homemade machine learning
1.0.0
?? UKRAINE IS BEING ATTACKED BY RUSSIAN ARMY. CIVILIANS ARE GETTING KILLED. RESIDENTIAL AREAS ARE GETTING BOMBED.
- Help Ukraine via:
- Serhiy Prytula Charity Foundation
- Come Back Alive Charity Foundation
- National Bank of Ukraine
- More info on war.ukraine.ua and MFA of Ukraine
Read this in other languages: Español
You might be interested in:
- Homemade GPT • JS
- Interactive Machine Learning Experiments
For Octave/MatLab version of this repository please check machine-learning-octave project.
This repository contains examples of popular machine learning algorithms implemented in Python with mathematics behind them being explained. Each algorithm has interactive Jupyter Notebook demo that allows you to play with training data, algorithms configurations and immediately see the results, charts and predictions right in your browser. In most cases the explanations are based on this great machine learning course by Andrew Ng.
The purpose of this repository is not to implement machine learning algorithms by using 3rd party library one-liners but rather to practice implementing these algorithms from scratch and get better understanding of the mathematics behind each algorithm. That's why all algorithms implementations are called "homemade" and not intended to be used for production.
In supervised learning we have a set of training data as an input and a set of labels or "correct answers" for each training set as an output. Then we're training our model (machine learning algorithm parameters) to map the input to the output correctly (to do correct prediction). The ultimate purpose is to find such model parameters that will successfully continue correct input→output mapping (predictions) even for new input examples.
In regression problems we do real value predictions. Basically we try to draw a line/plane/n-dimensional plane along the training examples.
Usage examples: stock price forecast, sales analysis, dependency of any number, etc.
country happiness score by economy GDP
country happiness score by economy GDP and freedom index
In classification problems we split input examples by certain characteristic.
Usage examples: spam-filters, language detection, finding similar documents, handwritten letters recognition, etc.
class based on petal_length and petal_width
validity based on param_1 and param_2
28x28 pixel images28x28 pixel imagesUnsupervised learning is a branch of machine learning that learns from test data that has not been labeled, classified or categorized. Instead of responding to feedback, unsupervised learning identifies commonalities in the data and reacts based on the presence or absence of such commonalities in each new piece of data.
In clustering problems we split the training examples by unknown characteristics. The algorithm itself decides what characteristic to use for splitting.
Usage examples: market segmentation, social networks analysis, organize computing clusters, astronomical data analysis, image compression, etc.
petal_length and petal_width
Anomaly detection (also outlier detection) is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data.
Usage examples: intrusion detection, fraud detection, system health monitoring, removing anomalous data from the dataset etc.
latency and threshold
The neural network itself isn't an algorithm, but rather a framework for many different machine learning algorithms to work together and process complex data inputs.
Usage examples: as a substitute of all other algorithms in general, image recognition, voice recognition, image processing (applying specific style), language translation, etc.
28x28 pixel images28x28 pixel images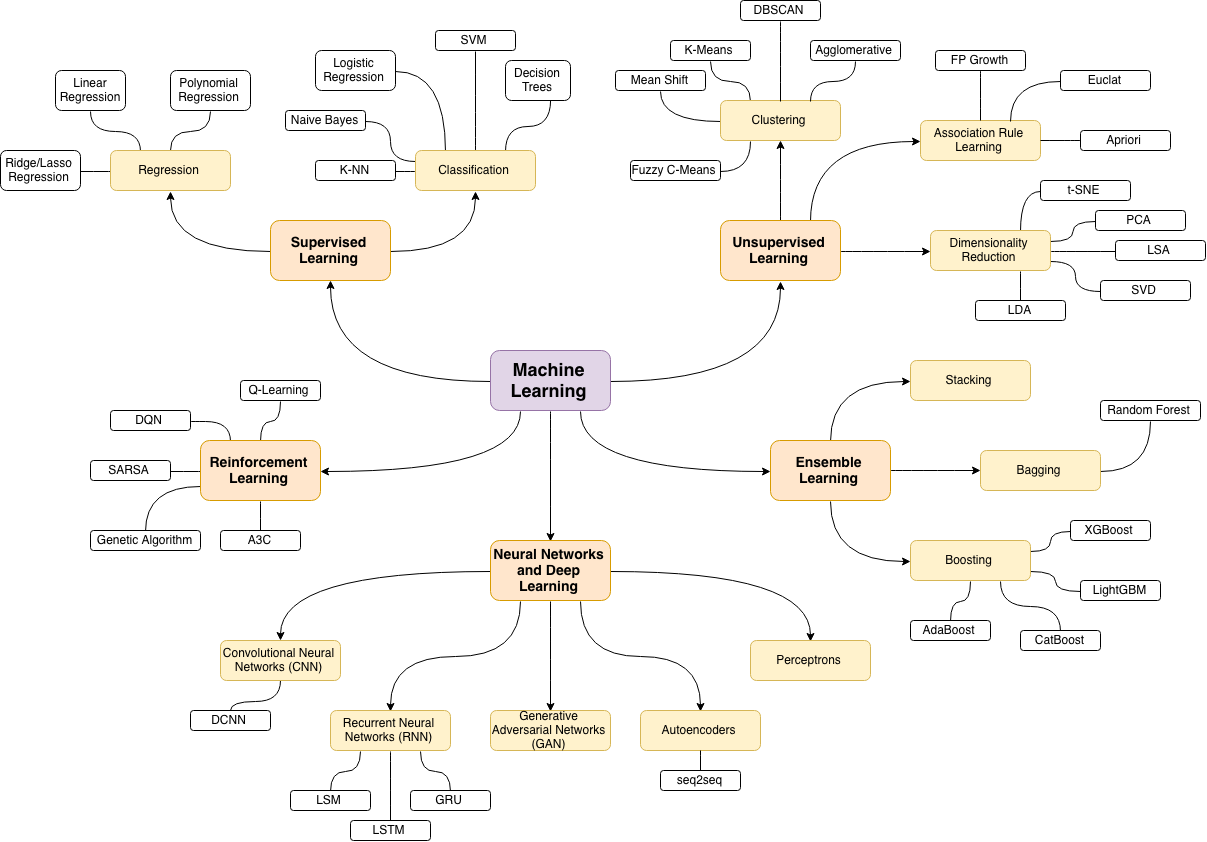
The source of the following machine learning topics map is this wonderful blog post
Make sure that you have Python installed on your machine.
You might want to use venv standard Python library
to create virtual environments and have Python, pip and all dependent packages to be installed and
served from the local project directory to avoid messing with system wide packages and their
versions.
Install all dependencies that are required for the project by running:
pip install -r requirements.txtAll demos in the project may be run directly in your browser without installing Jupyter locally. But if you want to launch Jupyter Notebook locally you may do it by running the following command from the root folder of the project:
jupyter notebookAfter this Jupyter Notebook will be accessible by http://localhost:8888.
Each algorithm section contains demo links to Jupyter NBViewer. This is fast online previewer for Jupyter notebooks where you may see demo code, charts and data right in your browser without installing anything locally. In case if you want to change the code and experiment with demo notebook you need to launch the notebook in Binder. You may do it by simply clicking the "Execute on Binder" link in top right corner of the NBViewer.
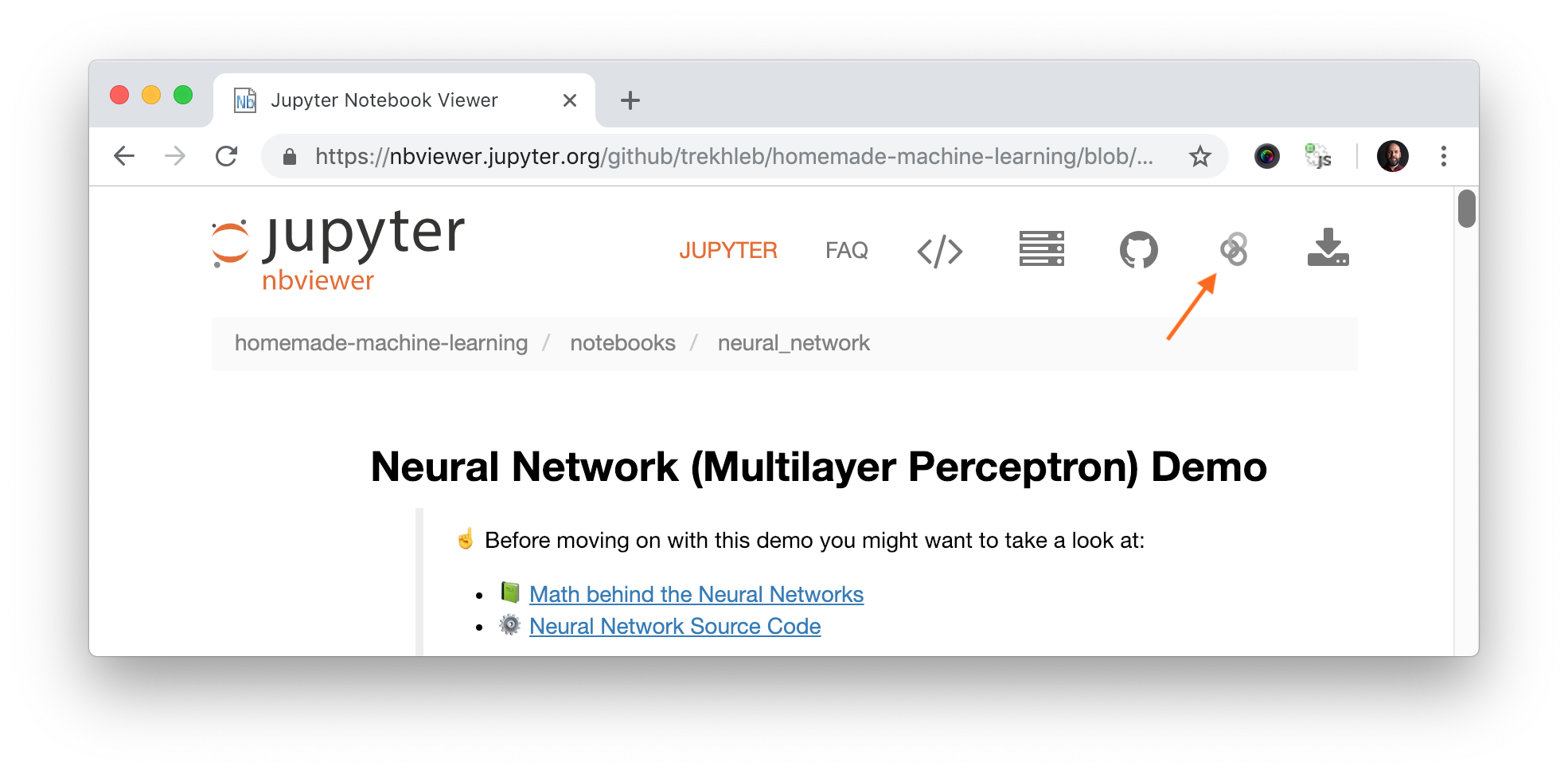
The list of datasets that is being used for Jupyter Notebook demos may be found in data folder.
You may support this project via ❤️️ GitHub or ❤️️ Patreon.


