Documento: Sobre la generalización de tiro cero de los modelos de visión y lenguaje en el momento de la prueba: ¿realmente necesitamos un aprendizaje rápido? .
Autores: Maxime Zanella, Ismail Ben Ayed.
Este es el repositorio oficial de GitHub de nuestro artículo aceptado en CVPR '24. Este trabajo presenta el método MeanShift Test-time Augmentation (MTA), que aprovecha los modelos Vision-Language sin la necesidad de un aprendizaje rápido. Nuestro método aumenta aleatoriamente una sola imagen en N vistas aumentadas, luego alterna entre dos pasos clave (consulte mta.py y Detalles en la sección de código):
Este paso implica calcular una puntuación para cada vista aumentada para evaluar su relevancia y calidad (puntuación interna).
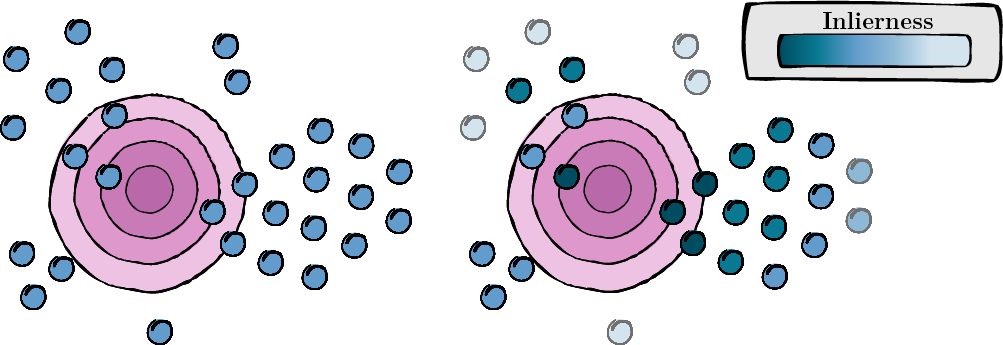
Figura 1: Cálculo de puntuación para cada vista aumentada.
Con base en las puntuaciones calculadas en el paso anterior, buscamos la moda de los puntos de datos (MeanShift).
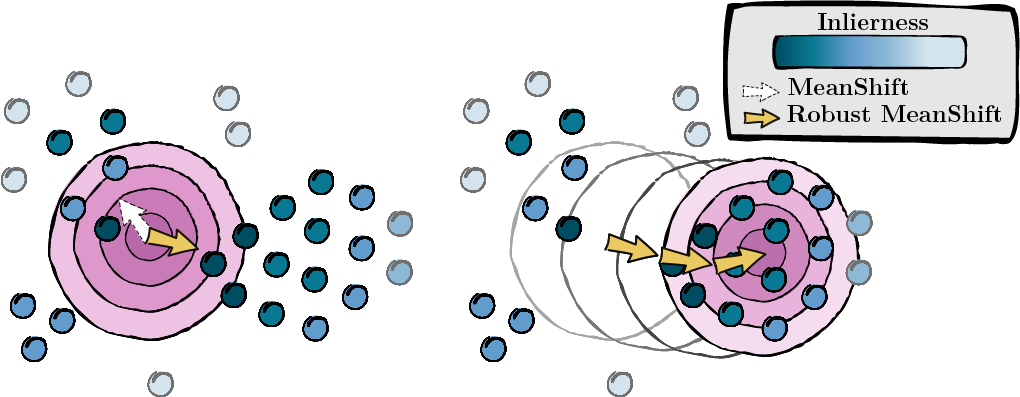
Figura 2: Búsqueda de la moda, ponderada por puntuaciones de inlierness.
Seguimos la instalación y el preprocesamiento de TPT. Esto garantiza que su conjunto de datos tenga el formato adecuado. Puedes encontrar su repositorio aquí. Si es más conveniente, puede cambiar los nombres de las carpetas de cada conjunto de datos en el diccionario ID_to_DIRNAME en data/datautils.py (línea 20).
Ejecute MTA en el conjunto de datos de ImageNet con una semilla aleatoria de 1 y el mensaje 'una foto de a' ingresando el siguiente comando:
python main.py --data /path/to/your/data --mta --testsets I --seed 1O los 15 conjuntos de datos a la vez:
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1Más información sobre el procedimiento en mta.py.
gaussian_kernelsolve_mtay ) de manera uniforme.Si encuentra útil este proyecto, cítelo de la siguiente manera:
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}Expresamos nuestro agradecimiento a los autores del TPT por su contribución de código abierto. Puedes encontrar su repositorio aquí.


