liuli
v0.2.0
Just explain it briefly:
Collector : monitors customized reading sources such as public accounts, books or blog sources that they follow, and flows into Liuli in a unified standard format as an input source;
Processor : Customize the target content, such as using machine learning to automatically label an advertising classifier based on historical advertising data, or introducing hook functions to execute on relevant nodes;
Distributor : relies on the interface layer to perform data requests & responses, provides users with personalized configurations, and then automatically distributes according to the configuration, flowing clean articles to WeChat, DingTalk, TG, RSS clients and even self-built websites;
Backer : Back up the processed articles, such as persisting them to a database or GitHub, etc.
This achieves the construction of a clean reading environment. Derivatively, there are many things that can be done based on the obtained data. You may wish to spread your ideas.
Development progress dashboard:
v0.2.0: Implement basic functions to ensure that solutions for common scenarios can be applied
v0.3.0: Implement collector customization, users can collect what they see
In order to improve the recognition accuracy of the model, I hope everyone can contribute some advertising samples. Please see the sample file: .files/datasets/ads.csv. I set the format as follows:
| title | url | is_process |
|---|---|---|
| Advertisement article title | Advertisement article link | 0 |
Field description:
title: article title
url: article link. If you want to use WeChat article, please verify whether it is invalid first.
is_process: Indicates whether to perform sample processing. Fill in 0 by default.
Let’s give an example:
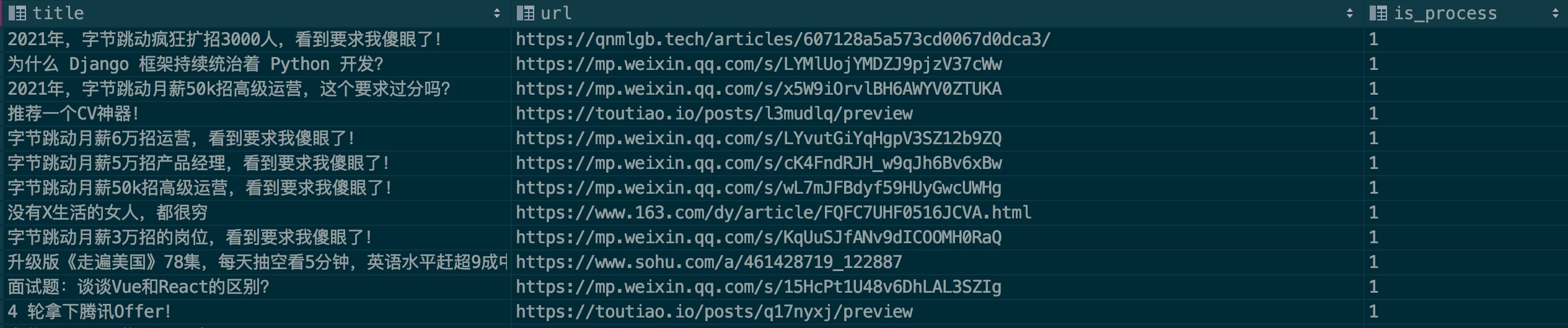
Generally, advertisements will be repeatedly placed on multiple public accounts. Please check whether this record exists when filling it out. I hope everyone can work together to contribute. Dear, come and contribute your strength through PR!
Thanks to the following open source projects:
Flask: web framework
Vue: Progressive JavaScript framework
Ruia: Asynchronous crawler framework (self-developed and used)
playwright: Data scraping using the browser
The above only lists the core open source dependencies. For more third-party dependencies, please see the Pipfile file.
Any PR you receive is a strong support for the Liuli project. We are very grateful to the following developers for their contributions (in no particular order):
Welcome to communicate together (follow the group):


