WeClone
1.0.0
Using WeChat chat records to fine-tune a large language model, I used about 20,000 pieces of integrated effective data. The final result can only be said to be unsatisfactory, but sometimes it is really funny.
Important
Currently, the project uses the chatglm3-6b model by default, and the LoRA method is used to fine-tune the sft stage, which requires approximately 16GB of video memory. You can also use other models and methods supported by LLaMA Factory, which take up less video memory. You need to modify the template's system prompt words and other related configurations yourself.
Estimated video memory requirements:
| training method | Accuracy | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| Full parameters | 16 | 160GB | 320GB | 600GB | 1200GB | 900GB |
| Some parameters | 16 | 20GB | 40GB | 120GB | 240GB | 200GB |
| LoRA | 16 | 16 GB | 32GB | 80GB | 160GB | 120GB |
| QLoRA | 8 | 10GB | 16 GB | 40GB | 80GB | 80GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 32GB |
| Required | At least | recommend |
|---|---|---|
| python | 3.8 | 3.10 |
| torch | 1.13.1 | 2.2.1 |
| transformers | 4.37.2 | 4.38.1 |
| datasets | 2.14.3 | 2.17.1 |
| accelerate | 0.27.2 | 0.27.2 |
| peft | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| Optional | At least | recommend |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.13.4 |
| bitsandbytes | 0.39.0 | 0.41.3 |
| flash-attn | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtTraining and inference related configurations are unified in the file settings.json
Please use PyWxDump to extract WeChat chat records. After downloading the software and decrypting the database, click Chat Backup. The export type is CSV. You can export multiple contacts or group chats. Then place the exported csv folder located at wxdump_tmp/export in the ./data directory, which is different. The folders of people's chat records are placed together in ./data/csv . The example data is located in data/example_chat.csv.
By default, the project removes mobile phone numbers, ID numbers, email addresses, and website addresses from the data. It also provides a database of banned words, blocked_words, where you can add words and sentences that need to be filtered (the entire sentence including the banned words will be removed by default). Execute the ./make_dataset/csv_to_json.py script to process the data.
When the same person answers multiple sentences in succession, there are three ways to handle it:
| document | Processing method |
|---|---|
| csv_to_json.py | Connect with commas |
| csv_to_json-single sentence answer.py (obsolete) | Only the longest answers are selected as final data |
| csv_to_json-single sentence multiple rounds.py | Placed in the 'history' of the prompt word |
The first choice is to download the ChatGLM3 model from Hugging Face. If you encounter problems downloading the Hugging Face model, you can use the MoDELSCOPE community through the following methods. For subsequent training and inference, you need to execute export USE_MODELSCOPE_HUB=1 first to use the model of the MoDELSCOPE community.
Due to the large size of the model, the downloading process will take a long time, please be patient.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(Optional) Modify settings.json to select other locally downloaded models.
Modify per_device_train_batch_size and gradient_accumulation_steps to adjust video memory usage.
You can modify parameters such as num_train_epochs , lora_rank , lora_dropout according to the quantity and quality of your own data set.
Run src/train_sft.py to fine-tune the sft stage. My loss only dropped to about 3.5. If it is reduced too much, it may cause over-fitting.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyNote
You can also fine-tune the pt stage first. It seems that the improvement effect is not obvious. The warehouse also provides the code for preprocessing and training of the pt stage data set.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyImportant
There is a risk of account closure on WeChat. It is recommended to use a small account and must bind a bank card to use it.
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py By default, the QR code is displayed on the terminal, just scan the code to log in. It can be used in private chat or in group chat @bot.
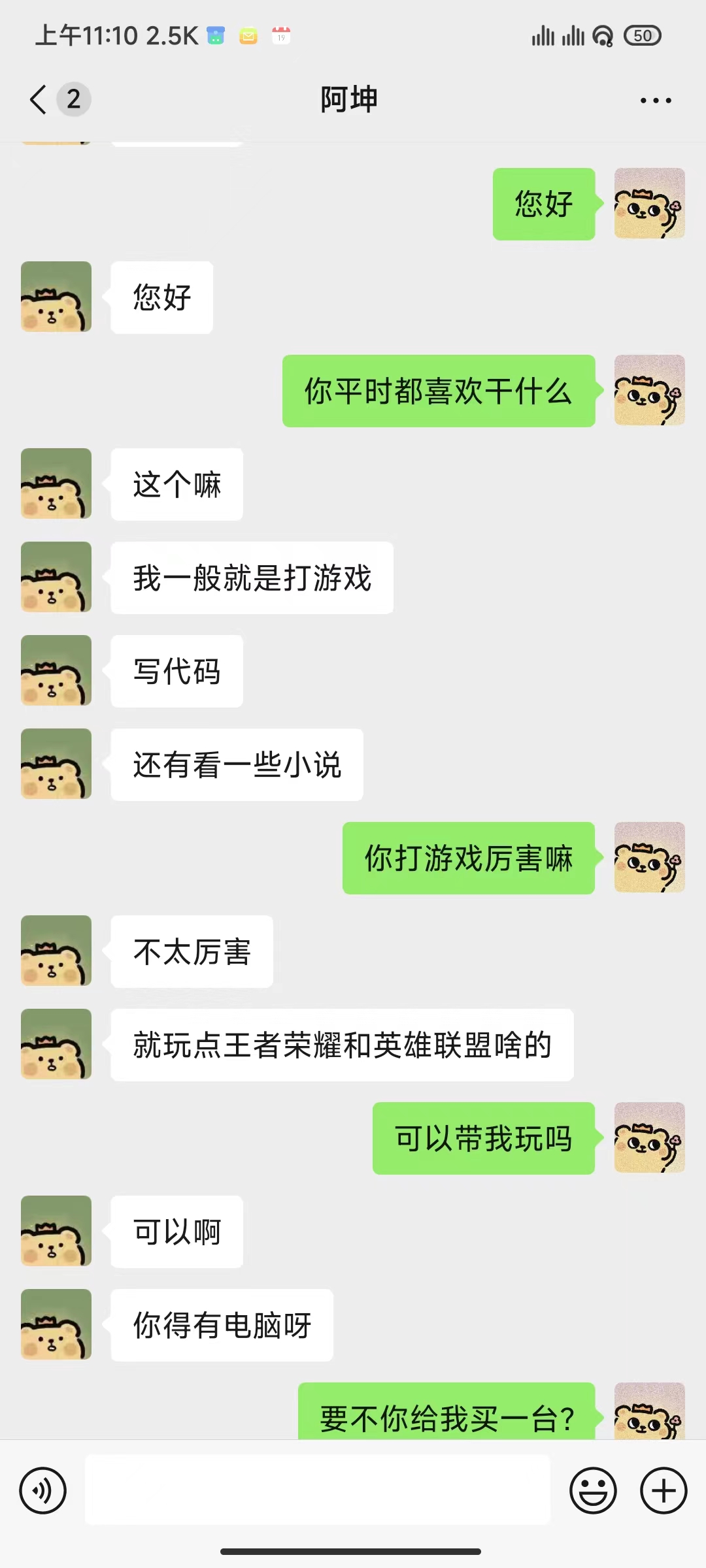

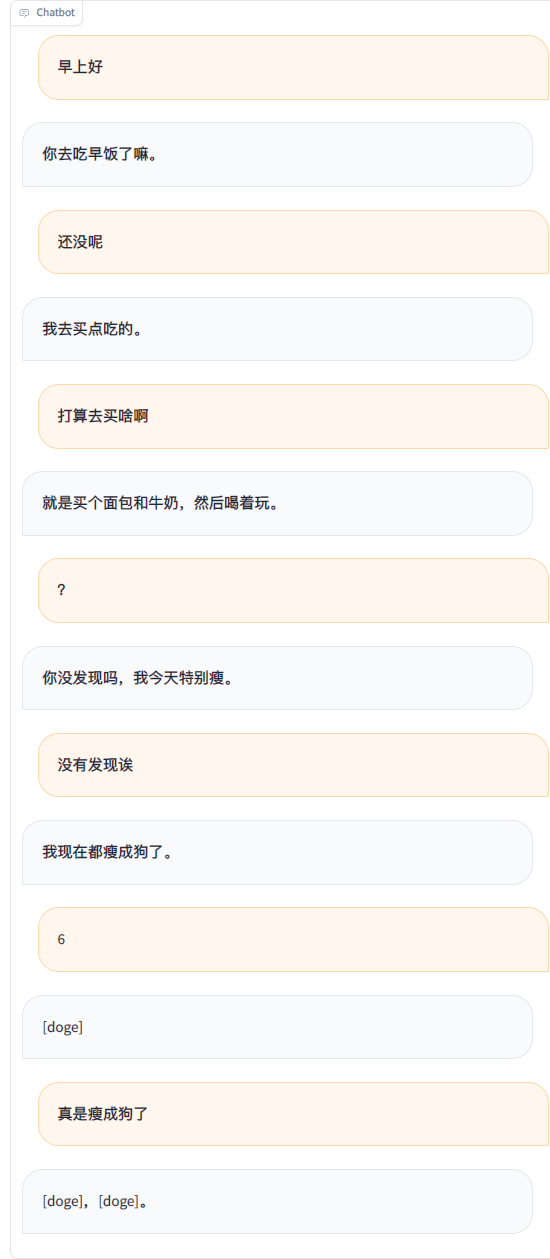
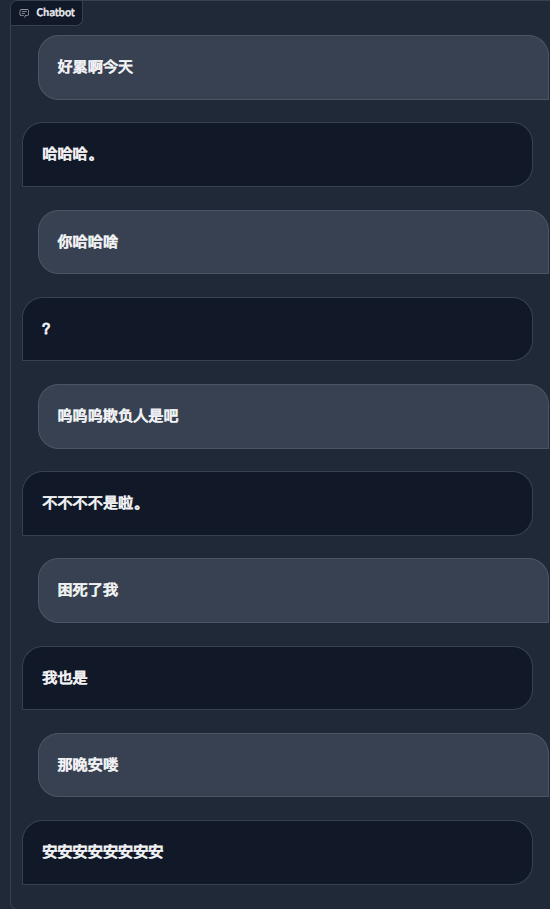
Todo
Todo


