VSA
1.0.0
[Project Page] [?Paper] [?Hugging Face Space] [Model Zoo] [Introduction] [?Video]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
The local demo is based on gradio, and you can simply run with:
python app.py
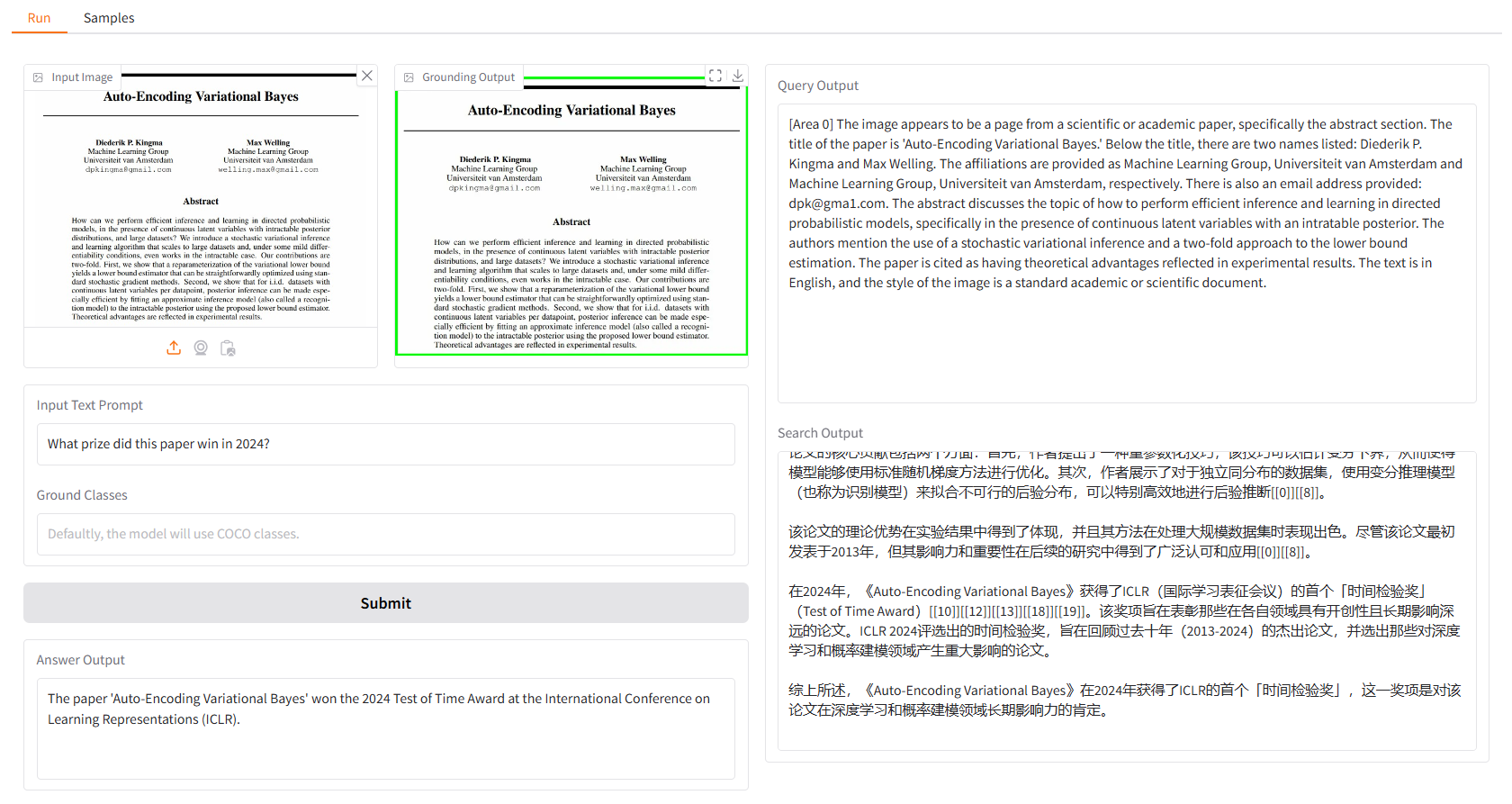
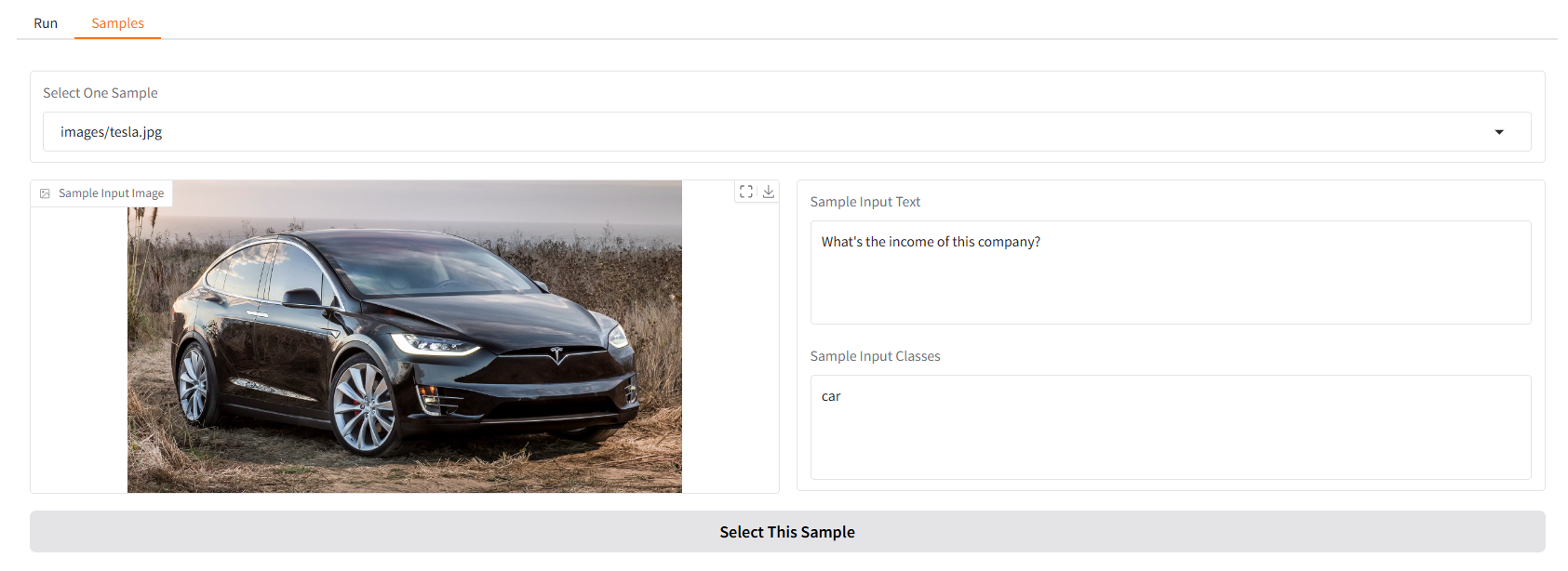
We provide some samples for you to start with. In the "Samples" UI, you can select one in the "Samples" panel, click "Select This Sample", and you will find sample input has already been filled in the "Run" UI.
You can also chat with our Vision Search Assistant in the terminal by running.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
Then, select an image and type your question.
This project is released under the Apache 2.0 license.
Vision Search Assistant is greatly inspired by the following outstanding contributions to the open-source community: GroundingDINO, LLaVA, MindSearch.
If you find this project useful in your research, please consider cite:
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


