qwen2 in a lambda
1.0.0
Updated at 11/09/2024
(Marking the date because of how fast LLM APIs in Python move and may introduce breaking changes by the time anyone else reads this!)
This is a minor research on how we can put Qwen GGUF model files into AWS Lambda using Docker and SAM CLI
Adapted from https://makit.net/blog/llm-in-a-lambda-function/
I wanted to find out if I can reduce my AWS spending by only leveraging on the capabilities of Lambda and not Lambda + Bedrock as both services would incur more costs in the long run.
The idea was to fit a small language model which wouldn't be as resource intensive relatively speaking and to, hopefully, receive subsecond to second latency on a 128 - 256 mb memory configuration
I wanted to use also GGUF models to use different levels of quantization to find out which is the best performance / file size to be loaded into memory
qwen2-1_5b-instruct-q5_k_m.gguf into qwen_fuction/function/
app.y / LOCAL_PATHqwen_function/function/requirements.txt (preferably in a venv/conda env)sam build / sam validatesam local start-api to test locallycurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate to prompt the LLM
sam deploy --guided to deploy to AWS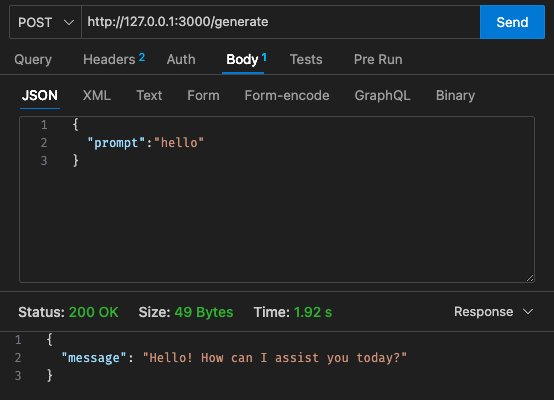
AWS
Initial config - 128mb, 30s timeout
Adjusted config #1 - 512mb, 30s timeout
Adjusted config #2 - 512mb, 30s timeout
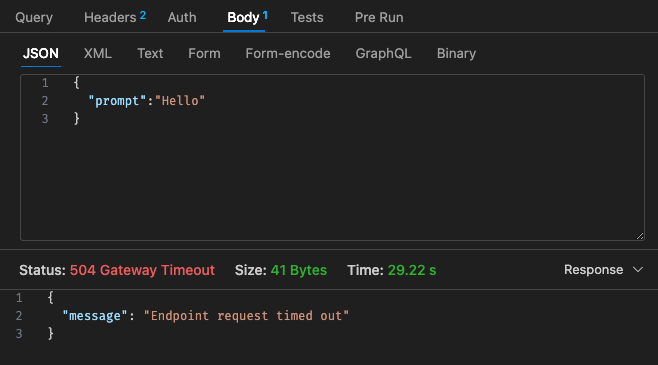
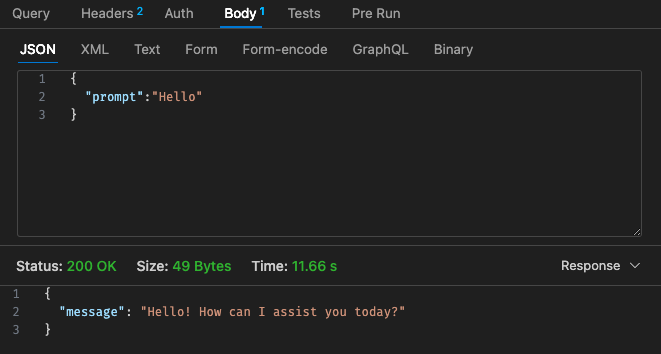
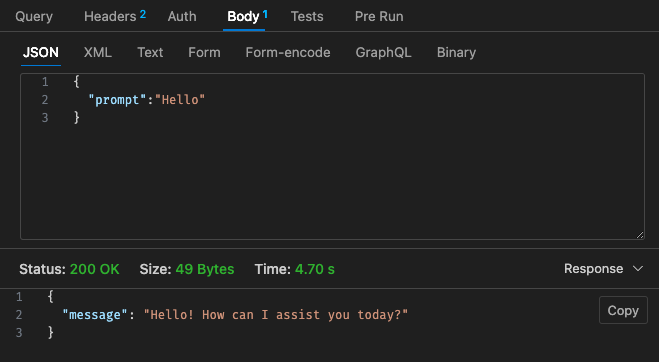
Referring back to the pricing structure of Lambda,
It may be cheaper to just use a hosted LLM using AWS Bedrock, etc.. on the cloud as the pricing structure for Lambda w/ Qwen does not look more competitive compared to Claude 3 Haiku
Furthermore, the API gateway timeout is not easily configurable beyond the 30s timeout, depending on your usecase, this may not be very ideal
Results via local is dependant on your machine specs!! and may heavily skew your perception, expectation vs reality
Depending on your use case also, the latency per lambda invocation and responses might incur poor user experiences
All in all, I think this was a fun little experiment even though it didn't quite pan out to the budget & latency requirement via Qwen 1.5b for my side project. Thanks to @makit again for the guide!


