auto rag eval
1.0.0
This repository is the companion of the ICML 2024 paper Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation (Blog)
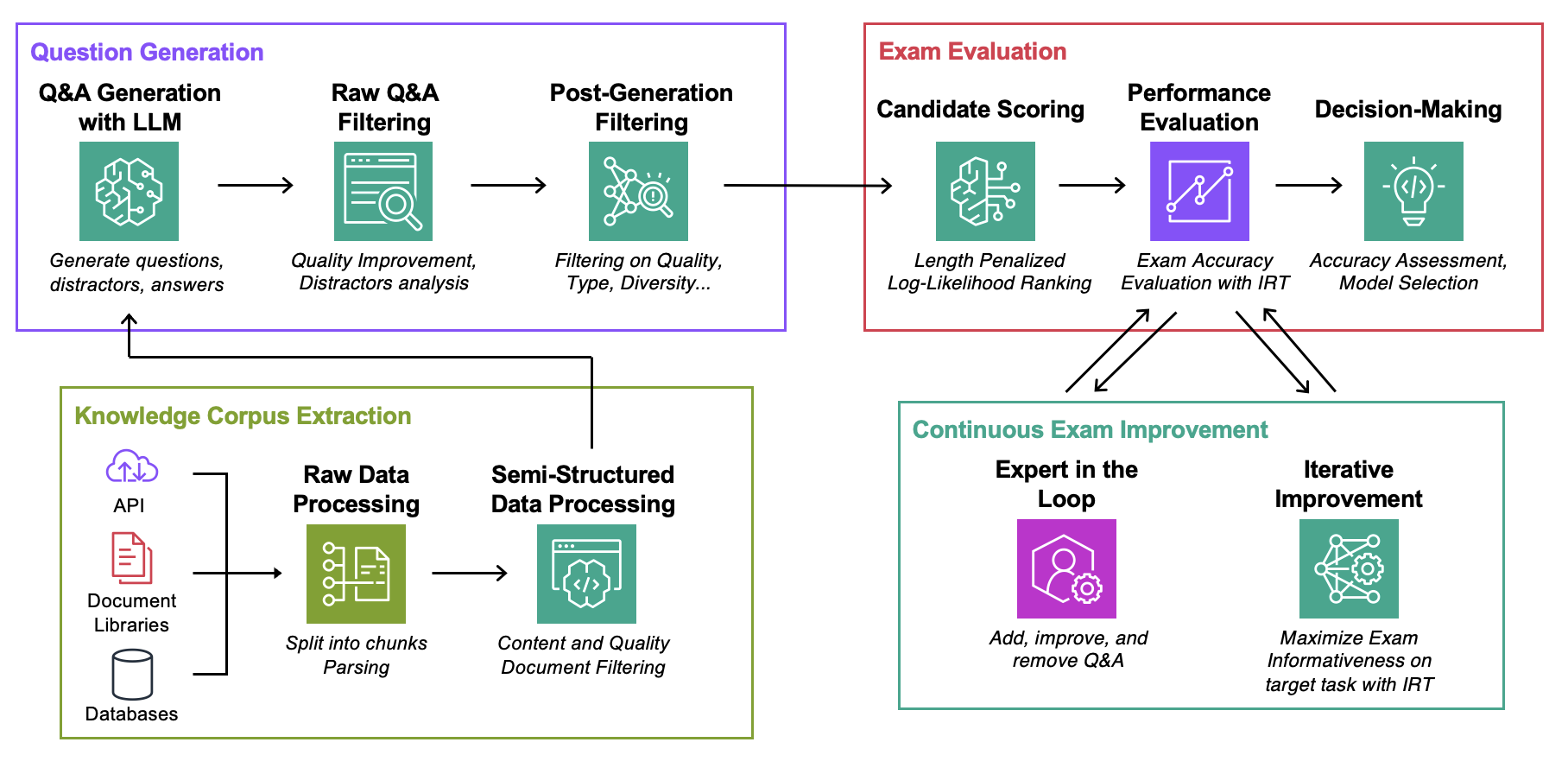
Goal: For a given knowledge corpus:
The only thing you need to experiment with this code is a json file with your knowledge corpus in the format described bellow.
Data: For each use case, contains:
ExamGenerator: Code to generate and process the multi-choice exam using knowledge corpus and LLM generator(s).ExamEvaluator: Code to evaluate exam using a combination (Retrieval System, LLM, ExamCorpus), relying on lm-harness library.LLMServer: Unified LLM endpoints to generate the exam.RetrievalSystems: Unified Retrieval System classes (eg DPR, BM25, Embedding Similarity...).We illustrate our methodology on 4 tasks of interest: AWS DevOPS Troubleshooting, StackExchange Q&A, Sec Filings Q&A and Arxiv Q&A. We then show how to adapt the methodology to any task.
Run the commands bellow, where question-date is the data with the raw data generation. Add --save-exam if you want to save the exam and remove it if you're only interested by analytics.
cd auto-rag-eval
rm -rf Data/StackExchange/KnowledgeCorpus/main/*
python3 -m Data.StackExchange.preprocessor
python3 -m ExamGenerator.question_generator --task-domain StackExchange
python3 -m ExamGenerator.multi_choice_exam --task-domain StackExchange --question-date "question-date" --save-examcd auto-rag-eval
rm -rf Data/Arxiv/KnowledgeCorpus/main/*
python3 -m Data.Arxiv.preprocessor
python3 -m ExamGenerator.question_generator --task-domain Arxiv
python3 -m ExamGenerator.multi_choice_exam --task-domain Arxiv --question-date "question-date" --save-examcd auto-rag-eval
rm -rf Data/SecFilings/KnowledgeCorpus/main/*
python3 -m Data.SecFilings.preprocessor
python3 -m ExamGenerator.question_generator --task-domain SecFilings
python3 -m ExamGenerator.multi_choice_exam --task-domain SecFilings --question-date "question-date" --save-examcd src/llm_automated_exam_evaluation/Data/
mkdir MyOwnTask
mkdir MyOwnTask/KnowledgeCorpus
mkdir MyOwnTask/KnowledgeCorpus/main
mkdir MyOwnTask/RetrievalIndex
mkdir MyOwnTask/RetrievalIndex/main
mkdir MyOwnTask/ExamData
mkdir MyOwnTask/RawExamDataStore in MyOwnTask/KnowledgeCorpus/main a json file, with contains a list of documentation, each with format bellow. See DevOps/html_parser.py, DevOps/preprocessor.py or StackExchange/preprocessor.py for some examples.
{'source': 'my_own_source',
'docs_id': 'Doc1022',
'title': 'Dev Desktop Set Up',
'section': 'How to [...]',
'text': "Documentation Text, should be long enough to make informative questions but shorter enough to fit into context",
'start_character': 'N/A',
'end_character': 'N/A',
'date': 'N/A',
}First generate the raw exam and the retrieval index.
Note that you might need to add support for your own LLM, more on this bellow.
You might want to modify the prompt used for the exam generation in LLMExamGenerator class in ExamGenerator/question_generator.py.
python3 -m ExamGenerator.question_generator --task-domain MyOwnTaskOnce this is done (can take a couple of hours depending on the documentation size), generate the processed exam. To do so, check MyRawExamDate in RawExamData (eg 2023091223) and run:
python3 -m ExamGenerator.multi_choice_exam --task-domain MyOwnTask --question-date MyRawExamDate --save-examWe currently support endpoints for Bedrock (Claude) in LLMServer file.
The only thing needed to bring your own is a class, with an inference function that takes a prompt in input and output both the prompt and completed text.
Modify LLMExamGenerator class in ExamGenerator/question_generator.py to incorporate it.
Different LLM generate different types of questions. Hence, you might want to modify the raw exam parsing in ExamGenerator/multi_choice_questions.py.
You can experiment using failed_questions.ipynb notebook from ExamGenerator.
We leverage lm-harness package to evaluate the (LLM&Retrieval) system on the generated exam. To do, follow the next steps:
Create a benchmark folder for for your task, here DevOpsExam, see ExamEvaluator/DevOpsExam for the template.
It contains a code file preprocess_exam,py for prompt templates and more importantly, a set of tasks to evaluate models on:
DevOpsExam contains the tasks associated to ClosedBook (not retrieval) and OpenBook (Oracle Retrieval).DevOpsRagExam contains the tasks associated to Retrieval variants (DPR/Embeddings/BM25...).The scripttask_evaluation.sh provided illustrates the evalation of Llamav2:Chat:13B and Llamav2:Chat:70B on the task, using In-Context-Learning (ICL) with respectively 0, 1 and 2 samples.
To cite this work, please use
@misc{autorageval2024,
title={Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation},
author={Gauthier Guinet and Behrooz Omidvar-Tehrani and Anoop Deoras and Laurent Callot},
year={2024},
eprint={2405.13622},
archivePrefix={arXiv},
primaryClass={cs.CL}
}See CONTRIBUTING for more information.
This project is licensed under the Apache-2.0 License.


