nnl
gpt2-xl assets
nnl is an inference engine for large models on low-memory GPU platform.
Big models are too large to fit into the GPU memory. nnl addresses this problem with a trade-off between PCIE bandwidth and memory.
A typical inference pipeline is as follows:
With GPU memory pool and memory defragmentation, NNIL makes it possible to inference a large model on a low-end GPU platform.
This is just a hobby project written up in a few weeks, currently only CUDA backend is supported.
make libnnl_cuda.a && make libnnl_cuda_kernels.aThis command will build the two static libraries: lib/libnnl_cuda.a and lib/libnnl_cuda_kernels.a. The first one is the core library with CUDA backend in C++, and the second one is for the CUDA kernels.
A demo program of GPT2-XL (1.6B) is provided here. This program can be compiled by this command:
make gpt2_1558mAfter downloading all the weights from the release, we can run the following command on a low-end GPU platform such as GTX 1050 (2 GB memory):
./bin/gpt2_1558m --max_len 20 "Hi. My name is Feng and I am a machine learning engineer"And the output is like this:
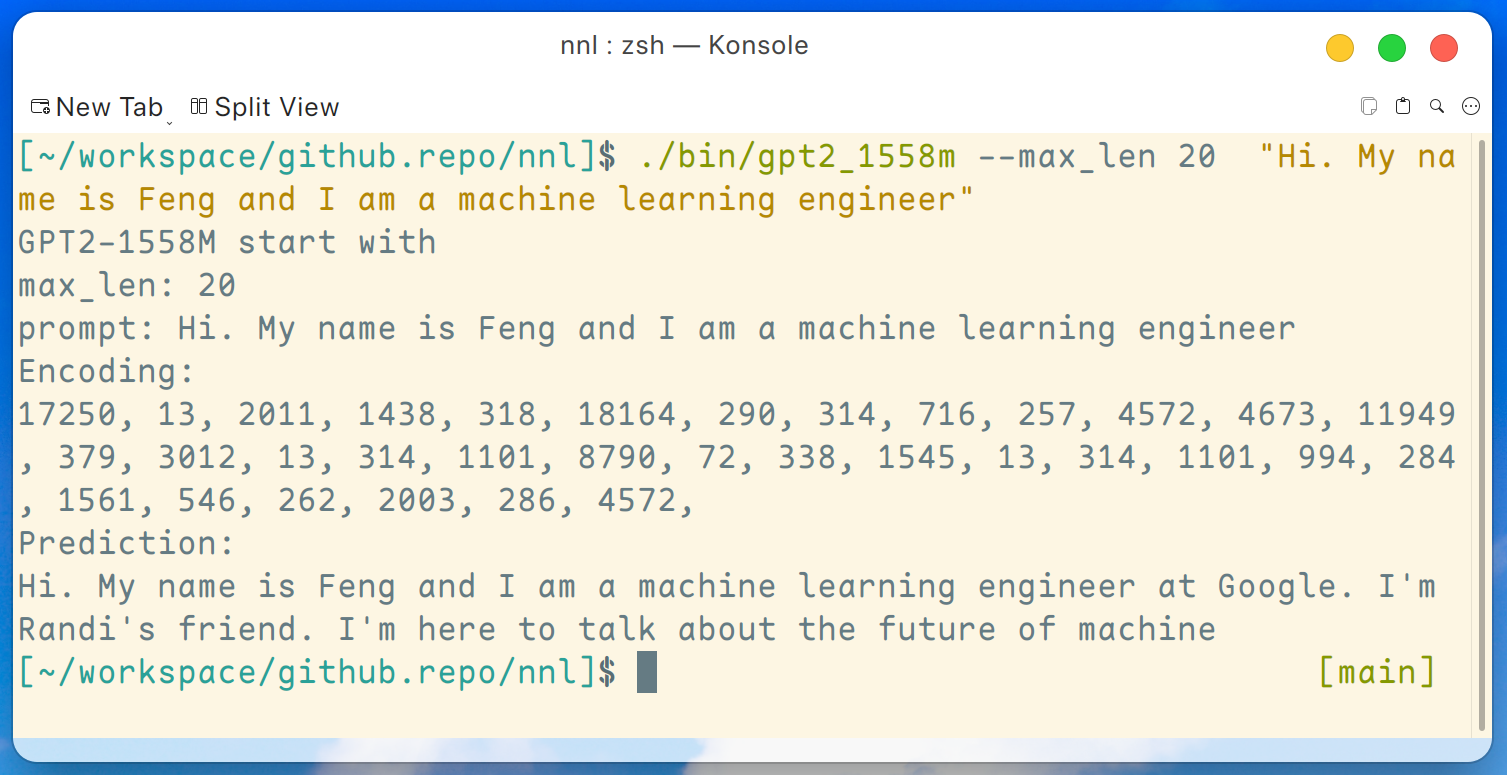
Disclaimer: this is just an example generated by gpt2-xl, I am not working at Google and I do not know Randi.
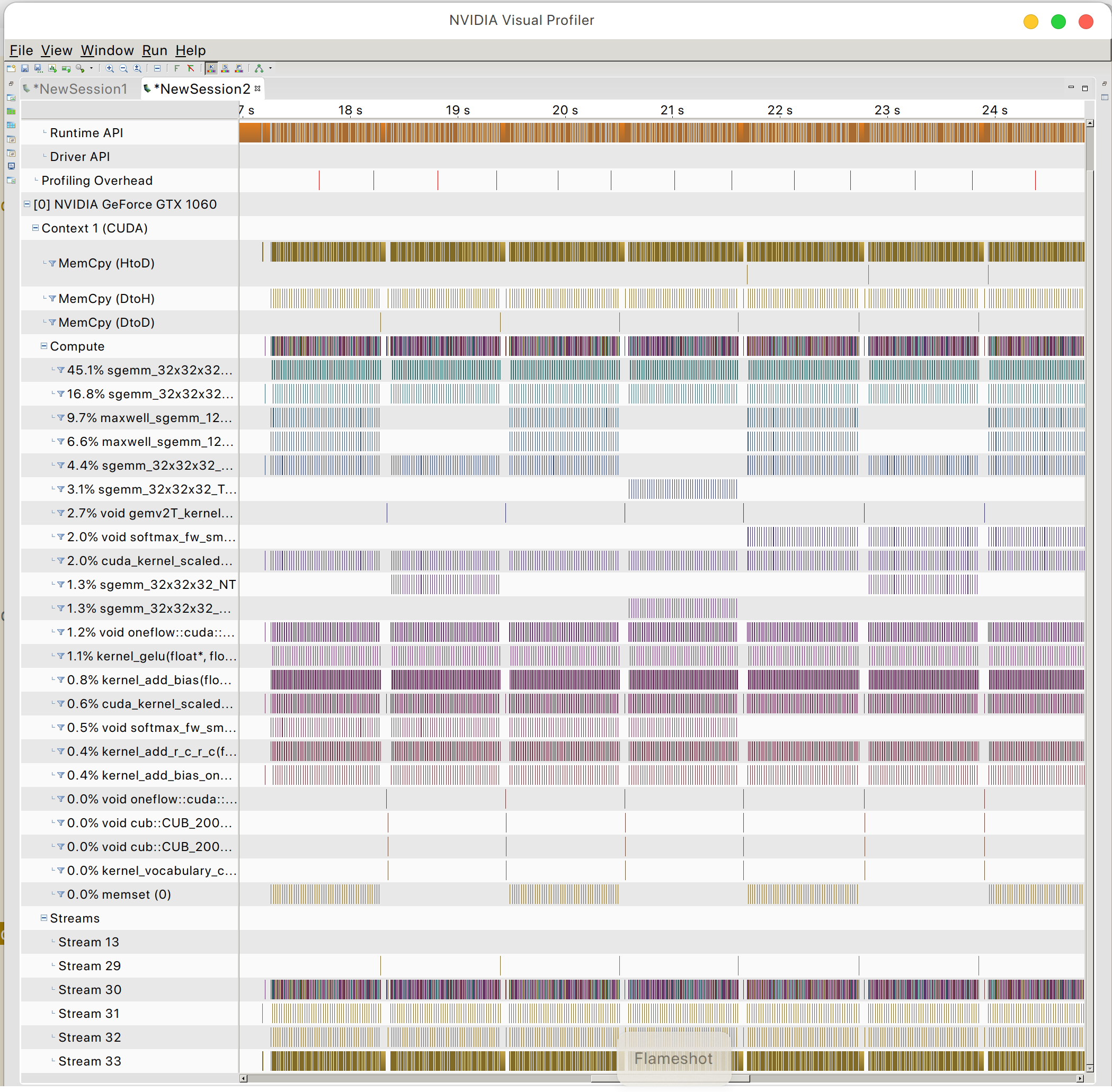
And you can find the GPU memory access pattern
PeaceOSL