ndvr
1.0.0
2nd Rank for the Neural Search Hackathon ?
We have witnessed an explosive growth of video data in a variety of video sharing websites with billions of videos being available on the internet, it becomes a major challenge to perform near-duplicate video retrieval (NDVR) from a large-scale video database. NDVR aims to retrieve the near-duplicate videos from a massive video database, where near-duplicate videos are defined as videos that are visually close to the original videos.
Users have a strong incentive to copy a trending short video & upload an augmented version to gain attention. With the growth of short videos, new difficulties and challenges for detecting near duplicate short videos appears.
Here, we have built a Neural Search solution using Jina to solve the challenge of NDVR.
Table of Contents

Example of hard positive candidate videos. Top row: side morrored, color-filtered, and waterwashed. Middle row: horizontal screen changed to vertical screen with large black margins. Botton row: rotated
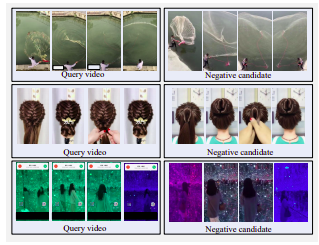
Example of hard negative videos. All the candidates are visually similar to the query but not near-duplicates.
There are three strategies for selecting candidate videos:
We decided to go with Transformed Retrieval strategy due to the time & resource constraint. In real applications, users would copy trending videos for personal incentives. Users usually choose to modify their copied videos slightly to bypass the detection. These modifications contain video cropping, border insertion and so on.
To mimic such user behavior, we define one temporal transformation, i.e., video speeding, and three spatial transformations, i.e., video cropping, black border insertion, and video rotation.
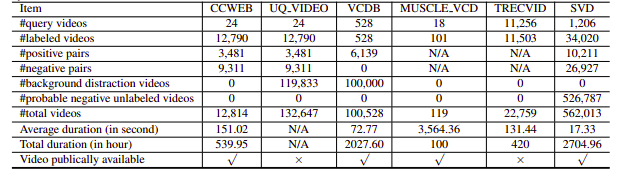
Unfortunately, the NDVR datasets researched upon were either low resoluation or huge or domain specfic or not publicly available(we contacted few personally as well). Hence, we decided to create our small custom dataset to experiment on.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexThe index Flow is defined as follows:
!Flow
with:
logserver: false
pods:
chunk_seg:
uses: craft/craft.yml
parallel: $PARALLEL
read_only: true
timeout_ready: 600000
tf_encode:
uses: encode/encode.yml
needs: chunk_seg
parallel: $PARALLEL
read_only: true
timeout_ready: 600000
chunk_idx:
uses: index/chunk.yml
shards: $SHARDS
separated_workspace: true
doc_idx:
uses: index/doc.yml
needs: gateway
join_all:
uses: _merge
needs: [doc_idx, chunk_idx]
read_only: trueThis breaks down into the following steps:
Here we use a YAML file to define a Flow and use it to index the data. The index function takes a input_fn param which takes an Iterator to pass file paths, which will be further wrapped in an IndexRequest and sent to the Flow.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index":
f = Flow().load_config("flow-index.yml")
with f:
f.index(input_fn=input_index_data(DATA_BLOB, size=num_docs), batch_size=2)def input_index_data(patterns, size):
def iter_file_exts(ps):
return it.chain.from_iterable(glob.iglob(p, recursive=True) for p in ps)
d = 0
if isinstance(patterns, str):
patterns = [patterns]
for g in iter_file_exts(patterns):
yield g.encode()
d += 1
if size is not None and d > size:
breakpython app.py -t queryYou can then open Jinabox with the custom endpoint http://localhost:45678/api/search
The query Flow is defined as follows:
!Flow
with:
logserver: true
read_only: true # better add this in the query time
pods:
chunk_seg:
uses: craft/index-craft.yml
parallel: $PARALLEL
tf_encode:
uses: encode/encode.yml
parallel: $PARALLEL
chunk_idx:
uses: index/chunk.yml
shards: $SHARDS
separated_workspace: true
polling: all
uses_reducing: _merge_all
timeout_ready: 100000 # larger timeout as in query time will read all the data
ranker:
uses: BiMatchRanker
doc_idx:
uses: index/doc.ymlThe query flow breaks down into the following steps:


