minimind
V1

Chinese | English
This open source project aims to start from scratch, in as little as 3 hours! You can train MiniMind, a miniature language model with a size of only 26.88M.
MiniMind is extremely lightweight, and the smallest version is about the size of GPT3
MiniMind released a large model minimalist structure, data set cleaning and preprocessing, supervised pretraining (Pretrain), supervised instruction fine-tuning (SFT), low-rank adaptive (LoRA) fine-tuning, and reward-free reinforcement learning direct preference alignment (DPO) The full-stage code also includes the expansion of the sparse model of shared hybrid experts (MoE); the expansion of visual multi-modal VLM: MiniMind-V.
This is not only an implementation of an open source model, but also a tutorial for getting started with large language models (LLM).
We hope that this project can provide researchers with an introductory example to help everyone get started quickly and generate more exploration and innovation in the field of LLM.
To prevent misunderstanding, "up to 3 hours" means that you need a machine with >my own hardware configuration. Details of the specific specifications will be provided below.

ModelScope online test | Bilibili video link
In the field of large language models (LLM), such as GPT, LLaMA, GLM, etc., although their effects are amazing, the huge model parameters of 10 Bilion and the memory of personal devices are far from enough for training, and even inference is difficult. Almost everyone is not satisfied with just fine-tuing large models using programs such as Lora to learn some new instructions. This is about the same as teaching Newton to play with a 21st century smartphone. However, this is far away from learning the mysteries of physics itself. In addition, the marketing accounts selling paid subscription courses are full of loopholes and tutorials explaining AI with only half-knowledge, which makes it even more difficult to understand the high-quality content of LLM and seriously hinders learners.
Therefore, the goal of this project is to infinitely lower the threshold for getting started with LLM and train an extremely lightweight language model directly from scratch.
Tip
(As of 2024-9-17) The MiniMind series has completed pre-training of 3 models of models. The minimum required is only 26M (0.02B) to have smooth conversation capabilities!
| Model (size) | tokenizer length | reasoning occupancy | release | Subjective rating (/100) |
|---|---|---|---|---|
| minimind-v1-small (26M) | 6400 | 0.5 GB | 2024.08.28 | 50' |
| minimind-v1-moe (4×26M) | 6400 | 1.0 GB | 2024.09.17 | 55' |
| minimind-v1 (108M) | 6400 | 1.0 GB | 2024.09.01 | 60' |
The analysis was performed on a 2×RTX 3090 GPU with Torch 2.1.2, CUDA 12.2, and Flash Attention 2.
Project includes:
transformers , accelerate , trl , peft , etc.I hope this open source project can help LLM beginners get started quickly!
Expands MiniMind's multi-modal capabilities - vision
Move to the twin project minimind-v to view details!
09-27 Updated the preprocessing method of the pretrain data set. In order to ensure the integrity of the text, the preprocessing was abandoned and converted into .bin training (slightly sacrificing training speed).
The current file after pretrain processing is named: pretrain_data.csv.
Removed some redundant code.
Update minimind-v1-moe model
In order to prevent ambiguity, mistral_tokenizer is no longer used as word segmentation, and all custom minimind_tokenizer is used as word segmentation.
Updated minimind-v1 (108M) model, using minimind_tokenizer, pre-training rounds 3 + SFT rounds 10, more fully trained and stronger performance.
The project has been deployed to the ModelScope creation space and can be experienced on this website:
?ModelScope online experience?
This is just my personal software and hardware environment configuration, please change it at your own discretion:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练MiniMind (HuggingFace)
MiniMind (ModelScope)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.pyOr start streamlit and start the web chat interface
"Note" requires python>=3.10, install
pip install streamlit==1.27.2
# or step 3, use streamlit
streamlit run fast_inference.py0. Clone project code
git clone https://github.com/jingyaogong/minimind.git
cd minimind1. Environment installation
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
If it is not available, please go to torch_stable to download the whl file and install it yourself. Reference link
2. If you need to train yourself
2.1 Download the data set download address and place it in ./dataset directory.
2.2 python data_process.py processes data sets. For example, pretrain data is token-encodered in advance, and sft data sets are extracted from qa to csv files.
2.3 Adjust the model parameter configuration in ./model/LMConfig.py
Here you only need to adjust the dim, n_layers and use_moe parameters, which are
(512+8)or(768+16)respectively, corresponding tominimind-v1-smallandminimind-v1
2.4 python 1-pretrain.py performs pre-training and gets pretrain_*.pth as the output weight of pre-training
2.5 python 3-full_sft.py executes instruction fine-tuning and obtains full_sft_*.pth as the output weight of instruction fine-tuning
2.6 python 4-lora_sft.py performs lora fine-tuning (not required)
2.7 python 5-dpo_train.py performs DPO human preference reinforcement learning alignment (optional)
3. Test the model reasoning effect
*.pth files that need to be used and completed training are located in the ./out/ directory.*.pth weight file. minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py tests the solitaire effect of the pre-trained modelpython 2-eval.py tests the dialogue effect of the model 
?"Tip" pre-training and full parameter fine-tuning pretrain and full_sft both support multi-card acceleration
Assuming that your device only has one graphics card, just use native python to start training:
python 1-pretrain.py
# and
python 3-full_sft.pyAssume your device has N (N>1) graphics cards:
Stand-alone N card startup training (DDP)
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.pyStandalone N card startup training (DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.pyEnable wandb to record the training process (optional)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb By adding the --use_wandb parameter, the training process can be recorded. After the training is completed, the training process can be viewed on the wandb website. By modifying wandb_project and wandb_run_name parameters, you can specify the project name and run name.
? Tokenizer: The Tokenizer in nlp is similar to a dictionary. It maps words from natural language to numbers such as 0, 1, and 36 through the "dictionary". It can be understood that the number represents the page number of the word in the "dictionary". There are two ways to build an LLM tokenizer: one is to construct a word list yourself to train a tokenizer, the code can be found train_tokenizer.py ; the other is to select a tokenizer trained by an open source model. Of course, you can directly choose Xinhua Dictionary or Oxford Dictionary for "dictionary". The advantage is that the token conversion compression rate is very good, but the disadvantage is that the vocabulary list is too long, with hundreds of thousands of vocabulary phrases. You can also use your own trained word segmenter. The advantage is that The word list can be controlled at will. The disadvantage is that the compression rate is not ideal enough, and it is not easy to cover all rare words. Of course, the choice of "dictionary" is important. The output of LLM is essentially a multi-classification problem of N words from SoftMax to the dictionary, and then decoded into natural language through the "dictionary". Because the LLM is very small, in order to avoid the model being top-heavy (the ratio of word embedding layer parameters to the entire LLM is too high), the vocabulary length needs to be chosen to be relatively small. Powerful open source models such as 01 Wanwu, Qianwen, chatglm, mistral, Llama3, etc. have the following tokenizer vocabulary lengths:
| Tokenizer model | Vocabulary size | source |
|---|---|---|
| yi tokenizer | 64,000 | 01 Everything (China) |
| qwen2 tokenizer | 151,643 | Alibaba Cloud (China) |
| glm tokenizer | 151,329 | Wisdom AI (China) |
| mistral tokenizer | 32,000 | Mistral AI (France) |
| llama3 tokenizer | 128,000 | Meta (United States) |
| minimind tokenizer | 6,400 | Customize |
Update 2024-09-17: In order to prevent ambiguity and control volume in past versions, all minimind models use minimind_tokenizer word segmentation and all mistral_tokenizer versions are abandoned.
Although the length of minimind_tokenizer is very small, the encoding and decoding efficiency is weaker than Chinese-friendly tokenizers such as qwen2 and glm. However, the minimind model chose its own trained minimind_tokenizer as the word segmenter to keep the overall parameters lightweight and avoid an imbalance in the proportion of the coding layer and the calculation layer, which is top-heavy, because the vocabulary size of minimind is only 6400. In addition, minimind has not failed to decode rare words in actual tests, and the results are good. Since the custom word list is compressed to 6400 words, the total parameter size of LLM is as low as 26M.
?[Pretrain data]: Seq-Monkey universal text data set/Seq-Monkey Baidu network disk is compiled and cleaned from a variety of public source data (such as web pages, encyclopedias, blogs, open source codes, books, etc.). It is organized into a unified JSONL format and has undergone strict screening and deduplication to ensure the comprehensiveness, scale, credibility and high quality of the data. The total amount is about 10B tokens, which is suitable for pre-training of Chinese large language models.
Option 2: The publicly accessible portion of the SkyPile-150B dataset contains approximately 233 million unique web pages, each containing an average of more than 1,000 Chinese characters. The dataset includes approximately 150 billion tokens and 620GB of plain text data. If you are in a hurry , you can try to only select part of the jsonl download of SkyPile-150B (and generate a *.csv file for the text tokenizer in ./data_process.py) to quickly run through the pre-training process.
Download to ./dataset/ directory
| MiniMind training data set | Download address |
|---|---|
| [tokenizer training set] | HuggingFace / Baidu Netdisk |
| 【Pretrain data】 | Seq-Monkey official/Baidu network disk/HuggingFace |
| 【SFT data】 | Jiangshu large model SFT data set |
| 【DPO data】 | Hugging face |
MiniMind-Dense (same as Llama3.1) uses the Decoder-Only structure of Transformer. The difference from GPT-3 is:
MiniMind-MoE model, its structure is based on Llama3 and the MixFFN hybrid expert module in Deepseek-V2.
The overall structure of MiniMind is the same, except for some minor adjustments in the code of RoPE calculation, inference function and FFN layer. Its structure is as follows (redrawn version):
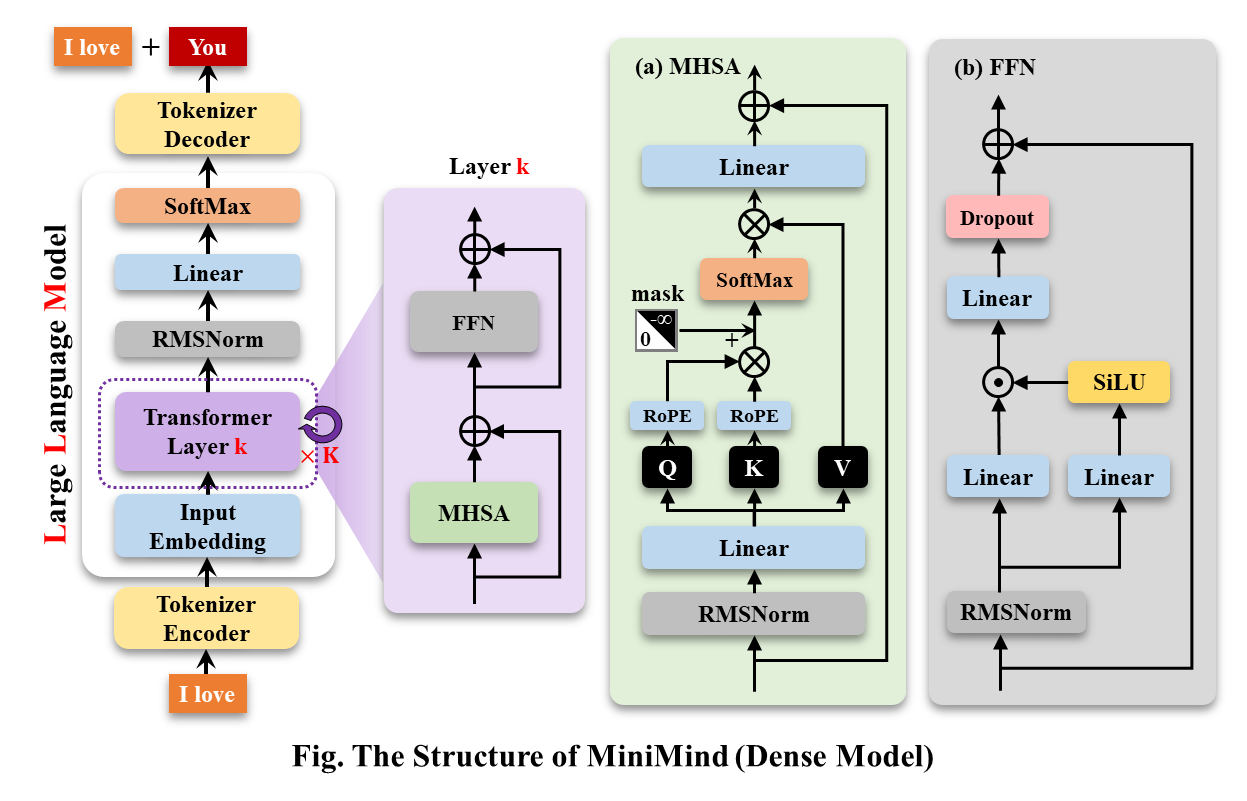
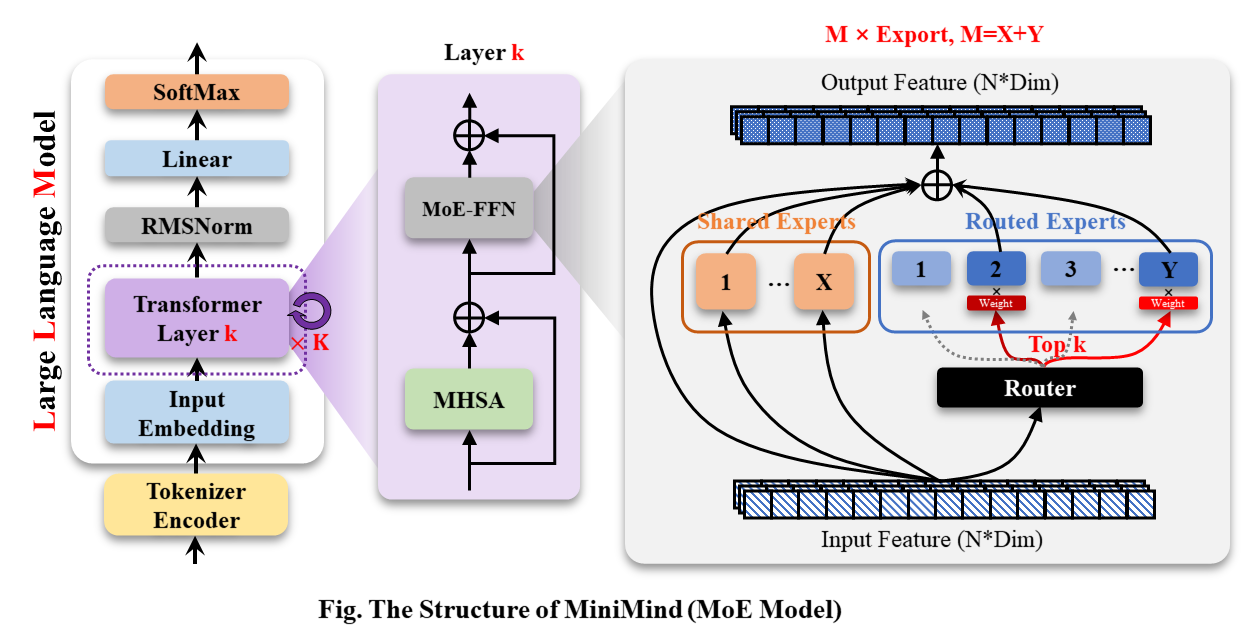
To modify the model configuration, see ./model/LMConfig.py. The model versions currently trained by minimind are shown in the table below:
| Model Name | params | len_vocab | n_layers | d_model | kv_heads | q_heads | share+route | TopK |
|---|---|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimind-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| minimind-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
| Model Name | params | len_vocab | batch_size | pretrain_time | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | 6400 | 64 | ≈2 hours (1 epoch) | ≈2 hours (1 epoch) | ≈0.5 hour (1 epoch) |
| minimind-v1-moe | 4×26M | 6400 | 40 | ≈6 hours (1 epoch) | ≈5 hours (1 epoch) | ≈1 hour (1 epoch) |
| minimind-v1 | 108M | 6400 | 16 | ≈6 hours (1 epoch) | ≈4 hours (1 epoch) | ≈1 hour (1 epoch) |
Pre-training (Text-to-Text) :
The learning rate of pretrain is set to a dynamic learning rate from 1e-4 to 1e-5, and the number of pretraining epochs is set to 5.
torchrun --nproc_per_node 2 1-pretrain.pySingle dialog Fine-tuning :
By adjusting the RoPE linear difference during inference, it is convenient to extrapolate the length to 1024 or 2048 and above. The learning rate is set to a dynamic learning rate from 1e-5 to 1e-6, and the number of fine-tuning epochs is 6.
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.pyMulti dialog Fine-tuning :
The learning rate is set to a dynamic learning rate from 1e-5 to 1e-6, and the number of fine-tuning epochs is 5.
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.pyHuman Feedback Reinforcement Learning (RLHF) - Direct Preference Optimization (DPO) :
Movable type triplet (q, choose, reject) data set, learning rate le-5, half-precision fp16, a total of 1 epoch, and takes 1 hour.
python 5-dpo_train.py ? Regarding the parameter configuration of LLM, there is a very interesting paper MobileLLM that does detailed research and experiments. Scaling law has its own unique rules in small models. The parameters that cause the Transformer parameters to scale depend almost exclusively on d_model and n_layers .
d_model ↑+ n_layers ↓->Humpty Dumptyd_model ↓+ n_layers ↑->slim and tall The paper proposing Scaling Law in 2020 believes that the amount of training data, the amount of parameters, and the number of training iterations are the key factors that determine performance, and the impact of the model architecture can almost be ignored. However, it seems that this law does not fully apply to small models. MobileLLM proposes that the depth of the architecture is more important than the width. The "deep and narrow" "slender" model can learn more abstract concepts than the "wide and shallow" model. For example, when the model parameters are fixed at 125M or 350M, the "narrow" model with 30 to 42 layers has significantly better performance than the "short and fat" model with about 12 layers, in 8 benchmark tests such as common sense reasoning, question and answer, and reading comprehension. There are similar trends. This is actually a very interesting discovery, because in the past, when designing architectures for small models of about 100M, almost no one had tried to stack more than 12 layers. This is consistent with the experimentally observed effect of MiniMind adjusting the model parameters between d_model and n_layers during the training process. However, the "narrow" of "deep and narrow" also has a dimension limit. When d_model<512, the disadvantage of word embedding dimensionality collapse is very obvious. The added layers cannot make up for the disadvantage of insufficient d_head caused by word embedding in fixed q_head. When d_model>1536, the increase of layers seems to have a higher priority than d_model, and can bring more "cost-effective" parameters -> effect gain. Therefore, MiniMind sets the d_model=512 and n_layers=8 of the small model to obtain the balance of "very small volume <-> better effect". Set d_model=768, n_layers=16 to obtain greater benefits from the effect, which is more in line with the changing curve of scaling-law of small models.
For reference, the parameter settings of GPT3 are shown in the table below:
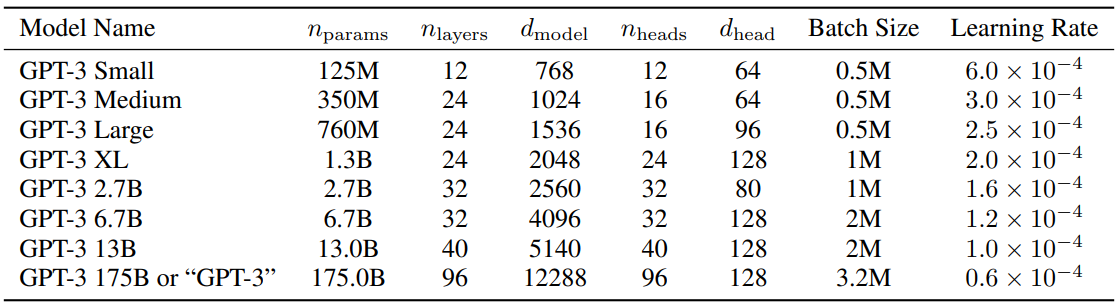
?Baidu Netdisk
| Model Name | params | Config | pretrain_model | single_sft_model | multi_sft_model | rl_model |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | d_model=512 n_layers=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| minimind-v1-moe | 4×26M | d_model=512 n_layers=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| minimind-v1 | 108M | d_model=768 n_layers=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
Tip
Test the minimind model comparison based on "single-round dialogue full_sft" and "DPO reinforcement learning alignment".
Model file Baidu Netdisk, where rl_<dim>.pth is the minimind model weight after "DPO reinforcement learning alignment".
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
Tip
The following test was completed on 2024-09-17. New models released after this date will not be included in the test unless there are special needs. Test the minimind model based on single-round dialogue full_sft (without multi-round fine-tuning and reinforcement learning fine-tuning).
[A] minimind-v1-small(0.02B)
[B] minimind-v1-moe(0.1B)
[C] minimind-v1(0.1B)
[D] baby-llama2-chinese(0.2B)
[E] chatlm-mini-chinese(0.2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
Note
?♂️ Directly throw the answer of the above model to GPT-4o and let it help score:
Model A :
Model B :
Model C :
Model D :
Model E :
| Model | C | E | B | A | D |
|---|---|---|---|---|---|
| Fraction | 75 | 70 | 65 | 60 | 50 |
The sorting of the minimind series (ABC) is in line with intuition, and minimind-v1 (0.1B) has the highest score. The answers to common sense questions are basically free of errors and illusions.
epochs of minimind-v1 (0.1B) is less than 2. I am too lazy to kill in advance to free up resources for the small model. 0.1B still achieves the strongest performance even though it has not been fully trained. In fact, it is still one level higher than the previous one. dead.The E model's answer looks very good to the naked eye, although there are some hallucinations and fabrications. However, both GPT-4o and Deepseek’s ratings agreed that it had “overly lengthy information, repeated content, and illusions.” In fact, this kind of evaluation is a bit strict. Even if 10 words out of 100 are hallucinations, it will easily be assigned a low score. Since the pre-training text length of the E model is longer and the data set is much larger, the answers appear to be complete. In the case of volume approximation, both data quantity and quality are important.
?♂️Personal subjective evaluation: E>C>B≈A>D
? GPT-4o rating: C>E>B>A>D
Scaling Law: The larger the model parameters and the more training data, the stronger the performance of the model.
See the C-Eval evaluation code: ./eval_ceval.py . In order to avoid the difficulty of fixing the reply format, the evaluation of small models usually directly determines the prediction probability of the token corresponding to the four letters A , B , C , and D , and takes the largest one. Answer the answer and calculate the accuracy rate with the standard answer. The minimind model itself did not use a larger data set for training, nor did it fine-tune the instructions for answering multiple-choice questions. The evaluation results can be used as a reference.
For example, the result details of minimind-small:
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | twenty one | twenty two | twenty three | twenty four | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data | probability_and_statistics | law | middle_school_biology | high_school_chemistry | high_school_physics | legal_professional | high_school_chinese | high_school_history | tax_accountant | modern_chinese_history | middle_school_physics | middle_school_history | basic_medicine | operating_system | logic | electrical_engineer | civil_servant | chinese_language_and_literature | college_programming | accountant | plant_protection | middle_school_chemistry | metrology_engineer | veterinary_medicine | marxism | advanced_mathematics | high_school_mathematics | business_administration | mao_zedong_thought | ideological_and_moral_cultivation | college_economics | professional_tour_guide | environmental_impact_assessment_engineer | computer_architecture | urban_and_rural_planner | college_physics | middle_school_mathematics | high_school_politics | physician | college_chemistry | high_school_biology | high_school_geography | middle_school_politics | clinical_medicine | computer_network | sports_science | art_studies | teacher_qualification | discrete_mathematics | education_science | fire_engineer | middle_school_geography |
| Type | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | twenty one | twenty two | twenty three | twenty four | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T/A | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
| Accuracy | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| category | correct | question_count | accuracy |
|---|---|---|---|
| minimind-v1-small | 344 | 1346 | 25.56% |
| minimind-v1 | 351 | 1346 | 26.08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
./export_model.py can export the model to transformers format and push it to huggingface
MiniMind’s huggingface collection address: MiniMind
my_openai_api.py completes the chat interface of openai_api, making it easy to connect your own models to third-party UIs such as fastgpt, OpenWebUI, etc.
Download the model weight file from Huggingface
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
Start the chat server
python my_openai_api.pyTest service interface
python chat_openai_api.pyAPI interface example, compatible with openai api format
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
Tip
If you feel that MiniMind is helpful to you, you can add an article on GitHub. The length is not short and the level is limited. Omissions are inevitable. You are welcome to exchange corrections in Issues or submit PR improvement projects. Your support is the driving force for continuous improvement of the project.
Note
Everyone adds fuel to the flames. If you have tried to train a new MiniMind model, you are welcome to share your model weights in Discussions or Issues. It can be in specific downstream tasks or vertical fields (such as emotion recognition, medical, psychological, financial, legal question and answer, etc. ) MiniMind new model version It can also be a new MiniMind model version after extended training (such as exploring longer text sequences, larger volumes (0.1B+), or larger data sets). Any sharing is considered unique, and all attempts are valuable and encouraged. These contributions will be discovered in time and organized in the acknowledgment list. Thank you again for all your support!
@ipfgao : ?Training step record
@chuanzhubin : ? Code comments line by line
@WangRongsheng : ?Preprocessing of large data sets
@pengqianhan : ?A concise tutorial
@RyanSunn : ?Learning record of reasoning process
This repository is licensed under the Apache-2.0 License.


