qevals
1.0.0
Evals is a synthetic data generation and evaluation framework for LLMs and RAG applications.
It has 2 main modules:
A high level architecture diagram of evals is the following:
Architecture diagram
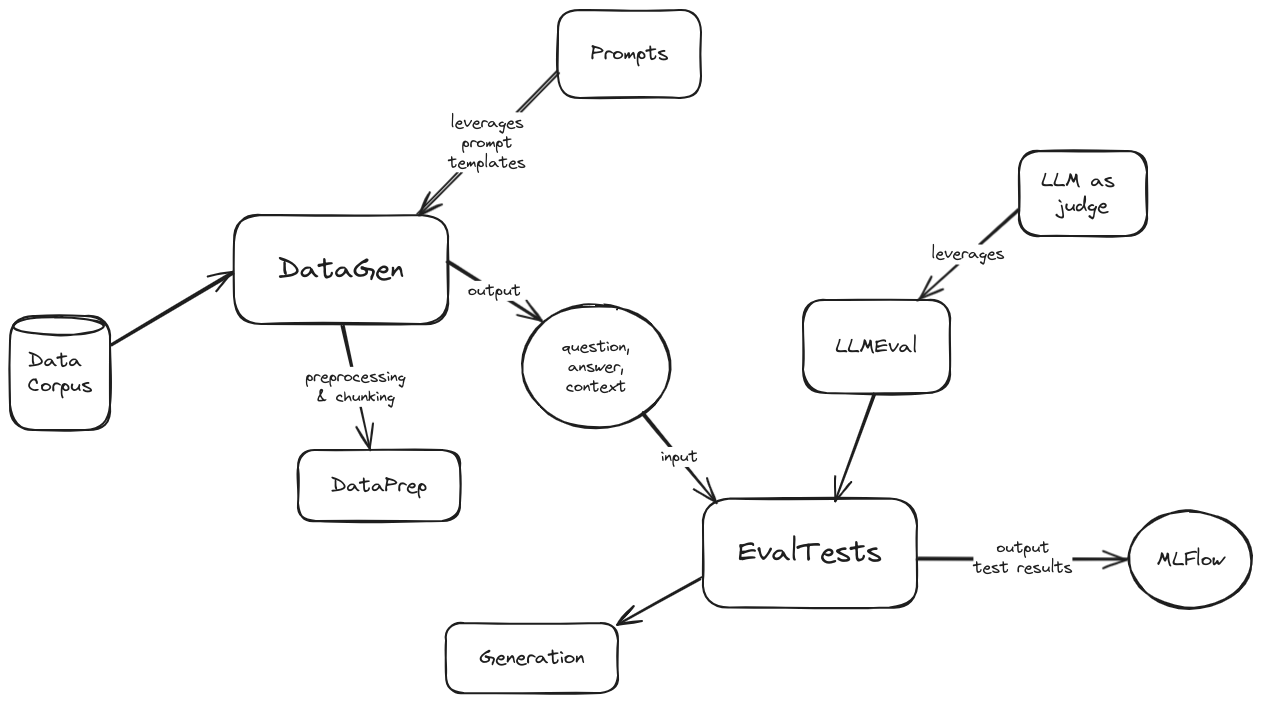
To get started with evals, follow these steps:
pip install -r requirements.txt in the project directory.config/config.toml.template and name it config/config.toml.config.toml file:
MISC
DATAGEN
DATA_DIR variable controls the location of the data corpus to generate synthetic data from, it’s relative to the datagen/data/ directory. In other words, add your data directories in there and specify their name in the variable.GEN_PROVIDER variable allows choosing between azure or vertex.DATAEVAL
EVAL_TESTS offers a list of evaluation tests supported by the framework. The possible options are AnswerRelevancy, Hallucination, Faithfulness, Bias, Toxicity, Correctness, Coherence, PromptInjection, PromptBreaking, PromptLeakage.EVAL_RPVODER variable allows choosing between azure or vertex.To run the synthetic data generation module:
Modify/adapt the sample client provided (datagen/client.py)
Run python -m datagen.client
The synthetically generated data will be stored in the datagen/qa_out/ directory as a CSV file with the format:
```csv
question,context,ground_truth
```
To run the eval module:
eval/client.py)
question,context,ground_truth).ground_truth may or may not be used depending on the setting use_answers_from_dataset. When set to False it will ignore that data column and generate new outputs using the configured generative model.mlflow ui --port 5000python -m eval.client


