amazon sagemaker clip search
1.0.0
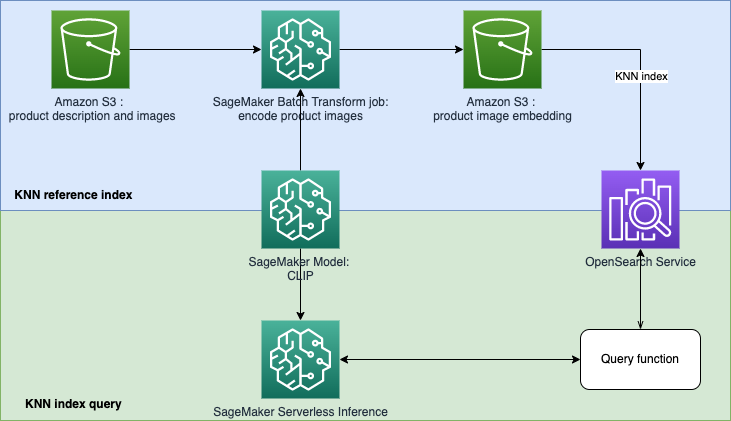
This repository aims at building a machine learning (ML) powered search engine prototype to retrieve and recommend products based on text or image queries. This is a step-by-step guide on how to create SageMaker Models with Contrastive Language-Image Pre-Training (CLIP), use the models to encode images and text into embeddings, ingest embeddings into Amazon OpenSearch Service index, and query the index using OpenSearch Service k-nearest neighbors (KNN) functionality.
Embedding-based retrieval(EBR) is well used in search and recommendation systems. It uses nearest (approximate) neighbour search algorithms to find similar or closely related items from an embedding store (also known as a vector database). Classic search mechanisms depend heavily on key-word matching and ignore the lexical meaning or query’s context. The goal of EBR is to provide users with the ability to find the most relevant products using free text. It is popular because compared with key-word matching it leverages semantic concepts in retrieval process.
In this repo, we focus on building a machine learning (ML) powered search engine prototype to retrieve and recommend products based on text or image queries. This uses the Amazon OpenSearch Service and its k-nearest neighbors (KNN) functionality, as well as Amazon SageMaker and its serverless inference feature. Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models for any use case with fully managed infrastructure, tools, and workflows. Amazon OpenSearch Service is a fully managed service that makes it easy to perform interactive log analytics, real-time application monitoring, website search, and more.
Contrastive Language-Image Pre-Training (CLIP) is a neural network trained on a variety of image and text pairs. The CLIP neural network(s) is able to project both images and text into the same latent space, which means that they can be compared using a similarity measure, such as cosine similarity. You can use CLIP to encode your products’ images or description into embeddings, and then store them into a vector database. Then your customers can perform query in the database to retrieve products that they may have interest. To query the database, your customers need to provide input images or text, and then the input will be encoded with CLIP before sending to the vector database for KNN search.
The vector database here plays the role of search engine. This vector database supports unify images and text-based search, which is particularly useful in the e-commerce and retail industries. One example of image-based search is your customers can search for a product by taking a picture, then query the database using the picture. Regarding to the text-based search, your customers can describe a product in free format text, and then use the text as a query. The search results will be sorted by a similarity score (cosine similarity), if an item of your inventory is more similar to the query (an input image or text), the score will be closer to 1, otherwise the score will be closer to 0. The top K products of your search results are the most relevant products in your inventory.
OpenSearch Service provides text-matching and embedding KNN-based search. We will use embedding KNN-based search in this solution. You can use both image and text as query to search items from the inventory. Implementing this unified image and test KNN-based search application consists of two phases:
The solution uses the following AWS services and features:
In the template opensearch.yml, it will create a OpenSearch Domain and grant your SageMaker Studio Execution role to use the domain.
In the template sagemaker-studio-opensearch.yml, it will create a new SageMaker Domain, a user profile in the Domain and a OpenSearch Domain. So you can use the StageMaker user profile to build this POC.
You can choose one of the templates to execute by following the steps listed below.
Step 1: Go to CloudFormation Service in your AWS console.
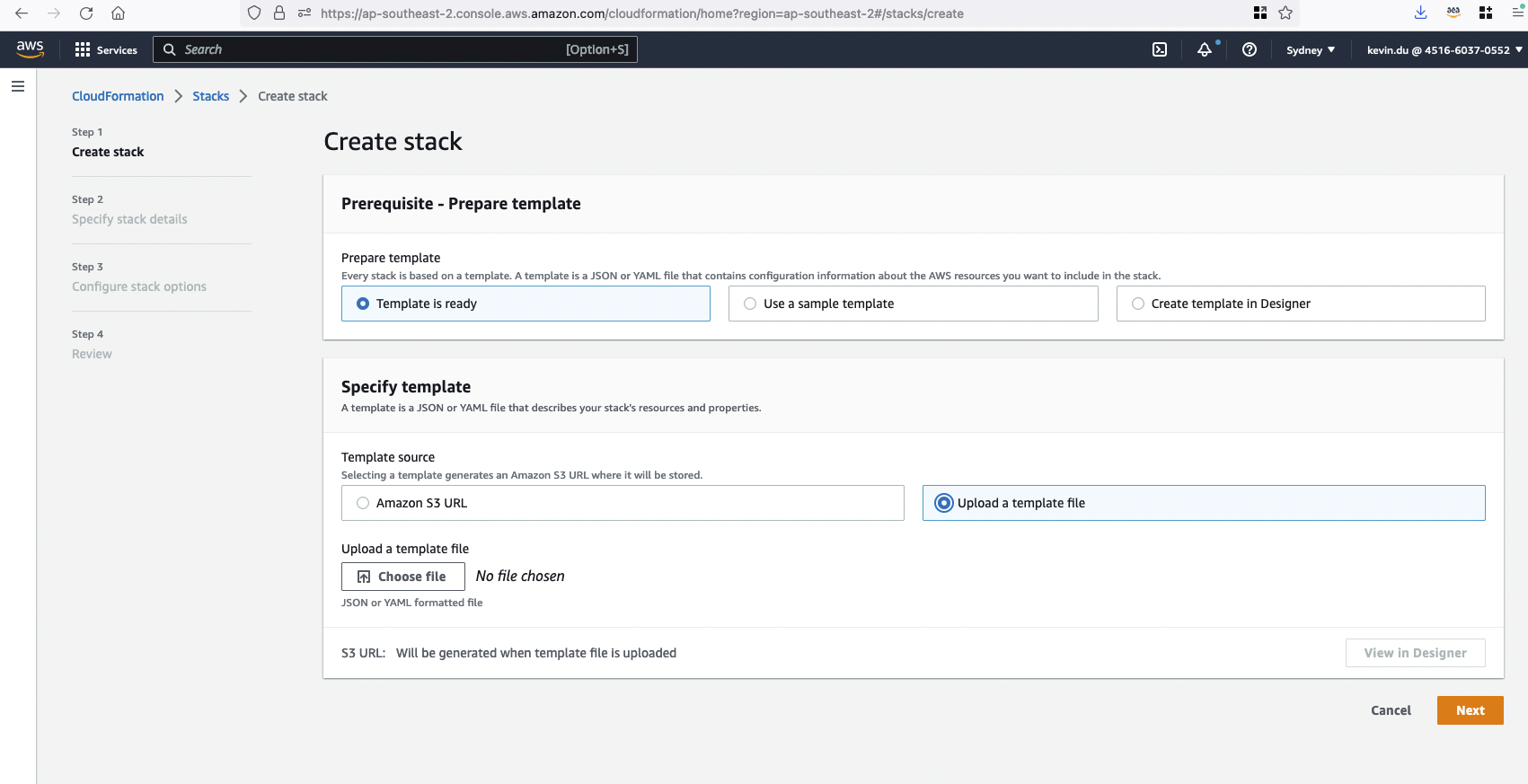
Step 2: Upload a template to create a CloudFormation stack clip-poc-stack.
If you already have a SageMaker Studio running, you can use the template opensearch.yml.
If you don't have a SageMaker Studio at the moment, you can use the template sagemaker-studio-opensearch.yml. It will create a Studio Domain and user profile for you.
Step 3: Check the status of CloudFormation stack. It will take around 20 mins to finish the creation.
Once the stack is created, you can go to the SageMaker Console and click Open Studio to enter the Jupyter environment.
If during the execution, the CloudFormation shows errors about the OpenSearch service linked role can not be found.
You need to create service-linked role by running aws iam create-service-linked-role --aws-service-name es.amazonaws.com in your AWS account.
Please open the file blog_clip.ipynb with the SageMaker Studio and use Data Science Python 3 kernel. You can execute cells from the start.
The Amazon Berkeley Objects Dataset is used in the implementation. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. We will only make use of the item images and item names in US English. For demo purposes we are going to use ~1,600 products.
This section outlines cost considerations for running this demo. Completing the POC will deploy a OpenSearch Cluster and a SageMaker Studio which will cost less than $2 per hour. Noted: the price listed below is calculated using us-east-1 region. The cost varies from region to region. And the cost may change over time as well (the price here is recorded 2022-11-22).
Further cost breakdowns are below.
OpenSearch Service – Prices vary based on instance type usage and Storage cost. For more information, see Amazon OpenSearch Service pricing.
t3.small.search instance runs for approx 1 hour at $0.036 per hour.SageMaker – Prices vary based on EC2 instance usage for the Studio Apps, Batch Transform jobs and Serverless Inference endpoints. For more information, see Amazon SageMaker Pricing.
ml.t3.medium instance for Studio Notebooks runs for approx 1 hour at $0.05 per hour.ml.c5.xlarge instance for Batch Transform runs for approx 6 minutes at $0.204 per hour.S3 – Low cost, prices will vary depending on the size of the models/artifacts stored. The first 50 TB each month will cost only $0.023 per GB stored. For more information, see Amazon S3 Pricing.
See CONTRIBUTING for more information.
This library is licensed under the MIT-0 License. See the LICENSE file.


