Implementación oficial de "Imagen salpicada: reconstrucción 3D ultrarrápida de vista única" (CVPR 2024)
[16 de abril de 2024] Varias actualizaciones importantes del proyecto desde el primer lanzamiento:
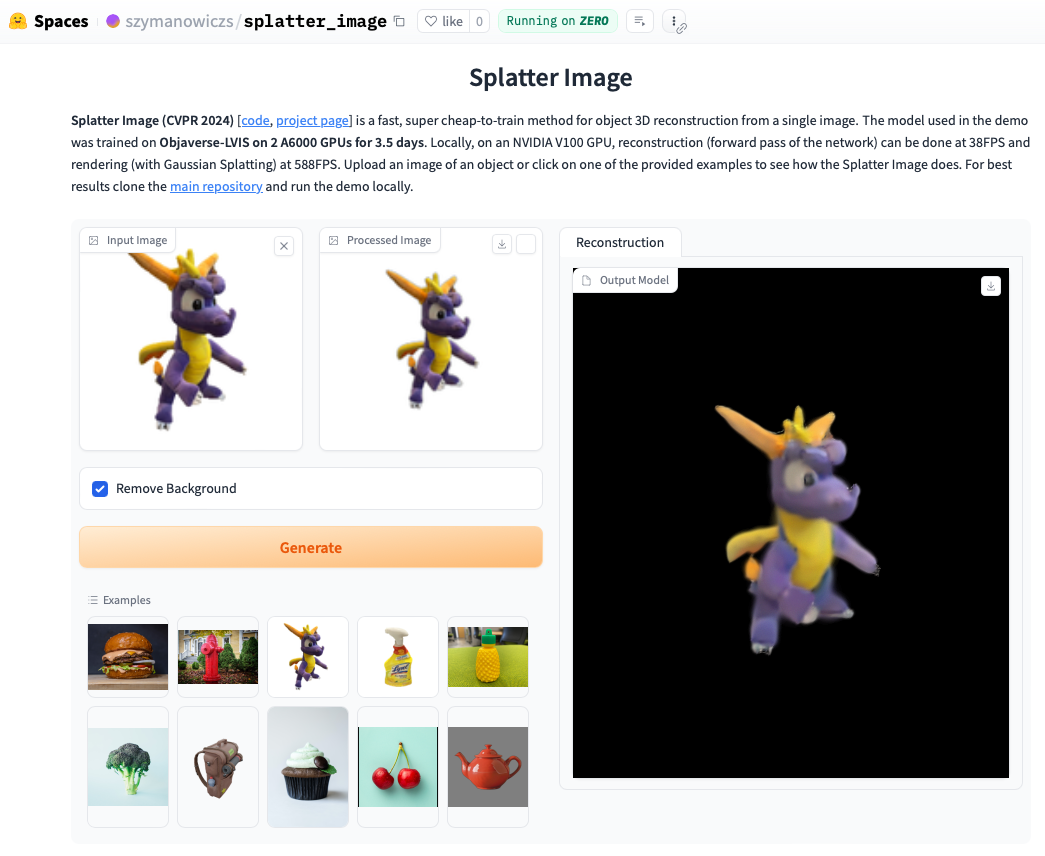
Consulte la demostración en línea. Ejecutar la demostración localmente será incluso más rápido y podrá ver los bucles renderizados con Gaussian Splatting (a diferencia del objeto .ply extraído que puede mostrar artefactos). Para ejecutar la demostración localmente, simplemente siga las instrucciones de instalación a continuación y luego llame:
python gradio_app.py
conda create --name splatter-image
conda activate splatter-image
Instale Pytorch siguiendo las instrucciones oficiales. La combinación de Pytorch/Python/Pytorch3D que se verificó que funciona es:
Instalar otros requisitos:
pip install -r requirements.txt
Instale el renderizador Gaussian Splatting, es decir, la biblioteca para representar una nube de puntos gaussianos en una imagen. Para hacerlo, extraiga el repositorio Gaussian Splatting y, con su entorno conda activado, ejecute pip install submodules/diff-gaussian-rasterization . Deberá cumplir con los requisitos de hardware y software. Hicimos toda nuestra experimentación en una GPU NVIDIA A6000 y mediciones de velocidad en una GPU NVIDIA V100.
Si desea entrenar con datos CO3D, deberá instalar Pytorch3D 0.7.2. Vea las instrucciones aquí. Se recomienda instalar con pip desde un binario prediseñado. Encuentre un binario compatible aquí e instálelo con pip . Por ejemplo, con Python 3.8, Pytorch 1.13.0, CUDA 11.6 ejecute pip install --no-index --no-cache-dir pytorch3d -f https://anaconda.org/pytorch3d/pytorch3d/0.7.2/download/linux-64/pytorch3d-0.7.2-py38_cu116_pyt1130.tar.bz2 .
Para capacitar/evaluar las clases de ShapeNet-SRN (automóviles, sillas), descargue srn_*.zip (* = automóviles o sillas) de la carpeta de datos de PixelNeRF. Descomprima el archivo de datos y cambie SHAPENET_DATASET_ROOT en datasets/srn.py a la carpeta principal de la carpeta descomprimida. Por ejemplo, si su estructura de carpetas es: /home/user/SRN/srn_cars/cars_train , en datasets/srn.py establezca SHAPENET_DATASET_ROOT="/home/user/SRN" . No se necesita ningún preprocesamiento adicional.
Para capacitación/evaluación sobre CO3D, descargue las clases de hidrante y osito de peluche de la versión de CO3D. Para hacerlo, ejecute los siguientes comandos:
git clone https://github.com/facebookresearch/co3d.git
cd co3d
mkdir DOWNLOAD_FOLDER
python ./co3d/download_dataset.py --download_folder DOWNLOAD_FOLDER --download_categories hydrant,teddybear
A continuación, configure CO3D_RAW_ROOT en su DOWNLOAD_FOLDER en data_preprocessing/preoprocess_co3d.py . Configure CO3D_OUT_ROOT en el lugar donde desea almacenar datos preprocesados. Correr
python -m data_preprocessing.preprocess_co3d
y establezca CO3D_DATASET_ROOT:=CO3D_OUT_ROOT .
Para ShapeNet de múltiples categorías utilizamos el conjunto de datos ShapeNet 64x64 de NMR alojado por autores de DVR que se puede descargar aquí. Descomprima la carpeta y configure NMR_DATASET_ROOT en el directorio que contiene las carpetas de subcategorías después de descomprimir. En otras palabras, el directorio NMR_DATASET_ROOT debe contener las carpetas 02691156 , 02828884 , 02933112 , etc.
Para entrenar en Objaverse utilizamos representaciones de Zero-1-to-3 que se pueden descargar con el siguiente comando:
wget https://tri-ml-public.s3.amazonaws.com/datasets/views_release.tar.gz
Descargo de responsabilidad: tenga en cuenta que las representaciones se generan con Objaverse. Las representaciones en su conjunto se publican bajo la licencia ODC-By 1.0. Las licencias para la representación de objetos individuales se publican bajo la misma licencia creative commons que se encuentran en Objaverse.
Además, descargue lvis-annotations-filtered.json del repositorio de modelos. Este json que contiene la lista de ID de objetos del subconjunto LVIS. Estos activos son de mayor calidad.
Configure OBJAVERSE_ROOT en datasets/objaverse.py en el directorio de la carpeta descomprimida con representaciones, y configure OBJAVERSE_LVIS_ANNOTATION_PATH en el mismo archivo en el directorio del archivo .json descargado.
Tenga en cuenta que el conjunto de datos de Objaverse está destinado únicamente a entrenamiento y validación. No tiene un subconjunto de prueba.
Para evaluar el modelo entrenado en Objaverse utilizamos el conjunto de datos de objetos escaneados de Google para garantizar que no se superponga con el conjunto de entrenamiento. Descargue representaciones proporcionadas por Free3D. Descomprima la carpeta descargada y configure GSO_ROOT en datasets/gso.py en el directorio de la carpeta descomprimida.
Tenga en cuenta que el conjunto de datos de Objetos escaneados de Google no está diseñado para capacitación. Se utiliza para probar el modelo entrenado en Objaverse.
Los modelos previamente entrenados para todos los conjuntos de datos ahora están disponibles a través de Huggingface Models. Si solo desea ejecutar una evaluación cualitativa/cuantitativa, no necesita descargarlas manualmente, se usarán automáticamente si ejecuta el script de evaluación (ver más abajo).
También puede descargarlos manualmente si lo desea, haciendo clic manualmente en el botón de descarga en la página de archivos del modelo Huggingface. Descargue el archivo de configuración con él y consulte eval.py para saber cómo se carga el modelo.
Una vez que haya descargado el conjunto de datos relevante, la evaluación se puede ejecutar con
python eval.py $dataset_name
$dataset_name es el nombre del conjunto de datos. Apoyamos:
gso (Objetos escaneados de Google),objaverse (Objaverso-LVIS),nmr (ShapeNet multicategoría),hydrants (hidrantes de CO3D),teddybears (ositos de peluche CO3D),cars (coches ShapeNet),chairs (sillas ShapeNet). El código descargará automáticamente el modelo relevante para el conjunto de datos solicitado.También puedes entrenar tus propios modelos y evaluarlos con
python eval.py $dataset_name --experiment_path $experiment_path
$experiment_path debe contener un archivo model_latest.pth y una carpeta .hydra con config.yaml dentro.
Para evaluar la división de validación, llame con la opción --split val .
Para guardar renderizados de los objetos con la cámara moviéndose en un bucle, llame con la opción --split vis . Con esta opción, las puntuaciones cuantitativas no se devuelven ya que las imágenes reales no están disponibles en todos los conjuntos de datos.
Puede configurar cuántos objetos guardar renderizados con la opción --save_vis . Puede establecer dónde guardar los renderizados con la opción --out_folder .
Los modelos de vista única se entrenan en dos etapas, primero sin LPIPS (la mayor parte del entrenamiento) y luego se ajustan con LPIPS.
python train_network.py +dataset=$dataset_name
opt.pretrained_ckpt (de forma predeterminada, establecido en nulo). python train_network.py +dataset=$dataset_name +experiment=$lpips_experiment_name
$lpips_experiment_name usar depende del conjunto de datos. Si $dataset_name está en [autos,hidrantes,ositos de peluche], use lpips_100k.yaml. Si $dataset_name son sillas, use lpips_200k.yaml. Si $dataset_name es nmr, use lpips_nmr.yaml. Si $dataset_name es objaverse, use lpips_objaverse.yaml. Recuerde colocar el directorio del modelo de la primera etapa en el archivo .yaml apropiado antes de iniciar la segunda etapa.Para entrenar una ejecución de modelo de 2 vistas:
python train_network.py +dataset=cars cam_embd=pose_pos data.input_images=2 opt.imgs_per_obj=5
El bucle de entrenamiento se implementa en train_network.py y el código de evaluación está en eval.py Los conjuntos de datos se implementan en datasets/srn.py y datasets/co3d.py . El modelo se implementa en scene/gaussian_predictor.py . La llamada al renderizador se puede encontrar en gaussian_renderer/__init__.py .
El rasterizador gaussiano asume el orden de fila principal de las matrices de transformación de cuerpo rígido, es decir, que los vectores de posición son vectores de fila. También requiere cámaras en la convención COLMAP/OpenCV, es decir, que x apunte hacia la derecha, y hacia abajo y z lejos de la cámara (hacia adelante).
@inproceedings{szymanowicz24splatter,
title={Splatter Image: Ultra-Fast Single-View 3D Reconstruction},
author={Stanislaw Szymanowicz and Christian Rupprecht and Andrea Vedaldi},
year={2024},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
}
S. Szymanowicz cuenta con el apoyo de una Beca de Asociaciones de Formación Doctoral (DTP) EP/R513295/1 de EPSRC y la Beca Oxford-Ashton. A. Vedaldi cuenta con el respaldo de ERC-CoG UNION 101001212. Agradecemos a Eldar Insafutdinov por su ayuda con los requisitos de instalación.


