source .venv/bin/activate on Unix or MacOS, or ..venvScriptsactivate on Windows.pip install -r requirements.txt.Note: The first time you run the project, it will download the necessary models from Ollama for the LLM and embeddings. This is a one-time setup process and may take some time depending on your internet connection.
python app.py -m <model_name> -p <path_to_documents> to specify a model and the path to documents. If no model is specified, it defaults to mistral. If no path is specified, it defaults to Research located in the repository for example purposes.-e <embedding_model_name>. If not specified, it defaults to nomic-embed-text.This will load the PDFs and Markdown files, generate embeddings, query the collection, and answer the question defined in app.py.
ui.py script.streamlit run ui.py in your terminal.This will start a local web server and open a new tab in your default web browser where you can interact with the application. The Streamlit UI allows you to select models, select a folder, providing an easier and more intuitive way to interact with the RAG chatbot system compared to the command-line interface. The application will handle the loading of documents, generating embeddings, querying the collection, and displaying the results interactively.


