BestYOLO is a best YOLO practice framework oriented by scientific research and competition!
At present, BestYOLO is an open source library that is completely improved based on YOLOv5 v7.0. The library will always be oriented towards practical applications, aiming at portability and ease of use, and will simplify the improvement of various modules. Currently, the YOLOv5 target detection algorithm based on torchvision.models model Backbone has been integrated, and more YOLOv5 applications will gradually be open sourced.
?improve
- Backbone-ResNet18 aligns with resnet18
- Backbone-RegNet_y_400mf align regnet_y_400mf
- Backbone-MobileNetV3 small align mobilenet_v3_small
- Backbone-EfficientNet_B0 aligned efficientnet_b0
- Backbone-ResNet34 aligns with resnet34
- Backbone-ResNet50 align resnet50
- Backbone-EfficientNetV2_s aligned efficientnet_v2_s
- Backbone-EfficientNet_B1 aligned efficientnet_b1
- Backbone-MobileNetV2 aligns with mobilenet_v2
- Backbone-wide_resnet50_2 align wide_resnet50_2
- Backbone-VGG11_BN align vgg11_bn
- Backbone-Convnext Tiny align convnext_tiny
All Backbone models support enabling pretrained weights by adding pretrained=True to each common.py model. The pre-trained weights in torchvision.models are all trained based on the ImageNet-1K data set!
| models | layers | parameters | model size(MB) |
|---|
| yolov5n | 214 | 1766623 | 3.9 |
| MobileNetV3s | 313 | 2137311 | 4.7 |
| efficientnet_b0 | 443 | 6241531 | 13.0 |
| RegNety400 | 450 | 5000191 | 10.5 |
| ResNet18 | 177 | 12352447 | 25.1 |
| ResNet34 | 223 | 22460607 | 45.3 |
| ResNet50 | 258 | 27560895 | 55.7 |
| EfficientNetV2_s | 820 | 22419151 | 45.8 |
| efficientnet_b1 | 539 | 6595615 | 13.8 |
| mobilenet_v2 | 320 | 4455295 | 9.4 |
| wide_resnet50_2 | 258 | 70887103 | 142.3 |
| vgg11_bn | 140 | 10442879 | 21.9 |
| convnext_tiny | 308 | 29310175 | 59.0 |
You can try setting depth_multiple and width_multiple in the .yaml configuration file to 1 at the same time, maybe it will have good results.
SPP is spatial pyramid pooling, which is used to achieve an adaptive size output. (The output size of traditional pooling layers such as maximum pooling and average pooling is linked to the input size, but when we finally make a fully connected layer to implement classification, we need to specify the fully connected input, so we need a way to let the neural network The network obtains a fixed-dimensional output at a certain layer, and this method is best not to resize (resize will cause distortion), so SPP came into being. It was first proposed by He Kaiming and applied to the RCNN model). Today's SPP has developed into today's Multi-Scale-ROI-Align on faster-rcnn, and has developed into SPPF on Yolo.
- yolov5n(SPPF)
- yolov5n-SPP
- yolov5n-SimSPPF
- yolov5n-ASPP
- yolov5n-RFB
- yolov5n-SPPCSPC
- yolov5n-SPPCSPC_group
- yolov5n-SimCSSPSPPF
| models | layers | parameters |
|---|
| yolov5n(SPPF) | 214 | 1766623 |
| yolov5n-SPP | 217 | 1766623 |
| yolov5n-SimSPPF | 216 | 1766623 |
| yolov5n-ASPP | 214 | 3831775 |
| yolov5n-RFB | 251 | 1932287 |
| yolov5n-SPPCSPC | 232 | 3375071 |
| yolov5n-SPPCSPC_group | 232 | 2047967 |
| yolov5n-SimCSSPSPPF | 229 | 3375071 |
- yolov5n
- yolov5n-FPN-AC
- yolov5n-PAN-AC
- yolov5n-FPN+PAN-AC
- yolov5n-FPN-AS
- yolov5n-PAN-AS
- yolov5n-FPN+PAN-AS
| models | layers | parameters |
|---|
| yolov5n | 214 | 1766623 |
| yolov5n-FPN-AC | 188 | 1858399 |
| yolov5n-PAN-AC | 186 | 1642591 |
| yolov5n-FPN+PAN-AC | 160 | 1734367 |
| yolov5n-FPN-AS | 204 | 2106847 |
| yolov5n-PAN-AS | 194 | 1891039 |
| yolov5n-FPN+PAN-AS | 184 | 2231263 |
- Optimal Transport Assignment
- Assisted training Optimal Transport Assignment
- Soft-NMS
Do not use Soft-NMS for training. It takes too long. Please enable it in val stage. It is suitable for small target overlapping data.
- Decoupled-head
- DCNv2
- WBF
- DCNv3
- NWD
application
TFjs deployment and use
TensorRT deploys YOLOv5
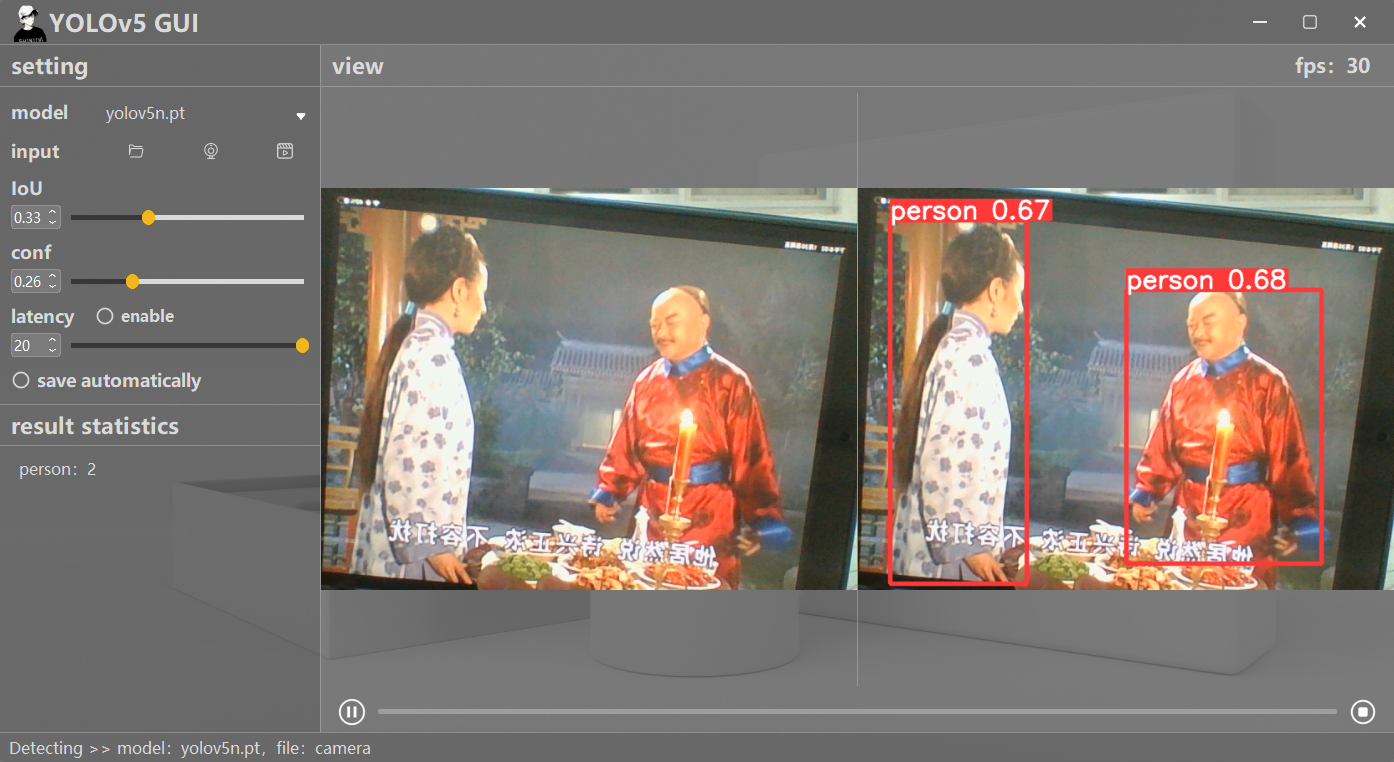
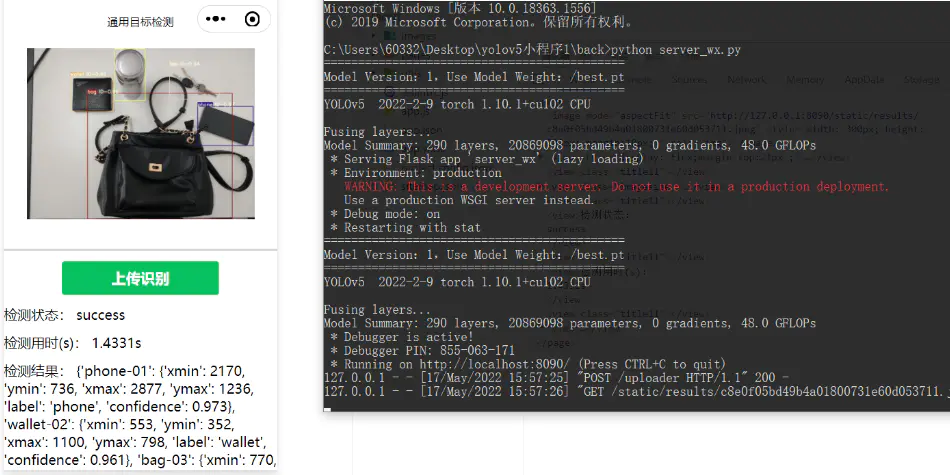
Pyqt GUI usage
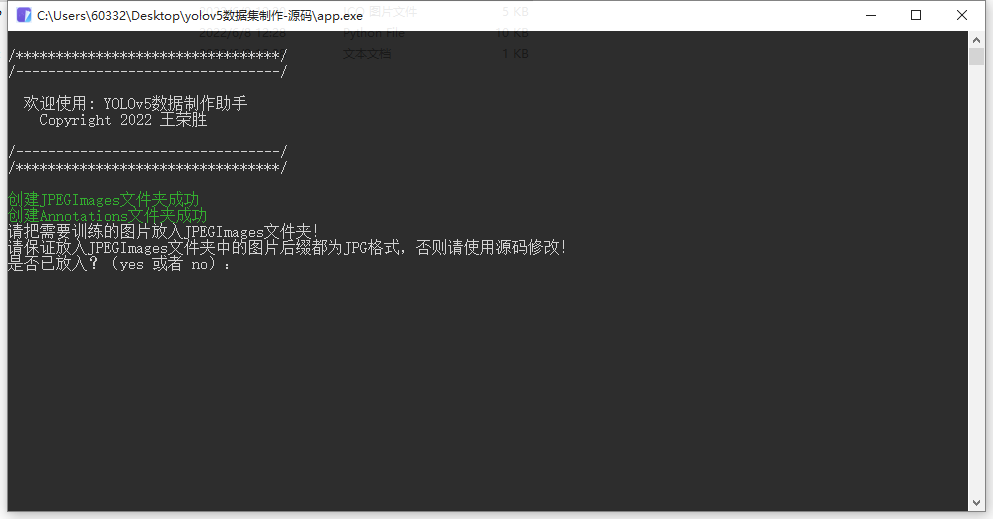
- YOLOv5 data set production assistant
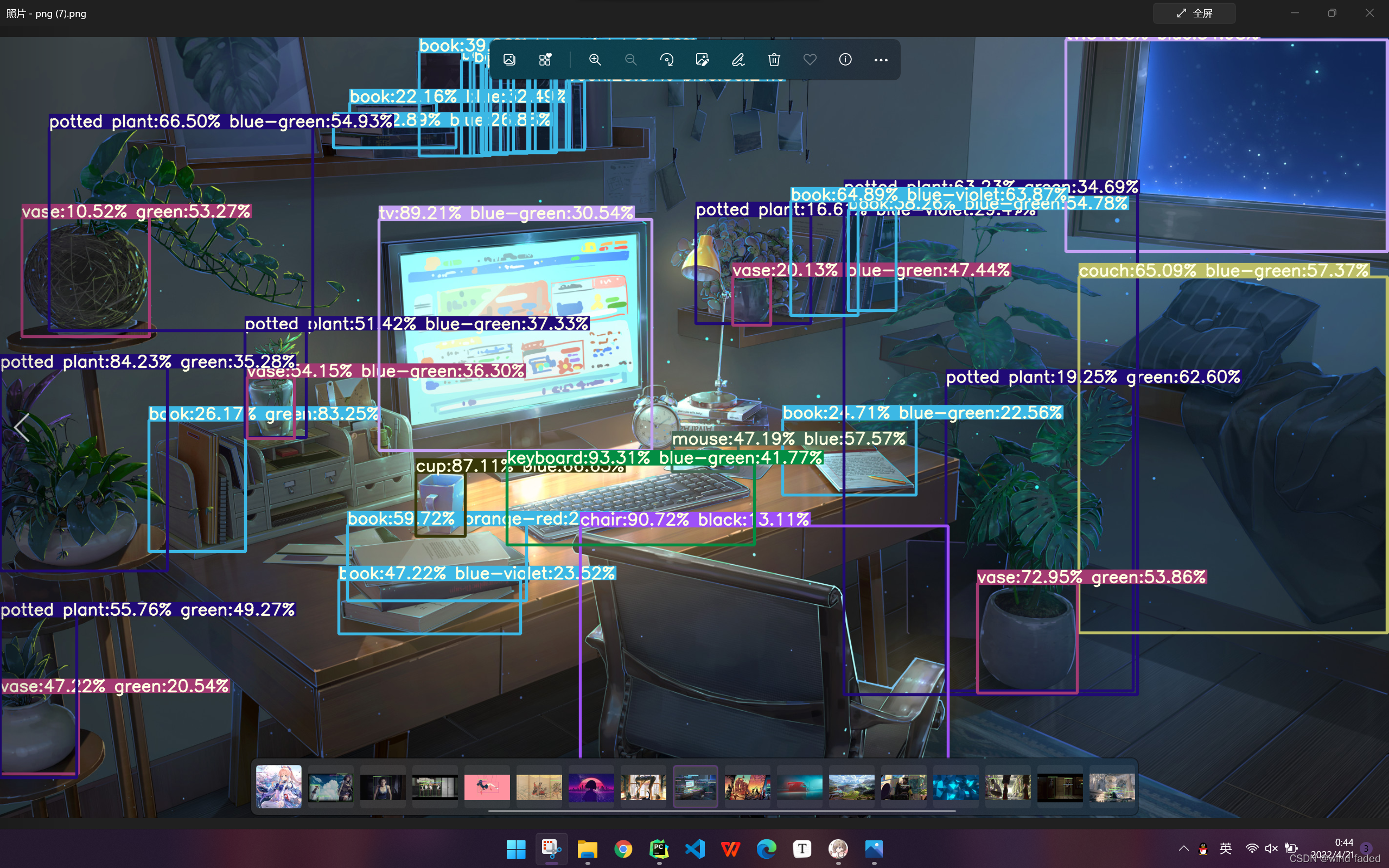
- YOLOv5 single box multiple labels
?Skill
- YOLOv5 model training and testing and multi-terminal deployment teaching content
- Understand YOLOv5-OneFlow implementation from zero to one
- YOLOV5 FPS calculation problem
- Introduction to the Neck module of the YOLO series
- Detailed explanation of YOLOv5 data enhancement (hyp.scratch-low.yaml and augmentations.py)
- Any version of YOLOv5 adds Grad-CAM heat map visualization
- Model weight encryption and decryption method trained by YOLOv5
- YOLOv5 series: 6. Modify Soft-NMS, Soft-CIoUNM...
- YOLOv5 series: Spatial pyramid pooling improves SPPF/SPPFCSPC...
- YOLOv5 | Independent self-attention layer for visual tasks
- YOLOv5 project code encryption
- YOLOv5: Add missed detection rate and false detection rate output
- YOLOv5 analysis | Draw results.csv file data comparison chart
- Tricks of YOLOv5-image sampling strategy-sampling according to the weight of each category of the data set
- How YOLOv5 performs regional target detection (step-by-step tutorial)
- A comprehensive review of 2D target detection papers (37 articles)
- I read more than 30 Chinese core journals that improved YOLO overnight.
- A collection of core papers on CNKI's latest improvements to YOLO | A quick overview of 22 innovations
- Small target detection killer: yolov5-pip and sahi
- The big killer of small target detection: cramming data enhancement
It should be noted that training and inference data remain in the same data form, that is, you cannot train through non-cut graphs and infer based on cut graphs!
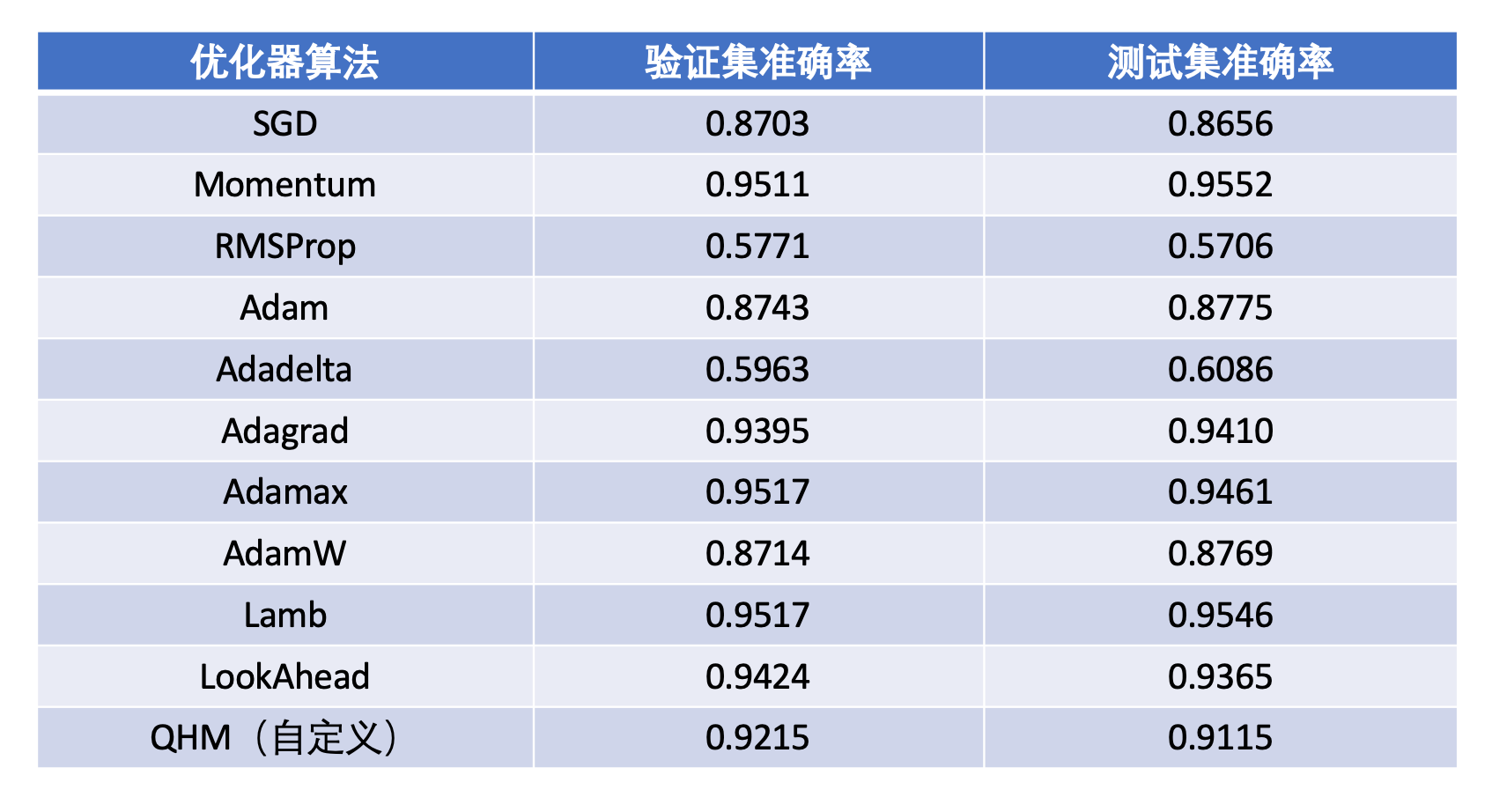
- An immature optimizer selection reference:
?refer to
- https://github.com/ultralytics/yolov5/tree/v7.0
- https://github.com/ppogg/YOLOv5-Lite
- https://github.com/deepcam-cn/yolov5-face
- https://github.com/Gumpest/YOLOv5-Multibackbone-Compression
- https://github.com/jizhishutong/YOLOU
- https://github.com/Bobo-y/flexible-yolov5
- https://github.com/iscyy/yoloair
- https://github.com/WangQvQ/Yolov5_Magic
- https://github.com/Hongyu-Yue/yoloV5_modify_smalltarget
- https://github.com/wuzhihao7788/yolodet-pytorch
- https://github.com/iscyy/yoloair2
- https://github.com/positive666/yolo_research
- https://github.com/Javacr/PyQt5-YOLOv5
- https://github.com/yang-0201/YOLOv6_pro
- https://github.com/yhwang-hub/dl_model_deploy
- https://github.com/FeiYull/TensorRT-Alpha
- https://github.com/sjinzh/awesome-yolo-object-detection
- https://github.com/z1069614715/objectdetection_script
- https://github.com/icey-zhang/SuperYOLO
- https://github.com/akashAD98/awesome-yolo-object-detection
?Work
- https://github.com/cv516Buaa/tph-yolov5
- https://github.com/icey-zhang/SuperYOLO
- https://github.com/luogen1996/OneTeacher
- https://github.com/AlibabaResearch/efficientteacher
- https://github.com/YOLOonMe/EMA-attention-module
- https://github.com/maggiez0138/yolov5_quant_sample
- https://github.com/OutBreak-hui/YoloV5-Flexible-and-Inference
- https://github.com/Johnathan-Xie/ZSD-YOLO
- https://github.com/chengshuxiao/YOLOv5-ODConvNeXt
- https://github.com/LSH9832/edgeyolo
- https://github.com/Koldim2001/YOLO-Patch-Based-Inference
?Quote
@ article { 2023 bestyolo ,
title = {{ BestYOLO }: Making research and competition easier },
author = { Rongsheng Wang },
repo = { github https : // github . com / WangRongsheng / BestYOLO },
year = { 2023 }
} contribute