ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot is a chatGPT-like robot implemented using the dialogue model based on the official OpenAI API, and is deployed on WeChat through the Wechaty framework to realize robot chat.
ChatGPT WechatBot is a kind of chatGPT robot based on the OpenAI official API and using the dialogue model. It is deployed on WeChat through the Wechat framework to achieve robot chat.
Note : This project is a local Win10 implementation and does not require server deployment (if server deployment is required, you can deploy docker to the server)
(1), Windows10
(2), Docker 20.10.21
(3), Python3.9
(4), Wechaty 0.10.7
1. Download Docker
https://www.docker.com/products/docker-desktop/ Download Docker
2. Turn on Win10 virtualization
Enter control in cmd to open the control panel and enter the program, as shown in the figure below:
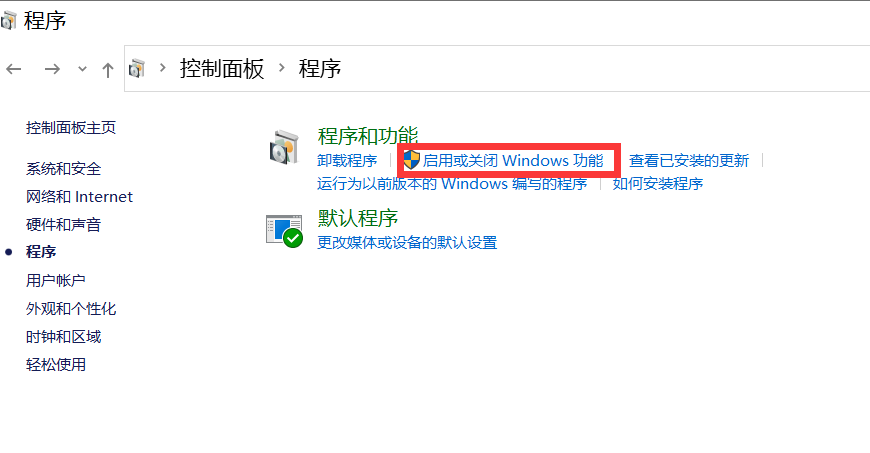
Go to Turn Windows features on or off and turn on Hyper-V
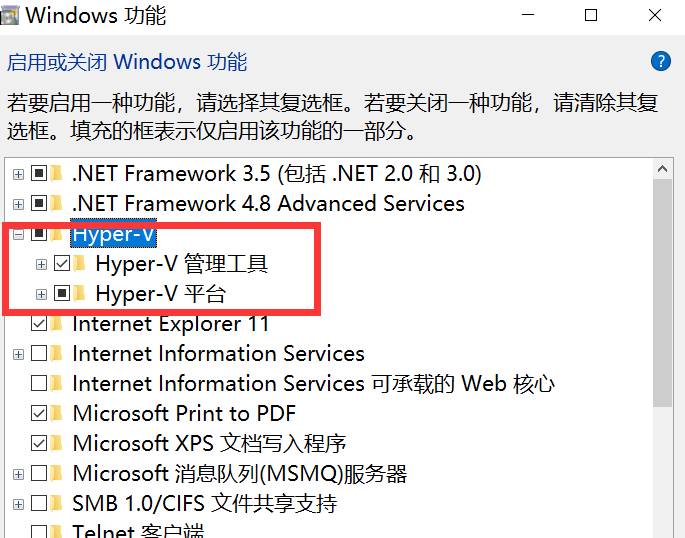
Note : If your computer does not have Hyper-V, you need to perform the following operations:
Create a text document, fill in the following code, and name it Hyper.cmd
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALLThen run this file as an administrator. After the script is finished running, there will be a Hyper-V node after restarting the computer.
3. Run Docker
Note : If the following occurs when running Docker for the first time:
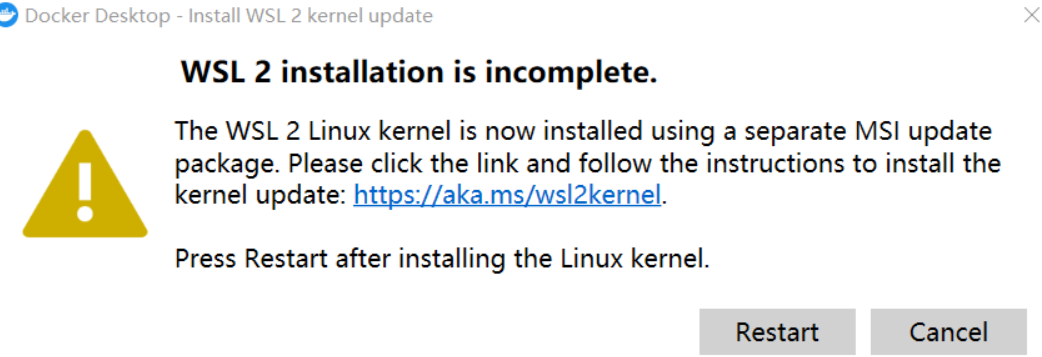
Need to download the latest WSL 2 package
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
After updating, you can enter the main page, then change the settings in the docker engine and replace the image with Alibaba Cloud's domestic image:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}This way, it is faster to pull out the mirror (for domestic users)
4. Pull the Wechaty image :
docker pull wechaty:0 . 65Because during testing, it was found that version 0.65 of wechaty is the most stable
After pulling the image:
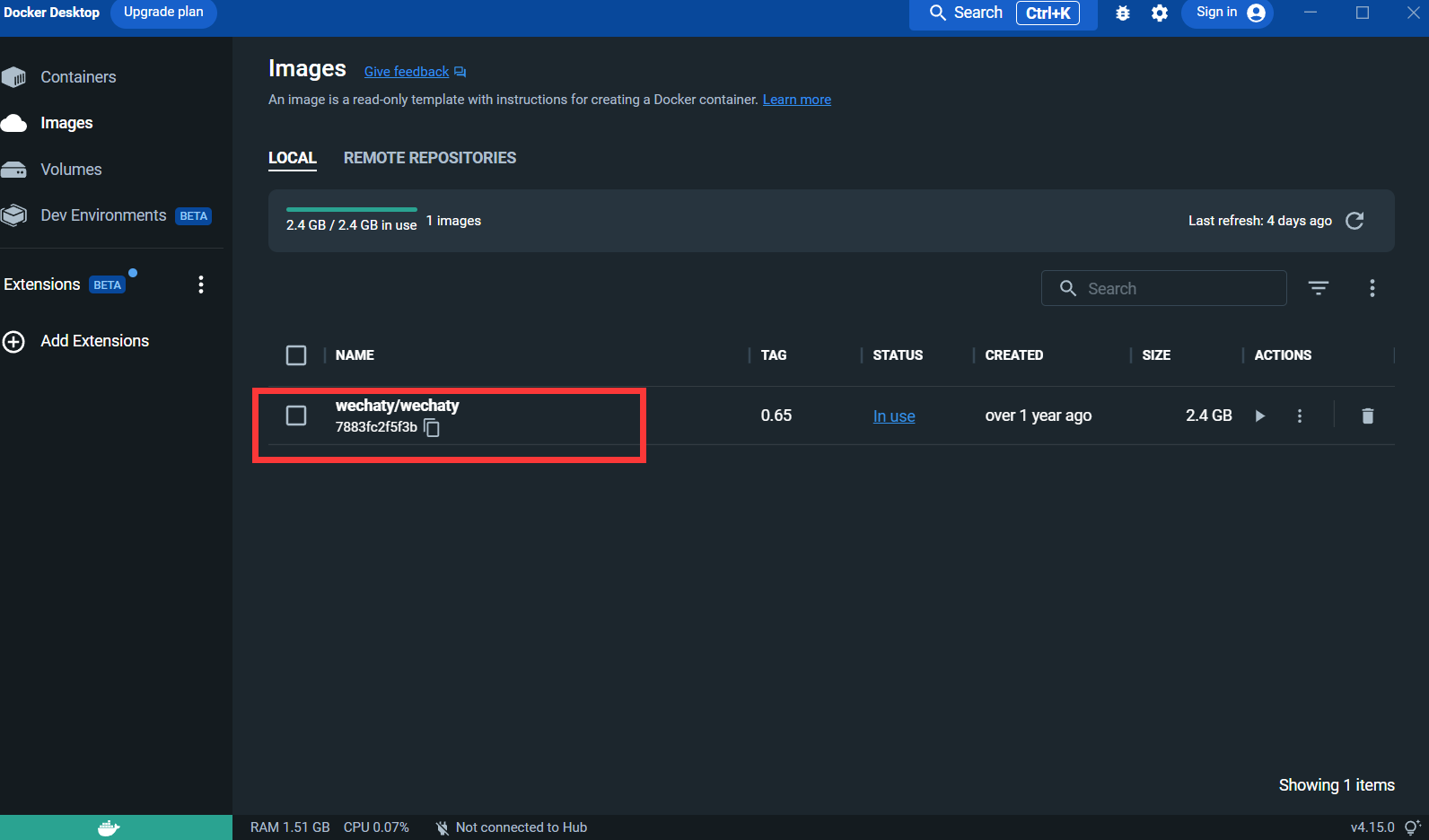
Puppet : If you want to use Wechaty to develop a WeChat robot, you need to use a middleware Puppet to control the operation of WeChat. The official translation of Puppet is puppet. There are currently many kinds of Puppet available. The difference between different versions of Puppet is the different robot functions that can be achieved. For example, if you want your robot to kick users out of a group chat, you need to use Puppet under the Pad protocol.
Apply for connection: http://pad-local.com/#/login
Note : After applying for an account, you will receive a 7-day token.
After applying for the token, execute the following command in the cmd window:
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
Parameter description:
WECHATY_PUPPET_PADLOCAL_TOKEN : Apply for a good token
**WECHATY_TOKEN **: Just write a random string that is guaranteed to be unique
WECHATY_PUPPET_SERVER_PORT : docker server port
wechaty/wechaty:0.65 : version of wechaty image
Note: - "8080:8080"* is the port of your local machine and docker server. Note that the docker server port must be consistent with WECHATY_PUPPET_SERVER_PORT
After running, view the container in the docker desktop panel:
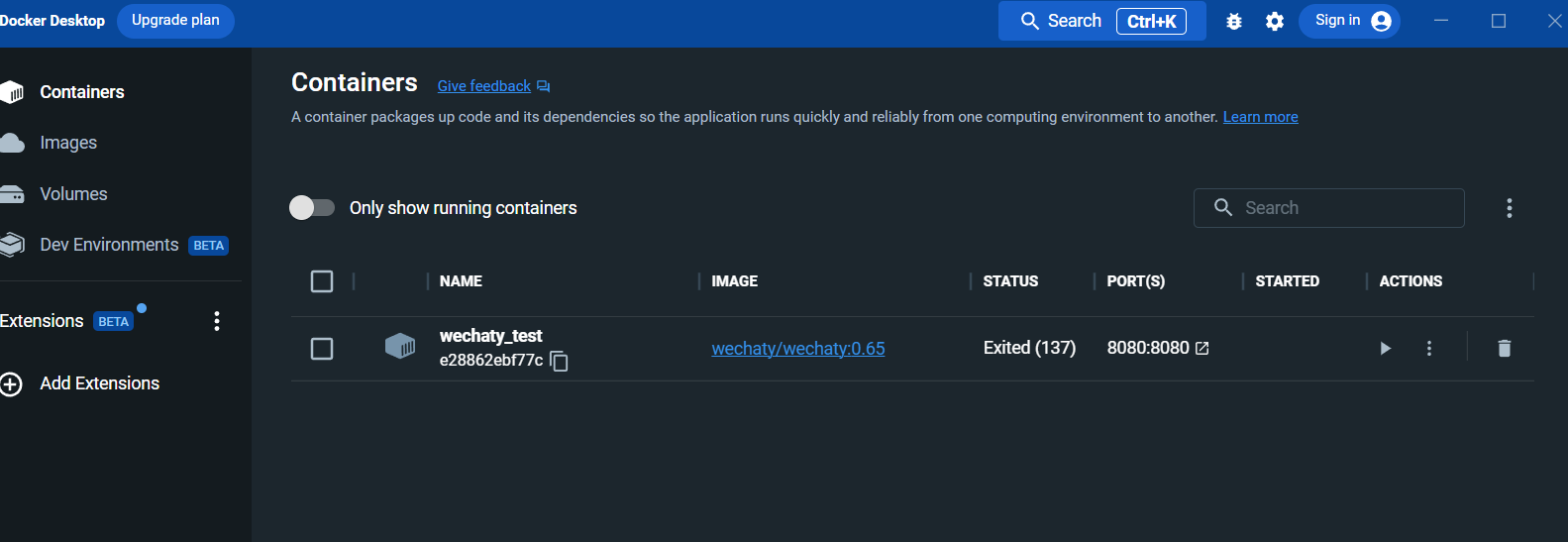
Enter the log interface:
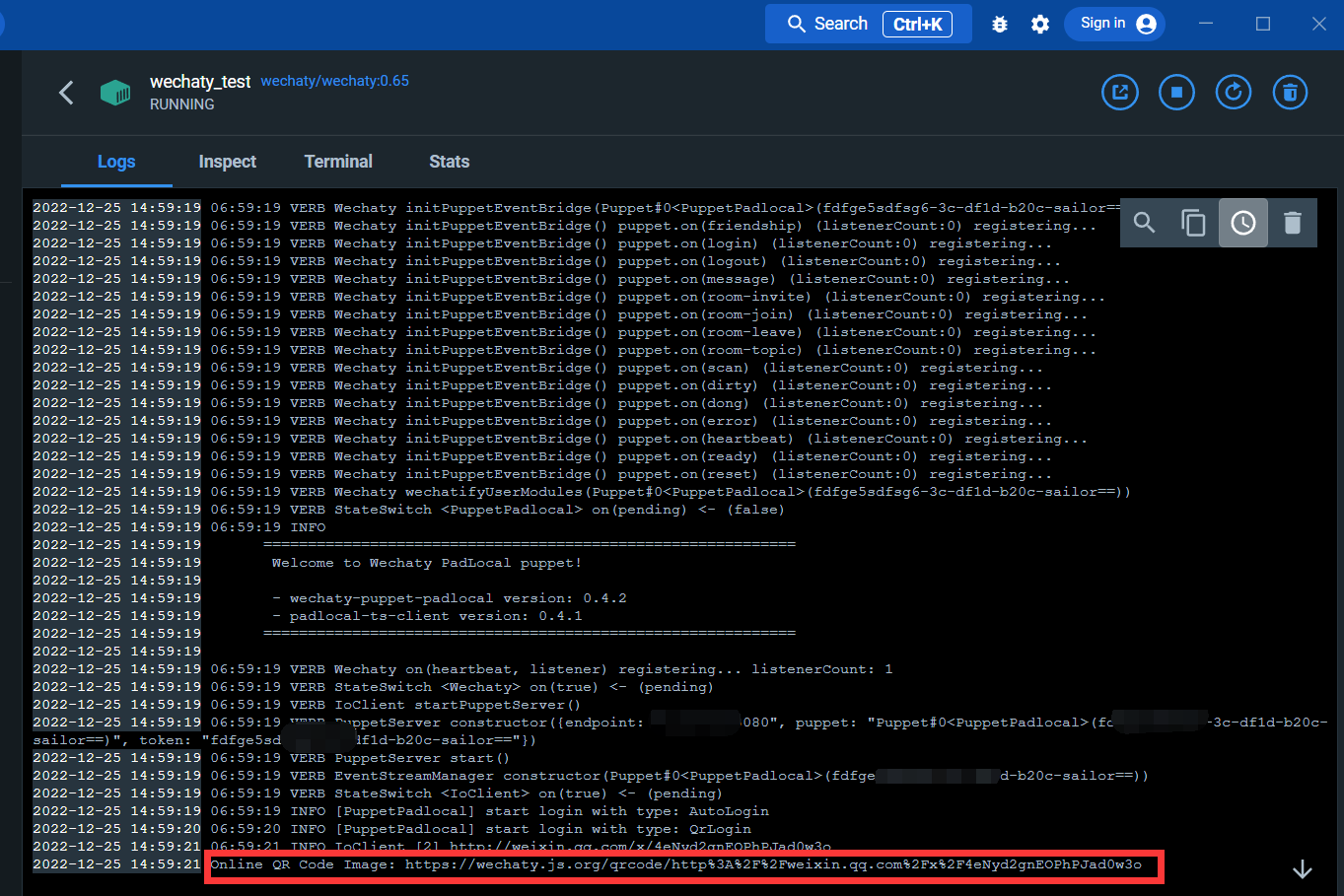
Through the link below, you can scan the QR code to log in to WeChat
After logging in, the docker service is completed.
Install wechaty and openai libraries
Open cmd and execute the following command:
pip install wechaty
pip install openaiLogin to openAI
https://beta.openai.com/
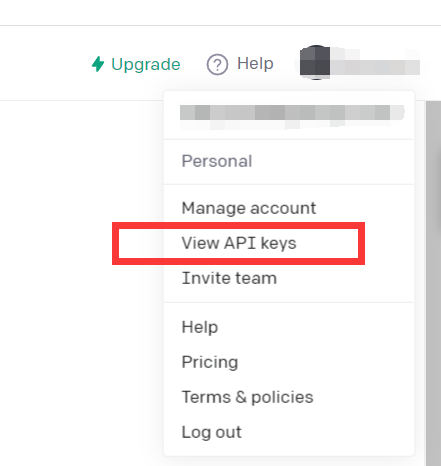
Click View API keys
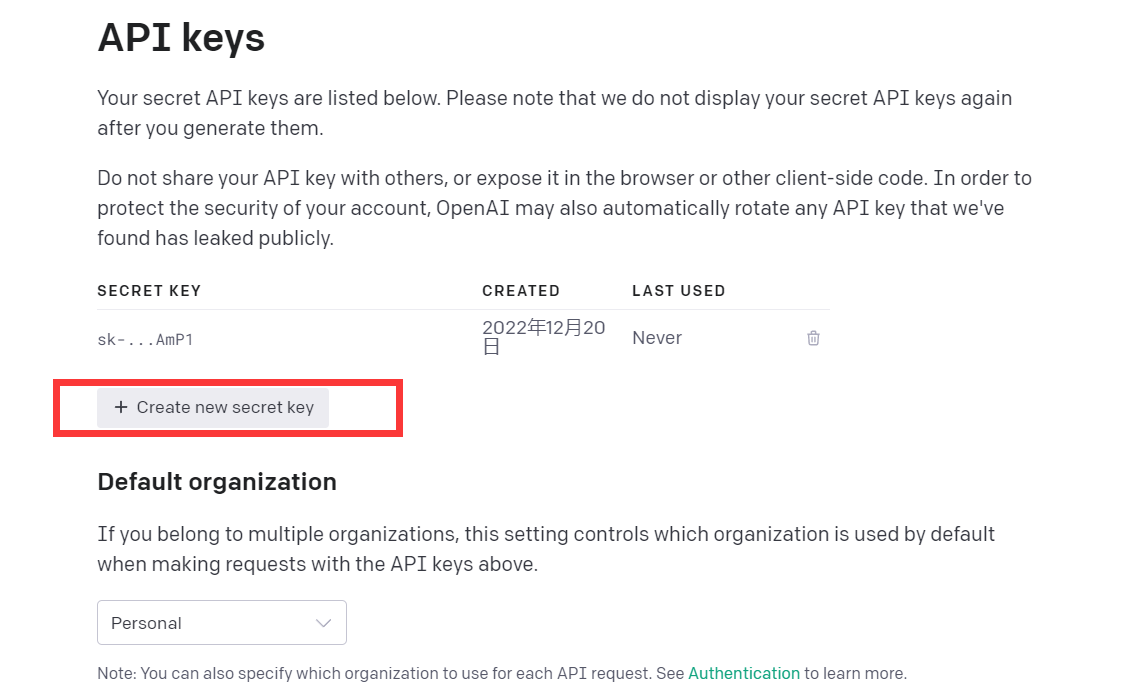
Just get API kyes
At this point, the environment is set up
You can try reading this demo code
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
This code calls the CPT-3 model, which is the same model as chatGPT, and the answer effect is also good.
openAI’s GPT-3 model is introduced as follows:
Our GPT-3 models can understand and generate natural language. We offer four main models with different levels of power suitable for different tasks. Davinci is the most capable model, and Ada is the fastest.
| LATEST MODEL | DESCRIPTION | MAX REQUEST | TRAINING DATA |
|---|---|---|---|
| text-davinci-003 | Most capable GPT-3 model. Can do any task the other models can do, often with higher quality, longer output and better instruction-following. Also supports inserting completions within text. | 4,000 tokens | Up to Jun 2021 |
| text-curie-001 | Very capable, but faster and lower cost than Davinci. | 2,048 tokens | Up to Oct 2019 |
| text-babbage-001 | Capable of straightforward tasks, very fast, and lower cost. | 2,048 tokens | Up to Oct 2019 |
| text-ada-001 | Capable of very simple tasks, usually the fastest model in the GPT-3 series, and lowest cost. | 2,048 tokens | Up to Oct 2019 |
While Davinci is generally the most capable, the other models can perform certain tasks extremely well with significant speed or cost advantages. For example, Curie can perform many of the same tasks as Davinci, but faster and for 1/10th the cost.
We recommend using Davinci while experimenting since it will yield the best results. Once you've got things working, we encourage trying the other models to see if you can get the same results with lower latency. You may also be able to improve the other models' performance by fine-tuning them on a specific task.
In short, the most powerful GPT-3 model. Can do anything other models can do, usually with higher quality, longer output, and better instruction following. Inserting completions into text is also supported.
Although the text-davinci-003 model can be used directly to achieve the single-round dialogue effect of chatGPT; however, in order to better achieve the same multi-round dialogue effect as chatGPT, a dialogue model can be designed.
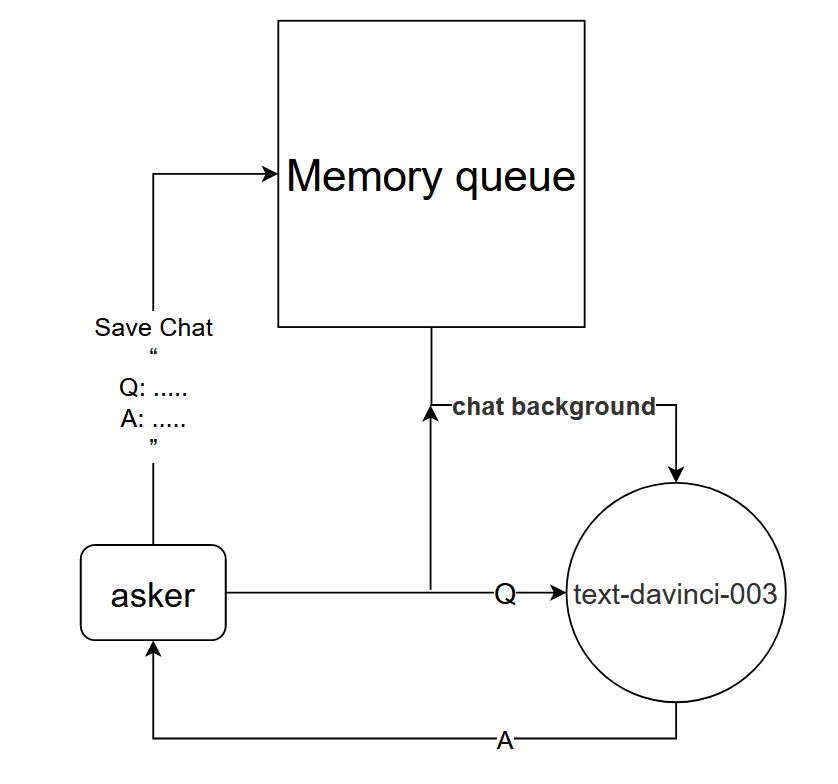
Basic principle: Tell the text-davinci-003 model the context of the current conversation
Implementation method: Design a dialogue memory queue to save the first k rounds of dialogue of the current dialogue, and tell the text-davinci-003 model the content of the first k rounds of dialogue before asking a question, and then obtain the current answer through the text-davinci-003 model content
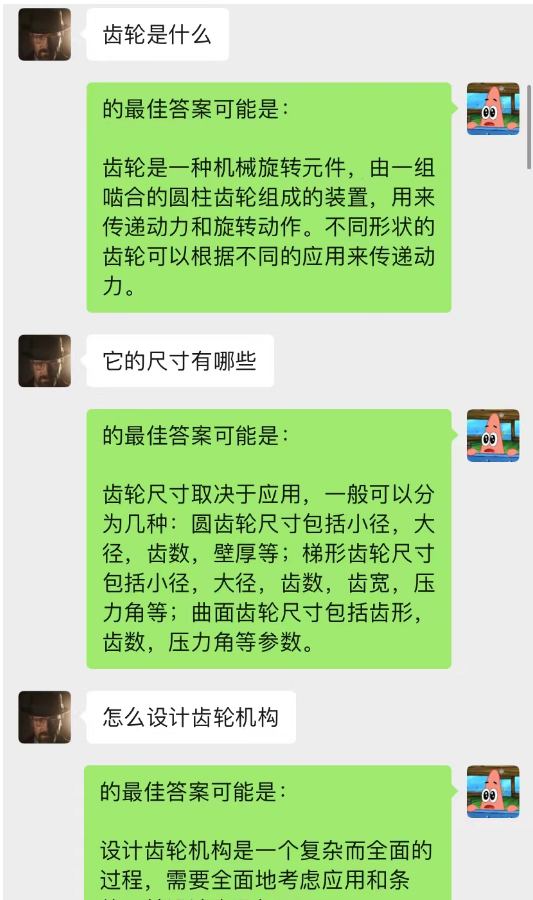
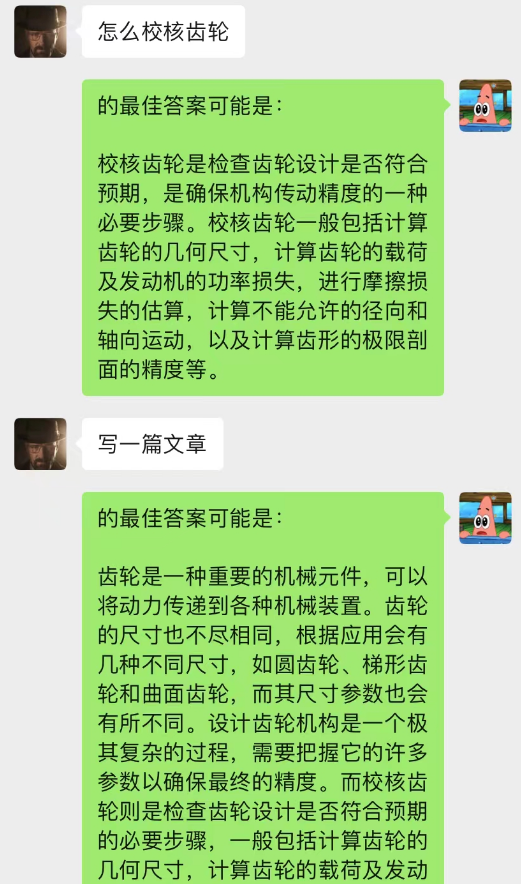
This method works surprisingly well! Give some records of chat
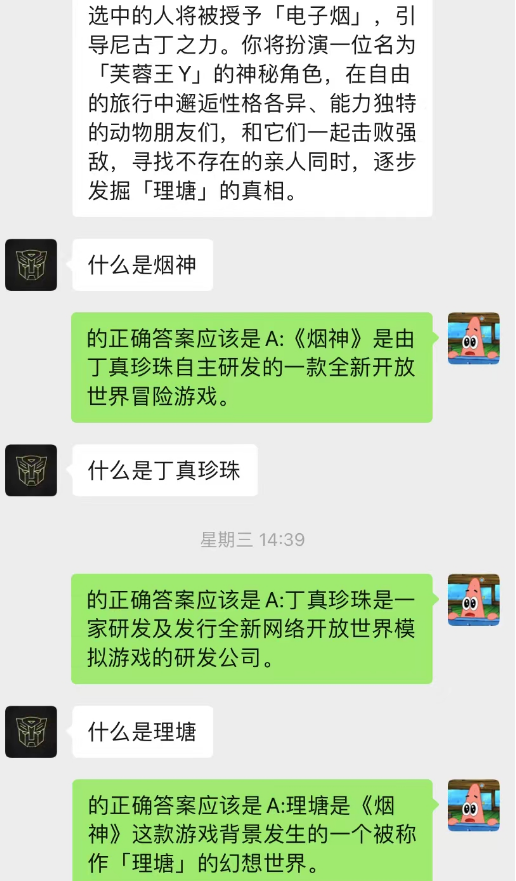
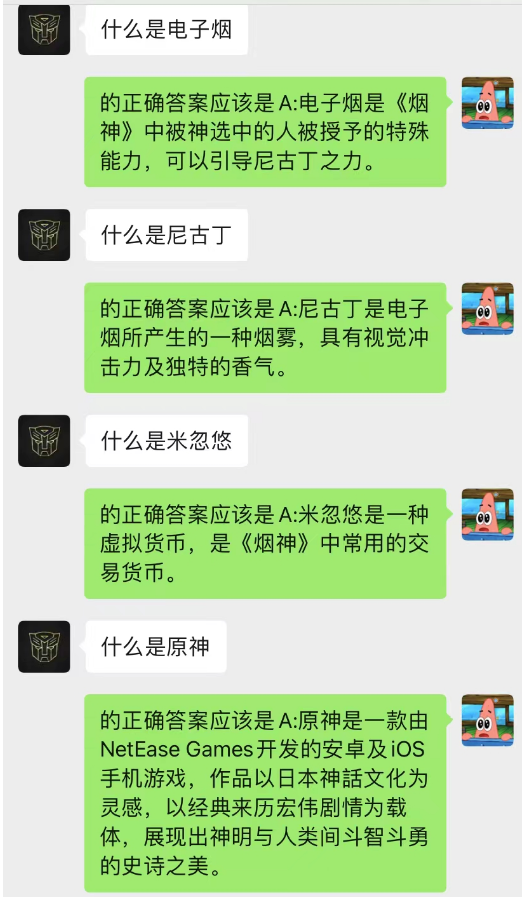
It can be seen that currently chat-background can also be used to allow AI to complete situational learning.
Not only that, you can also achieve the same guided article writing as chatGPT.
This model is a method I am currently conceiving to optimize the chat-backgroud dialogue model. Its basic logic is the same as the N-gram language model, except that N is dynamically changed and Markov properties are added to predict the current dialogue. and the context, so as to judge that the section in the chat-background is the most important, and then use the text-davinci-003 model to give an answer based on the most important memorized conversation content and the current problem (equivalent to letting AI Do it during chat, using previous chat content)
The implementation of this model requires a large amount of data for training, and the code has not yet been completed.
------ Digging : After the code is implemented, update this part of the detailed steps
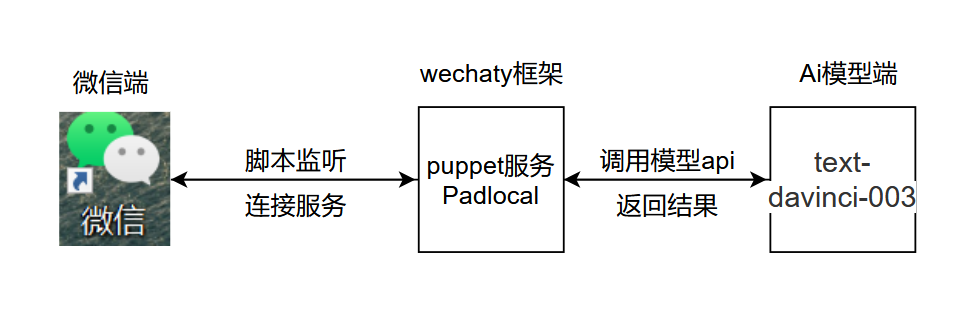
The basic logic of the project is as shown in the figure below:
 .py, add and open chatGPT.py at the location shown, add the secret key and configure environment variables at the location shown
.py, add and open chatGPT.py at the location shown, add the secret key and configure environment variables at the location shown

Code explanation :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
Run successfully
1. Log in in docker, do not use wechaty login in python
2. Set time.sleep() in the code to simulate the speed at which people reply to messages.
3. It is best not to use a large size when testing. It is recommended to create a dedicated small size for AI testing.
The content in this project is only for technical research and science popularization, and does not serve as any conclusive basis. It does not provide any commercial application authorization and is not responsible for any actions.
~~email: [email protected]


