la interfaz web ChatTTS
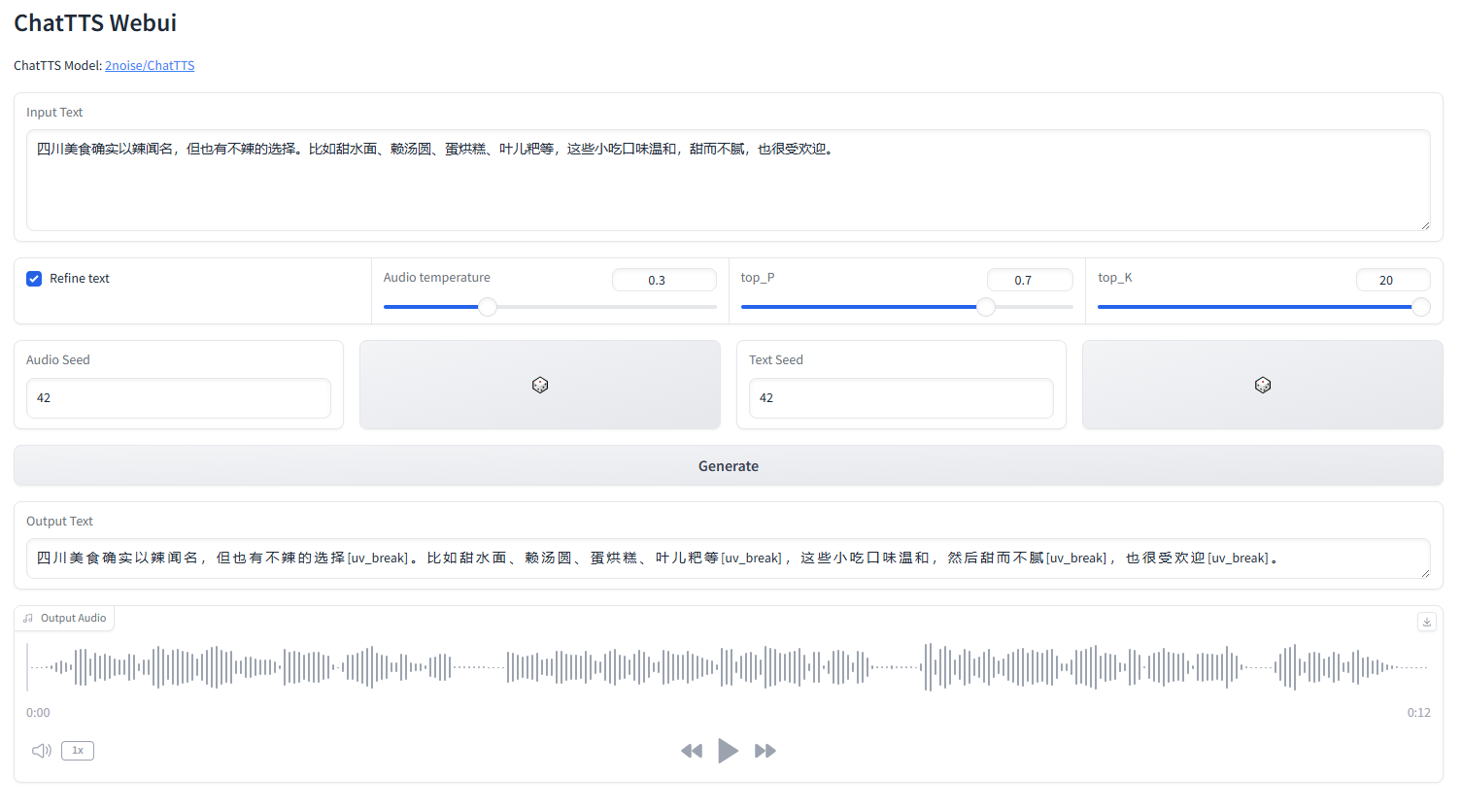
iniciar webui.py
python webui.py
python webui.py --server_port=8080conda create -n chattts python=3.9
conda activate chattts
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install omegaconf vocos transformers vector-quantize-pytorchinglés |中文简体
ChatTTS es un modelo de texto a voz diseñado específicamente para escenarios de diálogo como el asistente LLM. Admite los idiomas inglés y chino. Nuestro modelo está capacitado con más de 100.000 horas compuestas de chino e inglés. La versión de código abierto de HuggingFace es un modelo previamente entrenado de 40.000 horas sin SFT.
Para consultas formales sobre el modelo y la hoja de ruta, contáctenos en [email protected]. Puede unirse a nuestro grupo QQ: 808364215 para debatir. Siempre es bienvenido agregar problemas de github.
Para obtener una descripción detallada del modelo, puede consultar el vídeo en Bilibili.
Este repositorio es sólo para fines académicos. Está destinado a uso educativo y de investigación, y no debe utilizarse con fines comerciales o legales. Los autores no garantizan la exactitud, integridad o confiabilidad de la información. La información y los datos utilizados en este repositorio son únicamente para fines académicos y de investigación. Los datos se obtienen de fuentes disponibles públicamente y los autores no reclaman ninguna propiedad ni derechos de autor sobre los datos.
ChatTTS es un potente sistema de conversión de texto a voz. Sin embargo, es muy importante utilizar esta tecnología de forma responsable y ética. Para limitar el uso de ChatTTS, agregamos una pequeña cantidad de ruido de alta frecuencia durante el entrenamiento del modelo de 40,000 horas y comprimimos la calidad del audio tanto como sea posible usando el formato MP3, para evitar que actores malintencionados lo utilicen potencialmente con fines delictivos. propósitos. Al mismo tiempo, hemos entrenado internamente un modelo de detección y planeamos abrirlo en el futuro.
import ChatTTS
from IPython . display import Audio
chat = ChatTTS . Chat ()
chat . load_models ()
texts = [ "<PUT YOUR TEXT HERE>" ,]
wavs = chat . infer ( texts , use_decoder = True )
Audio ( wavs [ 0 ], rate = 24_000 , autoplay = True ) ###################################
# Sample a speaker from Gaussian.
import torch
std , mean = torch . load ( 'ChatTTS/asset/spk_stat.pt' ). chunk ( 2 )
rand_spk = torch . randn ( 768 ) * std + mean
params_infer_code = {
'spk_emb' : rand_spk , # add sampled speaker
'temperature' : .3 , # using custom temperature
'top_P' : 0.7 , # top P decode
'top_K' : 20 , # top K decode
}
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_6]'
}
wav = chat . infer ( "<PUT YOUR TEXT HERE>" , params_refine_text = params_refine_text , params_infer_code = params_infer_code )
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wav = chat . infer ( text , skip_refine_text = True , params_infer_code = params_infer_code ) inputs_en = """
chat T T S is a text to speech model designed for dialogue applications.
[uv_break]it supports mixed language input [uv_break]and offers multi speaker
capabilities with precise control over prosodic elements [laugh]like like
[uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation.
[uv_break]it delivers natural and expressive speech,[uv_break]so please
[uv_break] use the project responsibly at your own risk.[uv_break]
""" . replace ( ' n ' , '' ) # English is still experimental.
params_refine_text = {
'prompt' : '[oral_2][laugh_0][break_4]'
}
audio_array_cn = chat . infer ( inputs_cn , params_refine_text = params_refine_text )
audio_array_en = chat . infer ( inputs_en , params_refine_text = params_refine_text )Para un clip de audio de 30 segundos, se requieren al menos 4 GB de memoria GPU. Para la GPU 4090D, puede generar audio correspondiente a aproximadamente 7 tokens semánticos por segundo. El factor de tiempo real (RTF) ronda el 0,65.
Este es un problema que suele ocurrir con los modelos autorregresivos (para corteza y valle). Generalmente es difícil de evitar. Se pueden probar varias muestras para encontrar un resultado adecuado.
En el modelo lanzado actualmente, las únicas unidades de control a nivel de token son [risas], [uv_break] y [lbreak]. En versiones futuras, es posible que abramos modelos de código abierto con capacidades adicionales de control emocional.


