Lee esto en ingles
GLM-4-Voice es un modelo de voz de un extremo a otro lanzado por Zhipu AI. GLM-4-Voice puede comprender y generar directamente voces en chino e inglés, realizar conversaciones de voz en tiempo real y cambiar la emoción, la entonación, la velocidad, el dialecto y otros atributos de la voz según las instrucciones del usuario.

GLM-4-Voice consta de tres partes:
GLM-4-Voice-Tokenizer: al agregar Vector Quantization a la parte del codificador de Whisper y el entrenamiento supervisado en datos ASR, la entrada de voz continua se convierte en tokens discretos. En promedio, el audio sólo necesita estar representado por 12,5 tokens discretos por segundo.
GLM-4-Voice-Decoder: un decodificador de voz que admite el razonamiento de transmisión y está capacitado en función de la estructura del modelo Flow Matching de CosyVoice para convertir tokens de voz discretos en salida de voz continua. Se necesitan al menos 10 tokens de voz para comenzar a generar, lo que reduce el retraso en la conversación de un extremo a otro.
GLM-4-Voice-9B: Basado en GLM-4-9B, se realiza un entrenamiento previo y alineación de modalidades de voz para comprender y generar tokens de voz discretizados.
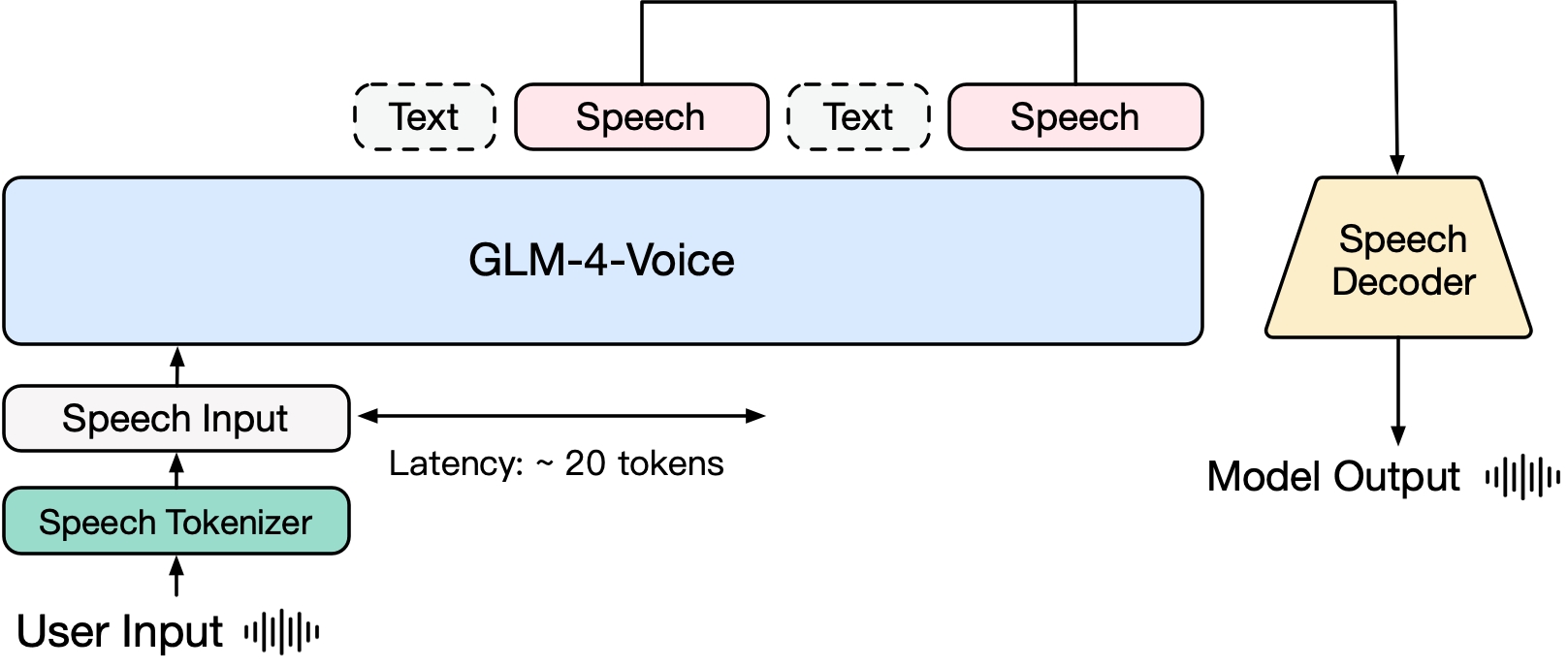
En términos de entrenamiento previo, para superar las dos dificultades del coeficiente intelectual del modelo y la expresividad sintética en el modo de habla, desacoplamos la tarea Speech2Speech en "hacer una respuesta de texto basada en el audio del usuario" y "sintetizar un discurso basado en la respuesta de texto y el discurso del usuario "Dos tareas y dos objetivos de preentrenamiento están diseñados para sintetizar datos entrelazados de voz y texto basados en datos de preentrenamiento de texto y datos de audio no supervisados para adaptarse a estas dos formas de tareas. Basado en el modelo base de GLM-4-9B, GLM-4-Voice-9B ha sido previamente entrenado con millones de horas de audio y cientos de miles de millones de tokens de datos entrelazados de audio y texto, y tiene una sólida comprensión y modelado de audio. . capacidad.
En términos de alineación, para admitir diálogos de voz de alta calidad, diseñamos una arquitectura de pensamiento de transmisión: según la voz del usuario, GLM-4-Voice puede generar contenido alternativamente en dos modos: texto y voz en formato de transmisión. El modo de voz está representado por El texto se utiliza como referencia para garantizar la alta calidad del contenido de la respuesta y los cambios de voz correspondientes se realizan de acuerdo con los requisitos del comando de voz del usuario. Aún tiene la capacidad de modelar de un extremo a otro mientras se conserva. el coeficiente intelectual del modelo de lenguaje en la mayor medida y, al mismo tiempo, tiene baja latencia. Solo necesita generar un mínimo de 20 tokens para sintetizar el habla.
Más adelante se publicará un informe técnico más detallado.
| Modelo | Tipo | Descargar |
|---|---|---|
| GLM-4-Tokenizador de voz | Tokenizador de voz | ¿Abrazo cara? |
| GLM-4-Voz-9B | Modelo de chat | ¿Abrazo cara? |
| GLM-4-Decodificador de voz | Decodificador de voz | ¿Abrazo cara? |
Proporcionamos una demostración web que se puede iniciar directamente. Los usuarios pueden ingresar voz o texto, y el modelo dará respuestas tanto de voz como de texto.

Primero descarga el repositorio
git clone --recurse-submodules https://github.com/THUDM/GLM-4-Voicecd GLM-4-Voice
Luego instale las dependencias. También puede utilizar la imagen zhipuai/glm-4-voice:0.1 que le proporcionamos para omitir este paso.
instalación de pip -r requisitos.txt
Dado que el modelo Decoder no admite la inicialización a través de transformers , el punto de control debe descargarse por separado.
# Descarga del modelo git, asegúrese de haber instalado git-lfsgit lfs install clon de git https://huggingface.co/THUDM/glm-4-voice-decoder
Iniciar servicio de modelo
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype bfloat16 --device cuda:0
Si necesita arrancar con precisión Int4, ejecute
python model_server.py --host localhost --model-path THUDM/glm-4-voice-9b --port 10000 --dtype int4 --device cuda:0
Este comando descargará automáticamente glm-4-voice-9b . Si las condiciones de la red no son buenas, también puede descargar y especificar manualmente la ruta local a través de --model-path .
Iniciar servicio web
python web_demo.py --tokenizer-path THUDM/glm-4-voice-tokenizer --model-path THUDM/glm-4-voice-9b --flow-path ./glm-4-voice-decoder
Puede acceder a la demostración web en http://127.0.0.1:8888.
Este comando descarga automáticamente glm-4-voice-tokenizer y glm-4-voice-9b . Tenga en cuenta que glm-4-voice-decoder debe descargarse manualmente.
Si las condiciones de la red no son buenas, puede descargar manualmente estos tres modelos y luego especificar la ruta local a través de --tokenizer-path , --flow-path y --model-path .
La reproducción de audio en streaming de Gradio es inestable. La calidad del audio será mayor cuando se haga clic en el cuadro de diálogo una vez completada la generación.
Proporcionamos algunos ejemplos de conversación de GLM-4-Voice, incluido el control de emociones, el cambio de la velocidad del habla, la generación de dialectos, etc.
Guíame a relajarme con una voz suave.
Comentario de partidos de fútbol con voz emocionada.
Cuenta una historia de fantasmas con voz quejumbrosa
Presente lo frío que es el invierno en el dialecto del noreste
Diga "Coma uvas sin escupir la piel" en dialecto de Chongqing
Decir un trabalenguas en dialecto de Beijing
habla mas rapido
más rápido
Parte del código de este proyecto proviene de:
Voz acogedora
transformadores
GLM-4
El uso de pesas modelo GLM-4 debe seguir el protocolo del modelo.
El código de este repositorio de código abierto sigue el protocolo Apache 2.0.