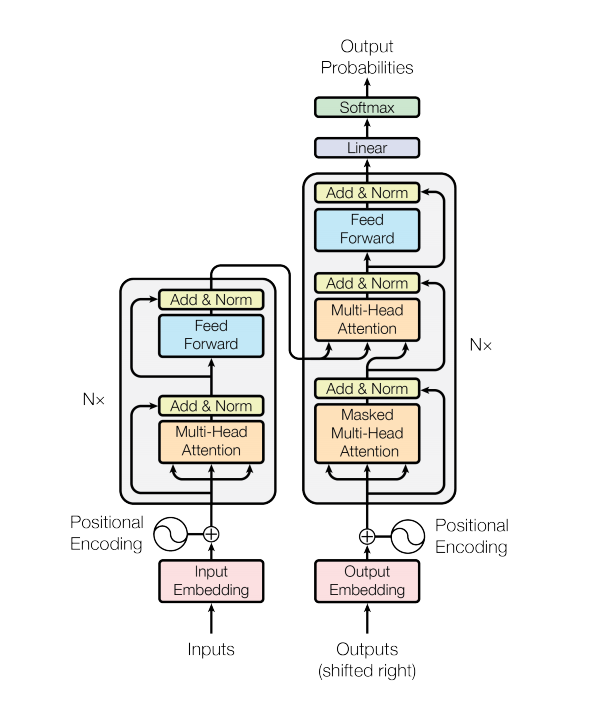
Transformer in generating dialogue
1.0.0
The code is an implementation of Paper Attention is all you need working for dialogue generation tasks like: Chatbot、 Text Generation and so on.
Thanks to every friends who have raised issues and helped solve them. Your contribution is very important for the improvement of this project. Due to the limited support of the 'static graph mode' in coding, we decided to move the features to 2.0.0-beta1 version. However if you worry about the problems from docker building and service creation with version issues, we still keep an old version of the code written by eager mode using tensorflow 1.12.x version to refer.
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
As we all know the Translation System can be used in implementing conversational model just by replacing the paris of two different sentences to questions and answers. After all, the basic conversation model named "Sequence-to-Sequence" is develped from translation system. Therefore, why we not to improve the efficiency of conversation model in generating dialogues?
With the development of BERT-based models, more and more nlp tasks are refreshed constantly. However, the language model is not contained in BERT's open source tasks. There is no doubt that on this way we still have a long way to go.
A transformer model handles variable-sized input using stacks of self-attention layers instead of RNNs or CNNs. This general architecture has a number of advantages and special ticks. Now let's take them out:
In the newest version of our code, we complete the details described in paper.
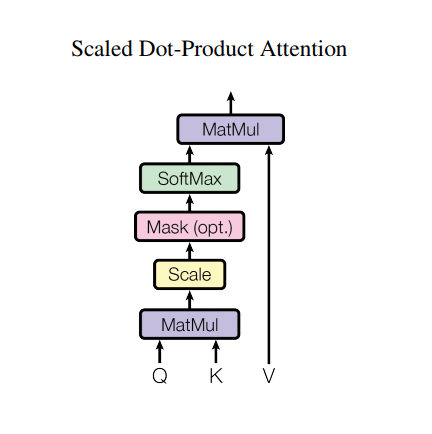
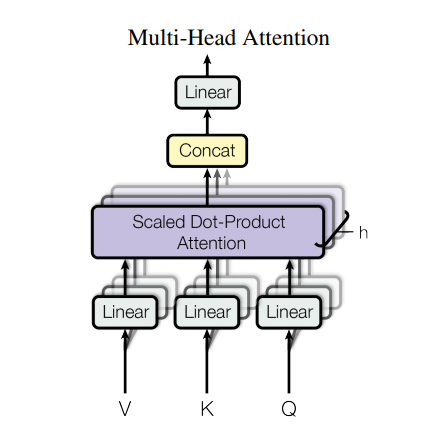
However, such a strong architecture still have some downsides:
data/ folder.params.py if you want.make_dic.py to generate vocabulary files to a new folder named dictionary.train.py to build the model. Checkpoint will be stored in checkpoint folder while the tensorflow event files can be found in logdir.eval.py to evaluate the result with testing data. Result will be stored in Results folder.GPU to speed up training processing, please set up your device in the code.(It support multi-workers training)- Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 明 - 我 愛 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: 守 得 住
If you try to use AutoGraph to speed up your training process, please make sure the datasets is padded to a fixed length. Because of the graph rebuilding operation will be activated during training, which may affect the performance. Our code only ensures the performance of version 2.0, and the lower ones can try to refer it.
Thanks for Transformer and Tensorflow