Lihang
1.0.0
The second edition of this book has been published. All content updates after May 2019 refer to the first printing of the second edition.
For the content of the first edition, see Release first_edition
[TOC]
To facilitate learning, some tool descriptions are compiled.
If you need to reference this Repo:
Format: SmirkCao, Lihang, (2018), GitHub repository, https://github.com/SmirkCao/Lihang
or
@misc{SmirkCao,
author = {SmirkCao},
title = {Lihang},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/SmirkCao/Lihang}},
commit = {c5624a9bd757a5cc88e78b85b89e9221deb08270}
}
This part of the content does not correspond to the preface in "Statistical Learning Methods". The preface in the book is also well written and is quoted as follows:
- In terms of content selection, we focus on introducing the most important and commonly used methods, especially methods related to classification and labeling problems.
- Try to use a unified framework to discuss all methods so that the whole book does not lose its systematicness.
- Applicable to college students and graduate students majoring in information retrieval and natural language processing.
Another thing to note is the author’s work background.
The author has been engaged in research on various intelligent processing of text data using statistical learning methods, including natural language processing, information retrieval, and text data mining.
If you use my model to implement similarity search, the book that is similar to Mr. Li's book is "Semiconductor Optoelectronic Devices". It's a pity that I didn't read it repeatedly when I was young.
I hope that in the process of repeated reading, the entire book will become thicker and thinner. All documents and codes in this series, unless otherwise stated, the description "in the book" refers to "Statistical Learning Methods" by Teacher Li Hang. Contents in other references will be linked if cited.
Some references are listed in Refs, some of which are very helpful for understanding the contents of the book. Descriptions and explanations of these files will be added in Refs/README.md corresponding to the reference section. Some notes on other references have also been added to this document.
To facilitate reference downloading, ref_downloader.sh was added during review02, which can be used to download the references listed in the book. The update process is gradually completed as review02 progresses.
In addition, this book by Teacher Li Hang, It’s really thin (the second version is no longer thin) , but almost every sentence brings out many points and is worth reading again and again.
There is a symbol table after the table of contents in the book, which explains the symbol definitions, so if there are symbols you do not understand, you can look it up in the table; there is an index at the back of the book, and you can use the index to find the meaning of the corresponding symbol that appears in the book. Location. In this Repo, a glossary_index.md is maintained to add some explanations to the corresponding symbols and directly mark the page numbers corresponding to the symbols. The progress will be updated with the review.
After each algorithm or example, there will be a ◼️, indicating that the algorithm or example ends here. This is called the proof end symbol. You will know it if you read more literature.
When reading, we often have questions about the base of logarithms. Some of the more important ones are emphasized in the book. Some that are not emphasized can be understood through context. In addition, because there is a formula for changing the base, it does not matter much what the base is. The difference lies in a constant coefficient. However, choosing different bases will have physical meanings and problem-solving considerations. For analysis of this issue, you can see the discussion on entropy in PRML 1.6 to understand.
In addition, regarding the issue of constant coefficients in the formula, if an iterative solution is used and sometimes the formula is simplified to a certain extent, the convergence speed may be improved. The details can be gradually understood in practice.
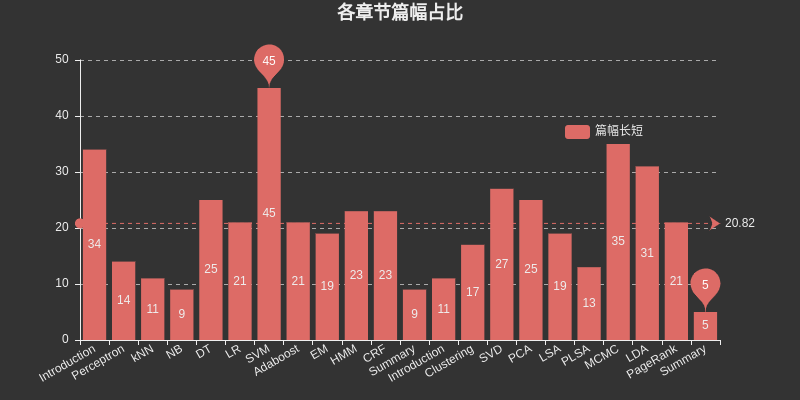
Insert a chart here to list the space occupied by each chapter. Among them, SVM takes up the largest space among supervised learning, MCMC takes up the largest space among unsupervised learning, and DT, HMM, CRF, SVD, PCA, LDA, and PageRank also occupy the largest space. relatively large space.
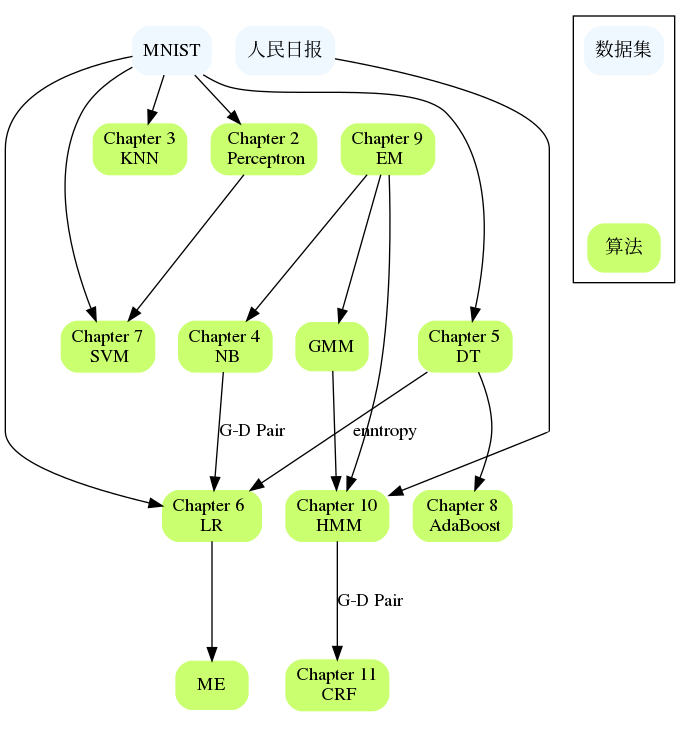
The chapters are related to each other, such as NB and LR, DT and AdaBoost, Perceptron and SVM, HMM and CRF, etc. If you encounter difficulties in a large chapter, you can review the content of the previous chapters or check the references of specific chapters. References are generally given that describe the problem in more detail and may explain where you are stuck.
Introduction
Three elements of statistical learning methods:
Model
Strategy
algorithm
The second edition has reorganized the directory structure of this chapter to make it clearer.
Perceptron
kNN
N.B.
DT
LR
Regarding the study of maximum entropy, it is recommended to read the reference literature [1] in this chapter, Berger, 1996, which is helpful for understanding the examples in the book and grasping the principle of maximum entropy.
So, why are LR and Maxent placed in one chapter?
All belong to the logarithmic linear model
Both can be used for binary classification and multi-classification
The learning methods of the two models generally use maximum likelihood estimation, or regularized maximum likelihood estimation. It can be formalized as an unconstrained optimization problem, and the solution methods include IIS, GD, BFGS, etc.
It is described as follows in Logistic regression,
Logistic regression, despite its name, is a linear model for classification rather than regression. Logistic regression is also known in the literature as logit regression, maximum-entropy classification (MaxEnt) or the log-linear classifier. In this model, the probabilities describing the possible outcomes of a single trial are modeled using a logistic function.
There is also such a description
Logistic regression is a special case of maximum entropy with two labels +1 and −1.
The derivation in this chapter uses the property of $yin mathcal{Y}={0,1}$
Sometimes we say that logistic regression is called Maxent in NLP
SVM
Boosting
Let’s break it down here, because HMM and CRF usually lead to the introduction of probabilistic graphical models later. In "Machine Learning, Zhou Zhihua", a separate probabilistic graphical model chapter is used to include HMM, MRF, CRF and other contents. In addition, there are many related points from HMM to CRF itself.
In the first chapter of the book, three applications of supervised learning are explained: classification, labeling and regression. There are supplements in Chapter 12. This book mainly considers the learning methods of the first two. Accordingly, segmentation is also appropriate here. The classification model is introduced earlier, and regression is mentioned in a small part. The labeling problem is mainly introduced later.
EM
The EM algorithm is an iterative algorithm used for maximum likelihood estimation of probabilistic model parameters containing hidden variables, or maximum posterior probability estimation. (The maximum likelihood estimation and maximum posterior probability estimation here are learning strategies )
If the variables of the probability model are all observed variables, then given the data, the model parameters can be estimated directly using the maximum likelihood estimation method or the Bayesian estimation method.
Note that if you do not understand this description in the book, please refer to the parameter estimation part of the Naive Bayes method in CH04.
This part of the code implements BMM and GMM, it is worth taking a look
Regarding EM, not much has been written about this chapter. EM is one of the top ten algorithms. EM and Hinton are closely related. Hinton published the second article of Capsule Network "Matrix Capsules with EM Routing" at ICLR in 2018.
In CH22, the EM algorithm is classified as a basic machine learning method and does not involve specific machine learning models. It can be used for unsupervised learning, supervised learning, and semi-supervised learning.
HMM
CRF
Summary
This chapter only has a few pages. You can consider the following reading routine:
Read it with Chapter 1
If you encounter unclear questions in previous studies, read this chapter again.
Read this chapter thickly and expand from this chapter to ten other chapters.
Note that there is Figure 12.2 in this chapter, which mentions the logistic loss function. $y$ here should be defined in $cal{Y}={+1,-1}$. LR was introduced earlier. When $y$ is defined at $cal{Y}={0,1}$, please pay attention here.
Teacher Li’s book really makes you gain something new every time you read it.
The second edition adds eight unsupervised learning methods: clustering, singular value decomposition, principal component analysis, latent semantic analysis, probabilistic latent semantic analysis, Markov chain Monte Carlo method, latent Dirichlet allocation, and PageRank.
Introduction
Clustering
Each chapter in this book is not completely independent. This part hopes to organize the connections between chapters and applicable data sets. How far the algorithm is implemented and what data sets it can run on are also one aspect.