turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) is an open source solution (https://github.com/openturing), which has Semantic Navigation and Chat bot as its main features. You can choose from several NLPs to enrich the data. All content is indexed in Solr as search engine.
Technical documentation on Turing ES is available at https://openviglet.github.io/docs/turing/.
To run Turing ES, just execute the following lines:
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# New Turing ES UI using Angular 18 and Primer CSS.cd turing-ui## Loginng serve welcome## Consoleng serve console## Searchng serve sn## Chat botng serve converse
You can start the Turing ES using MariaDB, Solr and Nginx.
docker-compose up
Administration Console: http://localhost:2700. (admin/admin)
Semantic Navigation Sample: http://localhost:2700/sn/Sample.
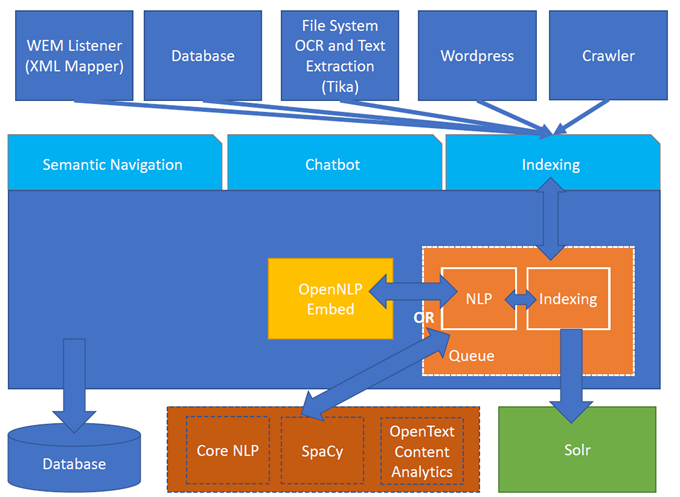
Figure 1. Turing ES Architecture
Turing support the followings providers:
Apache OpenNLP is a machine learning based toolkit for the processing of natural language text.
Website: https://opennlp.apache.org/
It transforms data into insights for better decision-making and information management while freeing up resources and time.
Website: https://www.opentext.com/
CoreNLP is your one-stop shop for natural language processing in Java! CoreNLP enables users to derive linguistic annotations for text, including token and sentence boundaries, parts of speech, named entities, numeric and time values, dependency and constituency parses, coreference, sentiment, quote attributions, and relations. CoreNLP currently supports 6 languages: Arabic, Chinese, English, French, German, and Spanish.
Website: https://stanfordnlp.github.io/CoreNLP/,
It is a free open-source library for Natural Language Processing in Python. It features NER, POS tagging, dependency parsing, word vectors and more.
Website: https://spacy.io
Polyglot is a natural language pipeline that supports massive multilingual applications.
Website: https://polyglot.readthedocs.io
It can read PDFs and Documents and convert to plain text, and also it uses OCR to detect text in images and images into documents.
Semantic Navigation uses Connectors to index the content from many sources.
Plugin for Apache Nutch to index content using crawler.
Learn more at https://docs.viglet.com/turing/connectors/#nutch
Command line that uses the same concept as sqoop (https://sqoop.apache.org/), to create complex queries and map attributes to index based on the result.
Learn more at https://docs.viglet.com/turing/connectors/#database
Command line to index files, extracting text from files such as Word, Excel, PDF, including images, through OCR.
Learn more at https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener to publish content to Viglet Turing.
Learn more at https://docs.viglet.com/turing/connectors/#wem
WordPress plugin that allows you to index posts.
Learn more at https://docs.viglet.com/turing/connectors/#wordpress
With NLP, it is possible to detect entities such as:
People
Places
Organizations
Money
Time
Percentage
Define attributes that will be used as filters for your navigation, consolidating the total content in your display
Through attributes defined in the contents, it is possible to use them to restrict their display based on the user’s profile.
Java API (https://github.com/openturing/turing-java-sdk) facilitates the use and access to Viglet Turing ES, without the need for consumer search content with complex queries.
Communicate with your client and elaborate complex intents, obtain reports and progressively evolve your interaction.
Its components:
Handles conversations with your end users. It is a natural language processing module that understands the nuances of human language
An intent categorizes an end user’s intention for taking a conversation shift. For each agent, you define several intents, where your combined intents can handle a complete conversation.
The field of action is a simple field of convenience that helps to execute logic in the service.
Each intent parameter has a type, called an entity type, that dictates exactly how the data in an end user expression is extracted.
Defines and corrects intents.
Shows the conversation history and reports.
Turing ES detects Entities of OpenText Blazon Documents using OCR and NLP, generating Blazon XML to show the entities into document.
Turing ES has many components: Search Engine, NLP, Converse (Chat bot), Semantic Navigation
When access the Turing ES, appear a login page. For default the login/password is admin/admin
Figure 2. Login Page
Search Engine is used by Turing to store and retrieve data of Converse (Chat bot) and Semantic Navigation Sites.
Figure 3. Search Engine Page
It is possible create or edit a Search Engine with following attributes:
| Attribute | Description |
|---|---|
Name | Name of Search Engine |
Description | Description of Search Engine |
Vendor | Select the Vendor of Search Engine. For now, it only supports Solr. |
Host | Host name where the Search Engine service is installed |
Port | Port of Search Engine Service |
Language | Language of Search Engine Service. |
Enabled | If the Search Engine is enabled. |
Figure 4. Semantic Navigation Page
The Detail of Semantic Navigation Site contains the following attributes:
| Attribute | Description |
|---|---|
Name | Name of Semantic Navigation Site. |
Description | Description of Semantic Navigation Site. |
Search Engine | Select the Search Engine that was created in Search Engine Section. The Semantic Navigation Site will use this Search Engine to store and retrieve data. |
NLP | Select the NLP that was created in NLP Section. THe Semantic Navigation Site will use this NLP to detect entities during indexing. |
Thesaurus | If you use Thesaurus. |
Language | Language of Semantic Navigation Site. |
Core | Name of core of Search Engine where will be stored and retrieved the data. |
Fields Tab contains a table with the following columns: .Semantic Navigation Site Fields Columns
| Column Name | Description |
|---|---|
Type | Type of Field. It can be: - NER (Named Entity Recognition) used by NLP. - Search Engine used by Solr. |
Field | Name of Field. |
Enabled | If the field is enabled or not. |
MLT | If this field will be used in MLT. |
Facets | To use this field like a facet (filter) |
Highlighting | If this field will show highlighted lines. |
NLP | If this field will be processed by NLP to detect Entities (NER) like People, Organization and Place. |
When click in Field appear a new page with Field Details with the following attributes:
| Attribute | Description |
|---|---|
Name | Name of Field |
Description | Description of Field |
Type | Type of Field. It can be: |
Multi Valued | If is an array |
Facet Name | Name of Label of Facet (Filter) on Search Page. |
Facet | To use this field like a facet (filter) |
Highlighting | If this field will show highlighted lines. |
MLT | If this field will be used in MLT. |
Enabled | If the field is enabled. |
Required | If the field is required. |
Default Value | Case the content is indexed without these field, that is the default value. |
NLP | If this field will be processed by NLP to detect Entities (NER) like People, Organization and Place. |
Contains the following attributes:
| Section | Attribute | Description |
|---|---|---|
Appearance | Number of items per page | Number of items that will appear in search. |
Facet | Facet enabled? | If it will be show Facet (Filters) on search. |
Number of items per facet | Number of items that will appear in each Facet (Filter). | |
Highlighting | Highlighting enabled? | Define whether to show highlighted lines. |
Pre Tag | HTML Tag that will be used on begin of term. For example: <mark> | |
Post Tag | HTML Tag that will be used on the end of term. For example: </mark> | |
MLT | More Like This enabled? | Define whether to show MLT |
Default Fields | Title | Field that will be used as title that is defined in Solr schema.xml |
Text | Field that will be used as title that is defined in Solr schema.xml | |
Description | Field that will be used as description that is defined in Solr schema.xml | |
Date | Field that will be used as date that is defined in Solr schema.xml | |
Image | Field that will be used as Image URL that is defined in Solr schema.xml | |
URL | Field that will be used as URL that is defined in Solr schema.xml |
In Turing ES Console > Semantic Navigation > <SITE_NAME>, click in Configure button and click Search Page button.
It will open a Search Page that uses the pattern:
GET http://localhost:2700/sn/<SITE_NAME>
This page requests the Turing Rest API via AJAX. For example, to return all results of Semantic Navigation Site in JSON Format:
GET http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| Attribute | Required / Optional | Description | Example |
|---|---|---|---|
q | Required | Search Query. | q=foo |
p | Required | Page Number, first page is 1. | p=1 |
sort | Required | Sort values: | sort=relevance |
fq[] | Optional | Query Field. Filter by field, using the following pattern: FIELD: VALUE. | fq[]=title:bar |
tr[] | Optional | Targeting Rule. Restrict search based in: FIELD: VALUE. | tr[]=department:foobar |
rows | Optional | Number of rows that query will return. | rows=10 |
On Intranet of Insurance Company uses OpenText WEM and OpenText Portal integrated with Dynamic Portal Module, a consolidated search was created in Viglet Turing ES, using the connectors: WEM, Database with File System. In this way it was possible to display all the contents and files of the search Intranet, with targeting rules, allowing only to display content that the user has permission. The OpenText Portal accesses Viglet Turing ES Java API, so it was not necessary to create complex queries to return the results.
A set of API Rest was created to make all Government Company content available to partners. All these contents are in OpenText WEM and the WEM connector was used to index the contents on Viglet Turing ES. A Spring Boot application was created with the Rest API set that consumes Turing ES content through the Viglet Turing ES Java API.
Brazilian University website was developed using Viglet Shio CMS (https://viglet.com/shio), and all contents are indexed in Viglet Turing ES automatically. This configuration was made in content modeling and the development of the search template was made in Viglet Shio CMS.


