Componente de registro distribuido Plumelog v3.5.3
3.5.3
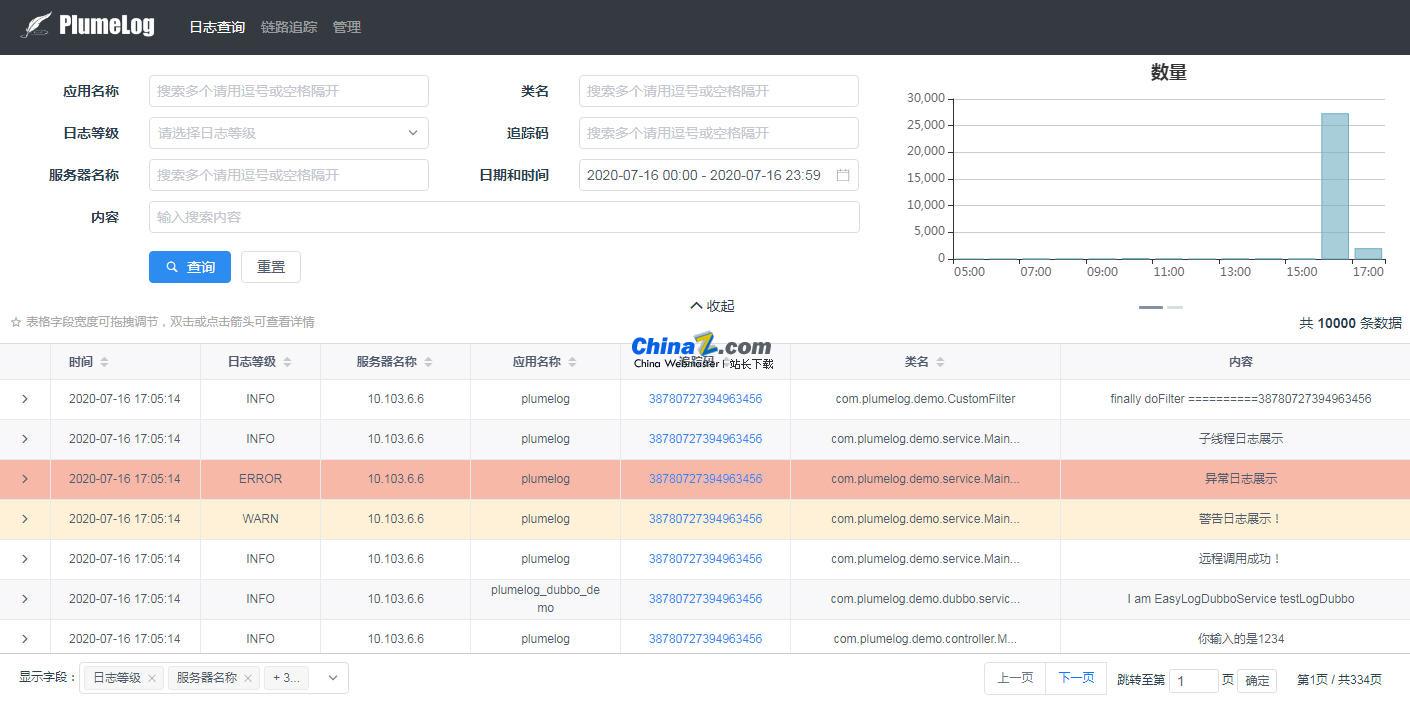
Plumelog es un componente de registro distribuido de Java simple y fácil de usar. Admite decenas de miles de millones de niveles, desde la recopilación de registros hasta la consulta, es conveniente y rápido sin tener que leer registros en archivos. Admite consultar los registros de una cadena de llamadas, admite el seguimiento de enlaces y verifica el consumo de tiempo de la cadena de llamadas. También puede consultar registros relacionados en un sistema distribuido, puede ayudar a localizar problemas rápidamente, es simple y fácil de usar, no tiene intrusión de código y tiene una interfaz de consulta amigable, eficiente y conveniente siempre que esté utilizando Java. sistema, no necesita realizar ninguna modificación en el proyecto, simplemente acceda a él y úselo directamente. Los registros no se guardarán en el disco local y no hay necesidad de preocuparse por la ocupación del registro. server. Si crees que el proyecto es útil, dale una estrella. Tu estrella es la fuerza impulsora para que avancemos.
Introducción a la función Plumelog
1. Un sistema de registro distribuido no invasivo que recopila registros basados en log4j, log4j2 y logback, y establece la ID del enlace para facilitar la consulta de registros relacionados.
2. Basado en elasticsearch como motor de consultas.
3. Alto rendimiento y alta eficiencia de consultas
4. Todo el proceso no ocupa el espacio en el disco local de la aplicación y no requiere mantenimiento, es transparente para el proyecto y no afecta el funcionamiento del proyecto en sí.
5. No es necesario modificar proyectos antiguos, introducirlos y usarlos directamente, admitir duadfdso y springcloud
Arquitectura Plumelog
plumelog-core: el componente principal incluye el extremo de recopilación de registros, que es responsable de recopilar registros y enviarlos a kafka, redis y otras colas.
plumelog-server: Responsable de escribir registros de forma asincrónica en la cola para elasticsearch
plumelog-ui: pantalla frontal, interfaz de consulta de registros
plumelog-demo: caso de uso basado en springboot
Cómo utilizar Plumelog
Compílelo e instálelo usted mismo de la siguiente manera
Requisito previo: usted mismo puede instalar kafka o redis y elasticsearch (6.8 o superior) y se ha realizado la compatibilidad. En teoría, no es necesario considerar ES.
Embalar
maven implementar -DskipTests carga el paquete en su propio servidor privado
Cambie la dirección del servidor privado a plumelog/pom.xml
UTF-8
http://172.16.249.94:4000
Registro de actualización de Plumelog
v3.5
Se agregó el modo de inicio lite. En este momento, no es necesario configurar redis y es. En el modo lite, no se pueden usar campos extendidos, estadísticas de error ni alarmas de error.
Se ha agregado el módulo plumelog-lite. Existe como un paquete dependiente de plumelog. Se puede hacer referencia a él directamente y usarlo sin implementación.
Agregue una consola de registro para ver la salida en tiempo real. Es un artefacto durante la implementación y las pruebas. Abrir la consola afectará el rendimiento, así que preste atención al momento de uso.
Se corrigió un error en el seguimiento de enlaces donde es posible que no se muestre la capa más externa.
Se agregó detección automática de ES, no se requiere configuración
Aumente la configuración automática del número máximo de fragmentos ES, no es necesario configurarlo manualmente
Optimicé la interfaz, optimicé el botón de guardar fuera de los límites de la interfaz de alarma para mostrar la mitad del error
Optimice la configuración en modo redis. Si todas las aplicaciones usan solo un redis de cola, no es necesario configurar el redis de cola. El redis de cola se habilitará automáticamente como redis de administración.
Corregir errores conocidos y otras optimizaciones.
Los usuarios antiguos pueden reemplazar directamente plumelog-server-3.5.jar al actualizar y reiniciar.
modo lite, necesita actualizar el cliente a 3.5
Springboot-admin integrado facilita la administración de proyectos springboot. Puede usar springbootadmin para ajustar dinámicamente el nivel de salida del registro.