ainovelprompter
1.0.0
AI Novel Prompter can generate writing prompts for novels based on user-specified characteristics.
AI Novel Prompter is a desktop application designed to help writers create consistent and well-structured prompts for AI writing assistants like ChatGPT and Claude. The tool helps manage story elements, character details, and generate properly formatted prompts for continuing your novel.
The Executable is on build/bin Executable
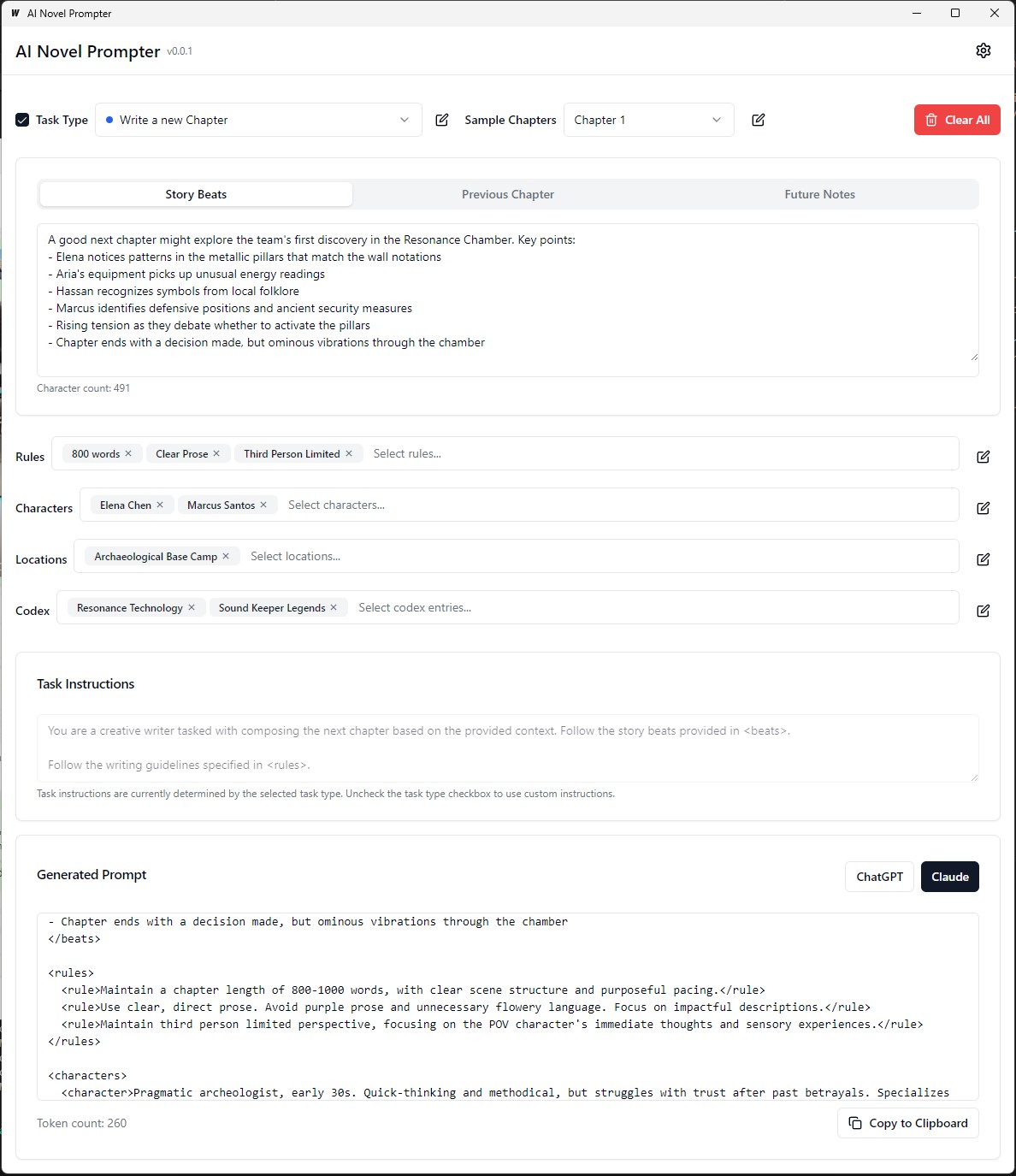
Each category can be edited, saved, and reused across different prompts:
Frontend:
Backend:
.ai-novel-prompter# Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails devTo build a redistributable, production mode package, use wails build.
wails buildThe Executable is on build/bin Executable
Or generate it with:
wails build -nsisThis can be done for Mac as well see the latest part of this guide
The built application will be available in the build directory.
Initial Setup:
Creating a Prompt:
Generating Output:
Before running the application, make sure you have the following installed:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Navigate to the server directory:
cd server
Install the Go dependencies:
go mod download
Update the config.yaml file with your database configuration.
Run the database migrations:
go run cmd/main.go migrate
Start the backend server:
go run cmd/main.go
Navigate to the client directory:
cd ../client
Install the frontend dependencies:
npm install
Start the frontend development server:
npm start
http://localhost:3000 to access the application.git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Update the docker-compose.yml file with your database configuration.
Start the application using Docker Compose:
docker-compose up -d
http://localhost:3000 to access the application.server/config.yaml file.client/src/config.ts file.To build the frontend for production, run the following command in the client directory:
npm run build
The production-ready files will be generated in the client/build directory.
This small guide provides instructions on how to install PostgreSQL on the Windows Subsystem for Linux (WSL), along with steps to manage user permissions and troubleshoot common issues.
Open WSL Terminal: Launch your WSL distribution (Ubuntu recommended).
Update Packages:
sudo apt updateInstall PostgreSQL:
sudo apt install postgresql postgresql-contribCheck Installation:
psql --versionSet PostgreSQL User Password:
sudo passwd postgresCreate Database:
createdb mydbAccess Database:
psql mydbImport Tables from SQL File:
psql -U postgres -q mydb < /path/to/file.sqlList Databases and Tables:
l # List databases
dt # List tables in the current databaseSwitch Database:
c dbnameCreate New User:
CREATE USER your_db_user WITH PASSWORD 'your_db_password';Grant Privileges:
ALTER USER your_db_user CREATEDB;Role Does Not Exist Error: Switch to the 'postgres' user:
sudo -i -u postgres
createdb your_db_namePermission Denied to Create Extension: Login as 'postgres' and execute:
CREATE EXTENSION IF NOT EXISTS pg_trgm;Unknown User Error:
Ensure you are using a recognized system user or correctly refer to a PostgreSQL user within the SQL environment, not via sudo.
To generate custom training data for fine-tuning a language model to emulate the writing style of George MacDonald, the process begins by obtaining the full text of one of his novels, "The Princess and the Goblin," from Project Gutenberg. The text is then broken down into individual story beats or key moments using a prompt that instructs the AI to generate a JSON object for each beat, capturing the author, emotional tone, type of writing, and the actual text excerpt.
Next, GPT-4 is used to rewrite each of these story beats in its own words, generating a parallel set of JSON data with unique identifiers linking each rewritten beat to its original counterpart. To simplify the data and make it more useful for training, the wide variety of emotional tones is mapped to a smaller set of core tones using a Python function. The two JSON files (original and rewritten beats) are then used to generate training prompts, where the model is asked to rephrase the GPT-4 generated text in the style of the original author. Finally, these prompts and their target outputs are formatted into JSONL and JSON files, ready to be used for fine-tuning the language model to capture MacDonald's distinctive writing style.
In the previous example, the process of generating paraphrased text using a language model involved some manual tasks. The user had to manually provide the input text, run the script, and then review the generated output to ensure its quality. If the output did not meet the desired criteria, the user would need to manually retry the generation process with different parameters or make adjustments to the input text.
However, with the updated version of the process_text_file function, the entire process has been fully automated. The function takes care of reading the input text file, splitting it into paragraphs, and automatically sending each paragraph to the language model for paraphrasing. It incorporates various checks and retry mechanisms to handle cases where the generated output does not meet the specified criteria, such as containing unwanted phrases, being too short or too long, or consisting of multiple paragraphs.
The automation process includes several key features:
Resuming from the last processed paragraph: If the script is interrupted or needs to be run multiple times, it automatically checks the output file and resumes processing from the last successfully paraphrased paragraph. This ensures that progress is not lost and the script can pick up where it left off.
Retry mechanism with random seed and temperature: If a generated paraphrase fails to meet the specified criteria, the script automatically retries the generation process up to a specified number of times. With each retry, it randomly changes the seed and temperature values to introduce variation in the generated responses, increasing the chances of obtaining a satisfactory output.
Progress saving: The script saves the progress to the output file every specified number of paragraphs (e.g., every 500 paragraphs). This safeguards against data loss in case of any interruptions or errors during the processing of a large text file.
Detailed logging and summary: The script provides detailed logging information, including the input paragraph, generated output, retry attempts, and reasons for failure. It also generates a summary at the end, displaying the total number of paragraphs, successfully paraphrased paragraphs, skipped paragraphs, and the total number of retries.
To generate ORPO custom training data for fine-tuning a language model to emulate the writing style of George MacDonald.
The input data should be in JSONL format, with each line containing a JSON object that includes the prompt and chosen response. (From the previous fine tuning) To use the script, you need to set up the OpenAI client with your API key and specify the input and output file paths. Running the script will process the JSONL file and generate a CSV file with columns for the prompt, chosen response, and a generated rejected response. The script saves progress every 100 lines and can resume from where it left off if interrupted. Upon completion, it provides a summary of the total lines processed, written lines, skipped lines, and retry details.
Dataset Quality Matters: 95% of outcomes depend on dataset quality. A clean dataset is essential since even a little bad data can hurt the model.
Manual Data Review: Cleaning and evaluating the dataset can greatly improve the model. This is a time-consuming but necessary step because no amount of parameter adjusting can fix a defective dataset.
Training parameters should not improve but prevent model degradation. In robust datasets, the goal should be to avoid negative repercussions while directing the model. There is no optimal learning rate.
Model Scale and Hardware Limitations: Larger models (33b parameters) may enable better fine-tuning but require at least 48GB VRAM, making them impractical for majority of home setups.
Gradient Accumulation and Batch Size: Gradient accumulation helps reduce overfitting by enhancing generalisation across different datasets, but it may lower quality after a few batches.
The size of the dataset is more important for fine-tuning a base model than a well-tuned model. Overloading a well-tuned model with excessive data might degrade its previous fine-tuning.
An ideal learning rate schedule starts with a warmup phase, holds steady for an epoch, and then gradually decreases using a cosine schedule.
Model Rank and Generalisation: The amount of trainable parameters affects the model's detail and generalisation. Lower-rank models generalise better but lose detail.
LoRA's Applicability: Parameter-Efficient Fine-Tuning (PEFT) is applicable to large language models (LLMs) and systems like Stable Diffusion (SD), demonstrating its versatility.
The Unsloth community has helped resolve several issues with finetuning Llama3. Here are some key points to keep in mind:
Double BOS tokens: Double BOS tokens during finetuning can break things. Unsloth automatically fixes this issue.
GGUF conversion: GGUF conversion is broken. Be careful of double BOS and use CPU instead of GPU for conversion. Unsloth has built-in automatic GGUF conversions.
Buggy base weights: Some of Llama 3's base (not instruct) weights are "buggy" (untrained): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|>. This can cause NaNs and buggy results. Unsloth automatically fixes this.
System prompt: According to the Unsloth community, adding a system prompt makes finetuning of the Instruct version (and possibly the base version) much better.
Quantization issues: Quantization issues are common. See this comparison which shows that you can get good performance with Llama3, but using the wrong quantization can hurt performance. For finetuning, use bitsandbytes nf4 to boost accuracy. For GGUF, use the I versions as much as possible.
Long context models: Long context models are poorly trained. They simply extend the RoPE theta, sometimes without any training, and then train on a weird concatenated dataset to make it a long dataset. This approach does not work well. A smooth, continuous long context scaling would have been much better if scaling from 8K to 1M context length.
To resolve some of these issues, use Unsloth for finetuning Llama3.
When fine-tuning a language model for paraphrasing in an author's style, it's important to evaluate the quality and effectiveness of the generated paraphrases.
The following evaluation metrics can be used to assess the model's performance:
BLEU (Bilingual Evaluation Understudy):
sacrebleu library in Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])ROUGE (Recall-Oriented Understudy for Gisting Evaluation):
rouge library in Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Perplexity:
perplexity = model.perplexity(generated_paraphrases)Stylometric Measures:
stylometry library in Python.from stylometry import extract_features; features = extract_features(generated_paraphrases)To integrate these evaluation metrics into your Axolotl pipeline, follow these steps:
Prepare your training data by creating a dataset of paragraphs from the target author's works and splitting it into training and validation sets.
Fine-tune your language model using the training set, following the approach discussed earlier.
Generate paraphrases for the paragraphs in the validation set using the fine-tuned model.
Implement the evaluation metrics using the respective libraries (sacrebleu, rouge, stylometry) and calculate the scores for each generated paraphrase.
Perform human evaluation by collecting ratings and feedback from human evaluators.
Analyze the evaluation results to assess the quality and style of the generated paraphrases and make informed decisions to improve your fine-tuning process.
Here's an example of how you can integrate these metrics into your pipeline:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model(training_data)
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases(fine_tuned_model, validation_data)
# Calculate evaluation metrics
bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])
rouge = Rouge()
rouge_scores = rouge.get_scores(generated_paraphrases, original_paragraphs)
perplexity = fine_tuned_model.perplexity(generated_paraphrases)
stylometric_features = extract_features(generated_paraphrases)
# Perform human evaluation
human_scores = collect_human_evaluations(generated_paraphrases)
# Analyze and interpret the results
analyze_results(bleu_score, rouge_scores, perplexity, stylometric_features, human_scores)Remember to install the necessary libraries (sacrebleu, rouge, stylometry) and adapt the code to fit your implementation in Axolotl or similar.
In this experiment, I explored the capabilities and differences between various AI models in generating a 1500-word text based on a detailed prompt. I tested models from https://chat.lmsys.org/, ChatGPT4, Claude 3 Opus, and some local models in LM Studio. Each model generated the text three times to observe variability in their outputs. I also created a separate prompt for evaluating the writing of the first iteration from each model and asked ChatGPT 4 and Claude Opus 3 to provide feedback.
Through this process, I observed that some models exhibit higher variability between executions, while others tend to use similar wording. There were also significant differences in the number of words generated and the amount of dialogue, descriptions, and paragraphs produced by each model. The evaluation feedback revealed that ChatGPT suggests a more "refined" prose, while Claude recommends less purple prose. Based on these findings, I compiled a list of takeaways to incorporate into the next prompt, focusing on precision, varied sentence structures, strong verbs, unique twists on fantasy motifs, consistent tone, distinct narrator voice, and engaging pacing. Another technique to consider is asking for feedback and then rewriting the text based on that feedback.
I'm open to collaborating with others to further fine-tune prompts for each model and explore their capabilities in creative writing tasks.
Models have inherent formatting biases. Some models prefer hyphens for lists, others asterisks. When using these models, it's helpful to mirror their preferences for consistent outputs.
Formatting Tendencies:
Llama 3 prefers lists with bolded headings and asterisks.
Example: Bolded Title Case Heading
List items with asterisks after two newlines
List items separated by one newline
Next List
More list items
Etc...
Few-shot Examples:
System Prompt Adherence:
Context Window:
Censorship:
Intelligence:
Consistency:
Lists and Formatting:
Chat Settings:
Pipeline Settings:
Llama 3 is flexible and intelligent but has context and quoting limitations. Adjust prompting methods accordingly.
All comments are welcome. Open an issue or send a pull request if you find any bugs or have recommendations for improvement.
This project is licensed under: Attribution-NonCommercial-NoDerivatives (BY-NC-ND) license See: https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en


