Okapi
1.0.0
Okapi
Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback
This is the repo for the Okapi framework that introduces resources and models for instruction tuning for large language models (LLMs) with reinforcement learning from human feedback (RLHF) in multiple languages. Our framework supports 26 languages, including 8 high-resource languages, 11 medium-resource languages, and 7 low-resource languages.
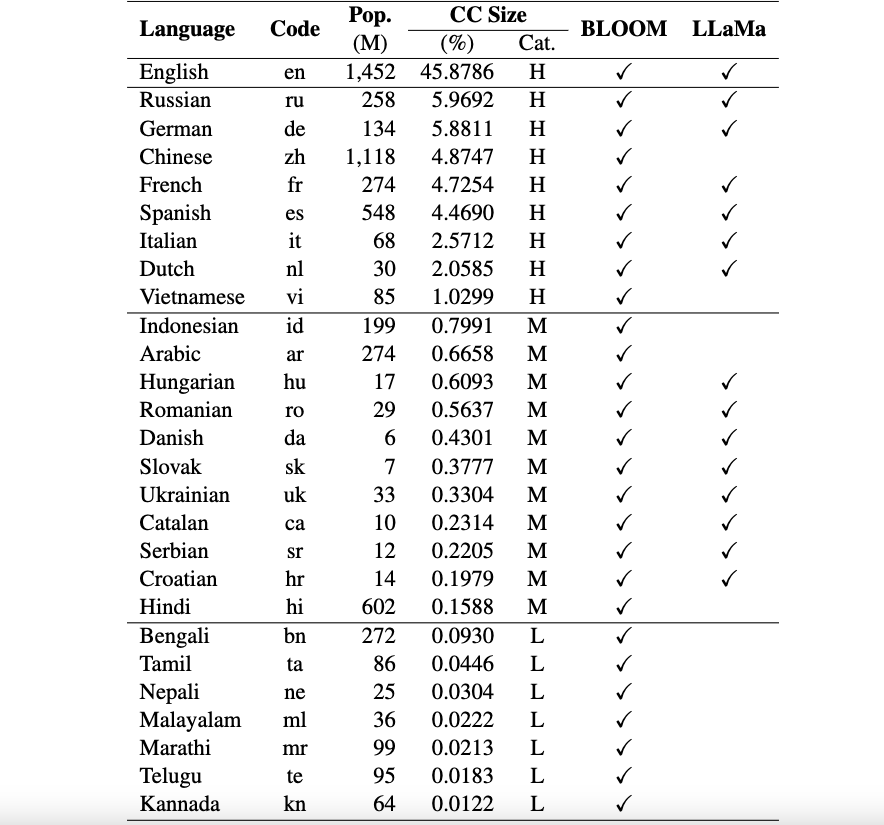
Okapi Resources: We provide resources to perform instruction tuning with RLHF for 26 languages, including ChatGPT prompts, multilingual instruction datasets and multilingual response ranking data.
Okapi Models: We provide RLHF-based instruction-tuned LLMs for 26 languages on Okapi dataset. Our models include both BLOOM-based and LLaMa-based versions. We also provide scripts to interact with our models and fine-tune LLMs with our resources.
Multilingual Evaluation Benchmark Datasets: We provide three benchmark datasets for evaluating Multilingual Large Language Models (LLMs) for 26 languages. You can access the full datasets and evaluation scripts: here.
Usage and License Notices: Okapi is intended and licensed for research use only. The datasets are CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Our technical paper with evaluation results can be found here.
We perform a comprehensive data collection process to prepare necessary data for our multilingual framework Okapi in four major steps:
To download the entire dataset, you can use the following script:
bash scripts/download.shIf you only need the data for a specific language, you can specify the language code as an argument to the script:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viAfter downloading, our released data can be found in the datasets directory. It includes:
multilingual-alpaca-52k: The translated data for 52K English instructions in Alpaca into 26 languages.
multilingual-ranking-data-42k: The multilingual response ranking data for 26 languages. For each language, we provide 42K instructions; each of them has 4 ranked responses. This data can be used to train reward models for 26 languages.
multilingual-rl-tuning-64k: The multilingual instruction data for RLHF. We provide 62K instructions for each of the 26 languages.
Using our Okapi datasets and the RLHF-based instruction-tuning technique, we introduce multilingual fine-tuned LLMs for 26 languages, built upon the 7B versions of LLaMA and BLOOM. The models can be obtained from HuggingFace here.
Okapi supports interactive chats with the multilingual instruction-tuned LLMs in 26 languages. Following the following steps for the chats:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline(model_path, gpu=True)
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p.generate(instruction=instruction, prompt_input=prompt_input)
print(response)We also provide scripts to fine-tune LLMs with our instruction data using RLHF, covering three major steps: supervised fine-tuning, reward modeling, and fine-tuning with RLHF. Use the following steps to fine-tune LLMs:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]If you use the data, model or code in this repository, please cite:
@article{dac2023okapi,
title={Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback},
author={Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu},
journal={arXiv e-prints},
pages={arXiv--2307},
year={2023}
}

