Develop REST API to perform machine translation using Seq2Seq model. The model deployment is done using google could platform.
Project is created with:
The data for this project is available as text file on Data Source, where each line has a sentence in kannada and translation of it in english with space delimiter. We manually verified randomly to ensure that each example made sense.
First we build the encoder decoder model, with attention mechanism using GRU RNN. The training was done using Python script available Here
Build a Flask application which can be access from local machine at the address http://127.0.0.1:5000/predict.
We will use the Script to train the model. After training the model, we will save the model weights in a .pt file and store in google cloud storage. We also build the vocabulary dictionary by indexing each word to a number and pickle them. These pickle files are also stored in storage file. You can access them here Once these files are in place, the deployment can be done following the steps below
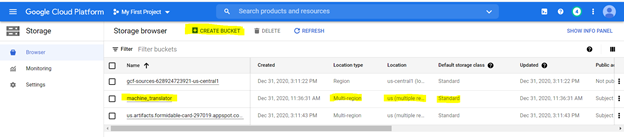
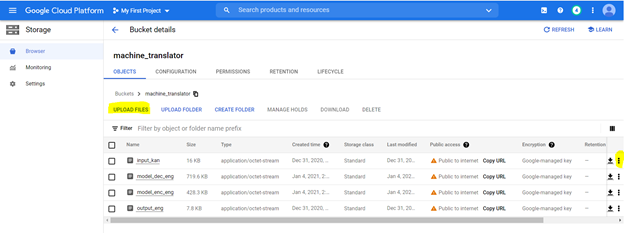
We will upload the files on a storage bucket. To Create a bucket using following options as highlighted with following specifications
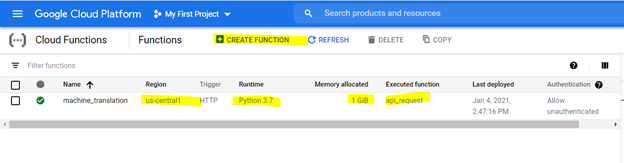
For creating the cloud function, browse for it on the GCP platform and use the options highlighted to below to create a function,
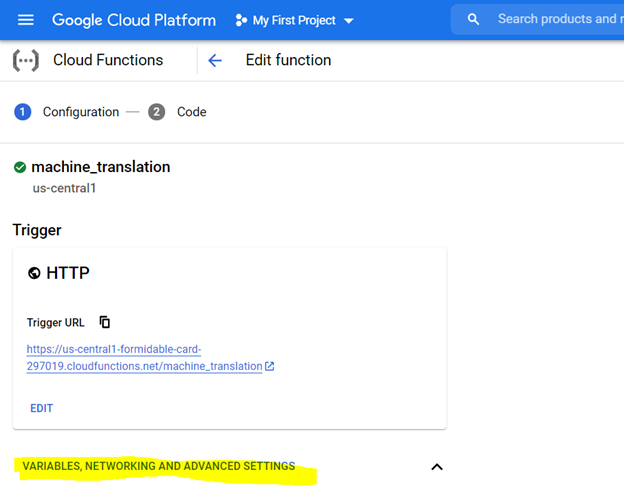
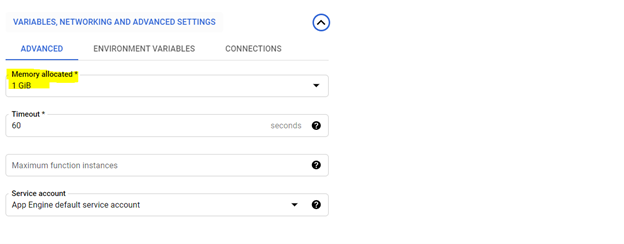
*Allocation of 1 GiB memory is recommended. Once set, click on ‘Next’ and deploy the code on the cloud function console.
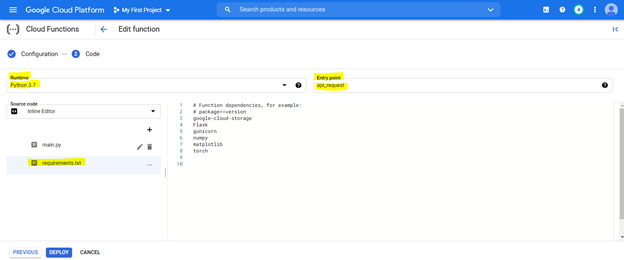
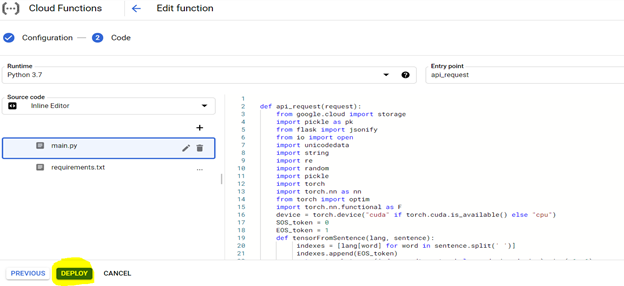
To deploy the code, first configure the console with the below highlighted settings and prepare the environment using the requirements file (this is equivalent to pip install {library}) as described below,

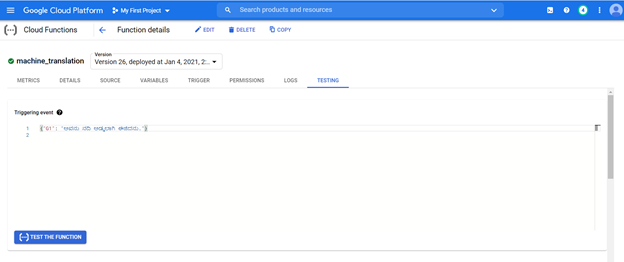

The deployed model can be accessed from the url from any system to translate kannada sentences to english.


