Un marco para entrenar modelos de bases multimodales de cualquier tipo.
Escalable. De código abierto. A través de decenas de modalidades y tareas.
EPFL-Apple
Website | BibTeX | ? Demo
Implementación oficial y modelos previamente entrenados para:
4M: Modelado enmascarado masivamente multimodal , NeurIPS 2023 (Spotlight)
David Mizrahi*, Roman Bachmann*, Oğuzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, Amir Zamir
4M-21: Un modelo de visión universal para decenas de tareas y modalidades , NeurIPS 2024
Roman Bachmann*, Oğuzhan Fatih Kar*, David Mizrahi*, Ali Garjani, Mingfei Gao, David Griffiths, Jiaming Hu, Afshin Dehghan, Amir Zamir
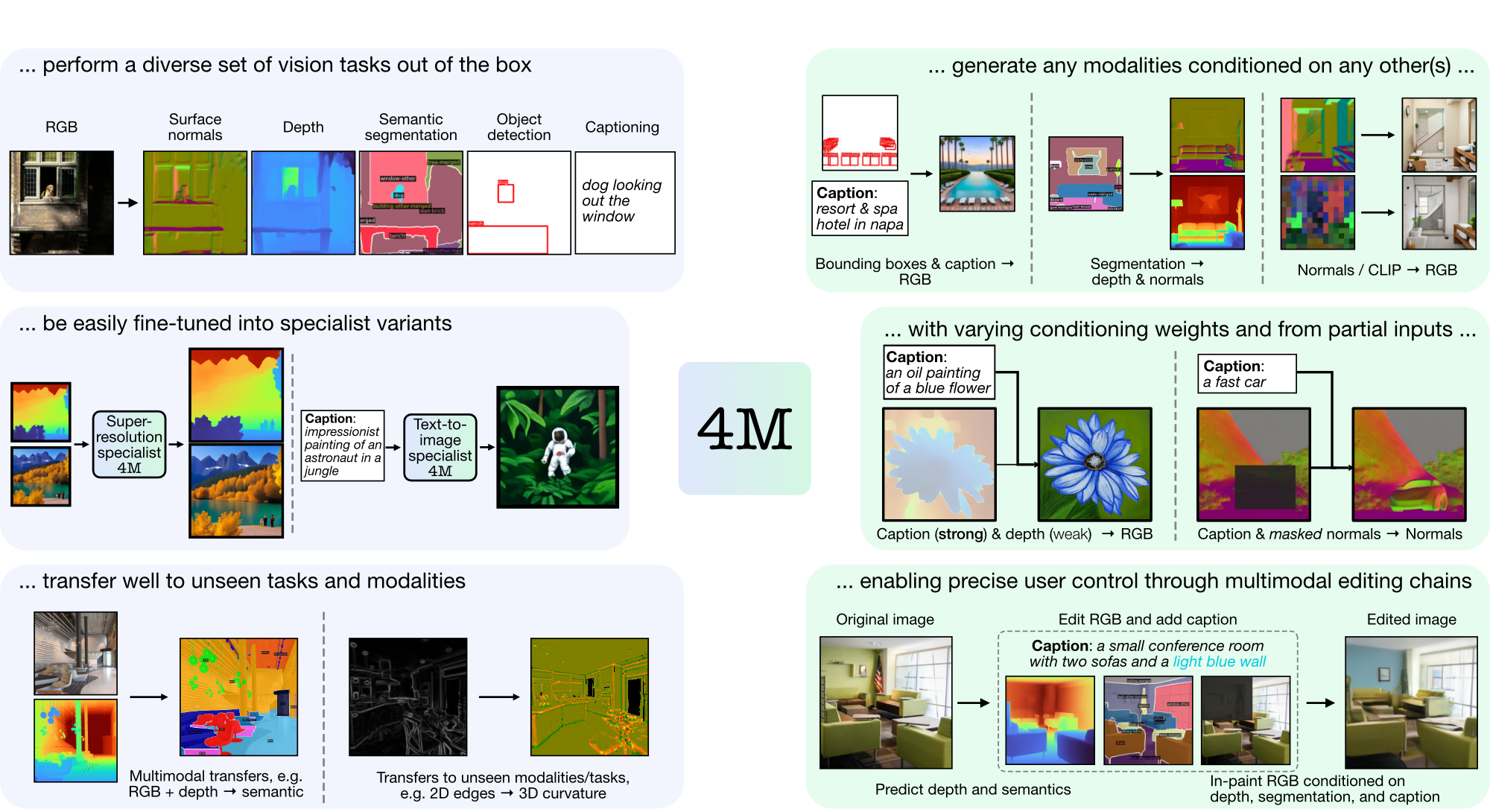
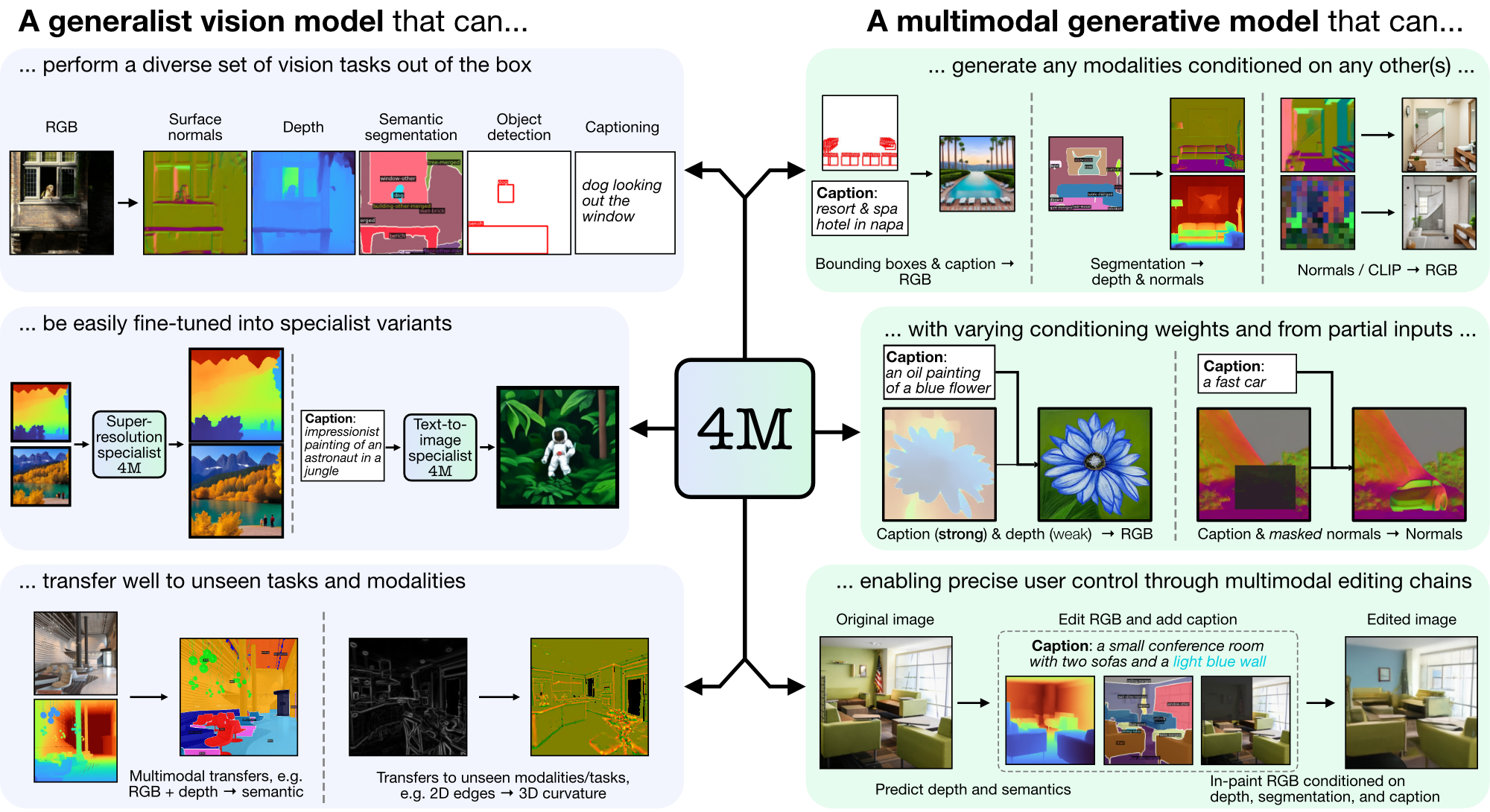
4M es un marco para entrenar modelos básicos "cualquiera a cualquiera", utilizando tokenización y enmascaramiento para escalar a muchas modalidades diversas. Los modelos entrenados con 4M pueden realizar una amplia gama de tareas de visión, transferirse bien a tareas y modalidades invisibles y son modelos generativos multimodales flexibles y orientables. Estamos lanzando código y modelos para "4M: Modelado enmascarado masivamente multimodal" (aquí denominado 4M-7), así como "4M-21: Un modelo de visión cualquiera para decenas de tareas y modalidades" (aquí denominado 4M -21).
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install --upgrade pip # enable PEP 660 support
pip install -e .
# Run in Python shell
import torch
print(torch.cuda.is_available()) # Should return True
Si CUDA no está disponible, considere reinstalar PyTorch siguiendo las instrucciones de instalación oficiales. Del mismo modo, si desea instalar xFormers (opcional, para tokenizadores más rápidos), siga su archivo README para asegurarse de que la versión CUDA sea correcta.
Proporcionamos un contenedor de demostración para comenzar rápidamente a usar modelos 4M para tareas de generación RGB para todos o {títulos, cuadros delimitadores} para todos. Por ejemplo, para generar todas las modalidades a partir de una entrada RGB determinada, llame a:
from fourm . demo_4M_sampler import Demo4MSampler , img_from_url
sampler = Demo4MSampler ( fm = 'EPFL-VILAB/4M-21_XL' ). cuda ()
img = img_from_url ( 'https://storage.googleapis.com/four_m_site/images/demo_rgb.png' ) # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler ({ 'rgb@224' : img . cuda ()}, seed = None )
sampler . plot_modalities ( preds , save_path = None )Debería esperar ver un resultado como el siguiente:


Para realizar la generación de subtítulos para todos, puede reemplazar la entrada del muestreador por: preds = sampler({'caption': 'A lake house with a boat in front [S_1]'}) . Para obtener una lista de los modelos 4M disponibles, consulte el zoológico de modelos a continuación y consulte README_GENERATION.md para obtener más instrucciones sobre la generación.
Consulte README_DATA.md para obtener instrucciones sobre cómo preparar conjuntos de datos multimodales alineados.
Consulte README_TOKENIZATION.md para obtener instrucciones sobre cómo entrenar tokenizadores de modalidades específicas.
Consulte README_TRAINING.md para obtener instrucciones sobre cómo entrenar modelos 4M.
Consulte README_GENERATION.md para obtener instrucciones sobre cómo utilizar los modelos 4M para inferencia/generación. También proporcionamos un cuaderno de generación que contiene ejemplos de inferencia 4M, específicamente realizando generación de imágenes condicionales y tareas de visión comunes (es decir, RGB a todos).
Proporcionamos puntos de control de tokenizador y 4M como tensores de seguridad, y también ofrecemos una carga sencilla a través de Hugging Face Hub.
| Modelo | # Mod. | Conjuntos de datos | # parámetros | configuración | Pesos |
|---|---|---|---|---|---|
| 4M-B | 7 | CC12M | 198M | configuración | Punto de control/HF Hub |
| 4M-B | 7 | COYO700M | 198M | configuración | Punto de control/HF Hub |
| 4M-B | 21 | CC12M+COYO700M+C4 | 198M | configuración | Punto de control/HF Hub |
| 4M-L | 7 | CC12M | 705M | configuración | Punto de control/HF Hub |
| 4M-L | 7 | COYO700M | 705M | configuración | Punto de control/HF Hub |
| 4M-L | 21 | CC12M+COYO700M+C4 | 705M | configuración | Punto de control/HF Hub |
| 4M-XL | 7 | CC12M | 2.8B | configuración | Punto de control/HF Hub |
| 4M-XL | 7 | COYO700M | 2.8B | configuración | Punto de control/HF Hub |
| 4M-XL | 21 | CC12M+COYO700M+C4 | 2.8B | configuración | Punto de control/HF Hub |
Para cargar modelos desde Hugging Face Hub:
from fourm . models . fm import FM
fm7b_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_CC12M' )
fm7b_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_B_COYO700M' )
fm21b = FM . from_pretrained ( 'EPFL-VILAB/4M-21_B' )
fm7l_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_CC12M' )
fm7l_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_L_COYO700M' )
fm21l = FM . from_pretrained ( 'EPFL-VILAB/4M-21_L' )
fm7xl_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_CC12M' )
fm7xl_coyo = FM . from_pretrained ( 'EPFL-VILAB/4M-7_XL_COYO700M' )
fm21xl = FM . from_pretrained ( 'EPFL-VILAB/4M-21_XL' )Para cargar los puntos de control manualmente, primero descargue los archivos de tensores de seguridad de los enlaces anteriores y llame a:
from fourm . utils import load_safetensors
from fourm . models . fm import FM
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
fm = FM ( config = config )
fm . load_state_dict ( ckpt )Estos modelos se inicializaron con los modelos estándar 4M-7 CC12M, pero continuaron entrenándose con una combinación de modalidades fuertemente sesgada hacia la entrada de texto. Aún pueden realizar todas las demás tareas, pero funcionan mejor en la generación de texto a imagen en comparación con los modelos no ajustados.
| Modelo | # Mod. | Conjuntos de datos | # parámetros | configuración | Pesos |
|---|---|---|---|---|---|
| 4M-T2I-B | 7 | CC12M | 198M | configuración | Punto de control/HF Hub |
| 4M-T2I-L | 7 | CC12M | 705M | configuración | Punto de control/HF Hub |
| 4M-T2I-XL | 7 | CC12M | 2.8B | configuración | Punto de control/HF Hub |
Para cargar modelos desde Hugging Face Hub:
from fourm . models . fm import FM
fm7b_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_B_CC12M' )
fm7l_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_L_CC12M' )
fm7xl_t2i_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-T2I_XL_CC12M' )La carga manual desde los puntos de control se realiza de la misma manera que arriba para los modelos 4M básicos.
| Modelo | # Mod. | Conjuntos de datos | # parámetros | configuración | Pesos |
|---|---|---|---|---|---|
| 4M-SR-L | 7 | CC12M | 198M | configuración | Punto de control/HF Hub |
Para cargar modelos desde Hugging Face Hub:
from fourm . models . fm import FM
fm7l_sr_cc12m = FM . from_pretrained ( 'EPFL-VILAB/4M-7-SR_L_CC12M' )La carga manual desde los puntos de control se realiza de la misma manera que arriba para los modelos 4M básicos.
| Modalidad | Resolución | Número de fichas | Tamaño del libro de códigos | Decodificador de difusión | Pesos |
|---|---|---|---|---|---|
| RGB | 224-448 | 196-784 | 16k | ✓ | Punto de control/HF Hub |
| Profundidad | 224-448 | 196-784 | 8k | ✓ | Punto de control/HF Hub |
| Normales | 224-448 | 196-784 | 8k | ✓ | Punto de control/HF Hub |
| Bordes (Canny, SAM) | 224-512 | 196-1024 | 8k | ✓ | Punto de control/HF Hub |
| Segmentación semántica COCO | 224-448 | 196-784 | 4k | ✗ | Punto de control/HF Hub |
| CLIP-B/16 | 224-448 | 196-784 | 8k | ✗ | Punto de control/HF Hub |
| DINOV2-B/14 | 224-448 | 256-1024 | 8k | ✗ | Punto de control/HF Hub |
| DINOV2-B/14 (global) | 224 | 16 | 8k | ✗ | Punto de control/HF Hub |
| ImageBind-H/14 | 224-448 | 256-1024 | 8k | ✗ | Punto de control/HF Hub |
| ImageBind-H/14 (global) | 224 | 16 | 8k | ✗ | Punto de control/HF Hub |
| Instancias SAM | - | 64 | 1k | ✗ | Punto de control/HF Hub |
| Poses humanas 3D | - | 8 | 1k | ✗ | Punto de control/HF Hub |
Para cargar modelos desde Hugging Face Hub:
from fourm . vq . vqvae import VQVAE , DiVAE
# 4M-7 modalities
tok_rgb = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_rgb_16k_224-448' )
tok_depth = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_depth_8k_224-448' )
tok_normal = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_normal_8k_224-448' )
tok_semseg = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_semseg_4k_224-448' )
tok_clip = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_CLIP-B16_8k_224-448' )
# 4M-21 modalities
tok_edge = DiVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_edge_8k_224-512' )
tok_dinov2 = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14_8k_224-448' )
tok_dinov2_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_DINOv2-B14-global_8k_16_224' )
tok_imagebind = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14_8k_224-448' )
tok_imagebind_global = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_ImageBind-H14-global_8k_16_224' )
sam_instance = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_sam-instance_1k_64' )
human_poses = VQVAE . from_pretrained ( 'EPFL-VILAB/4M_tokenizers_human-poses_1k_8' )Para cargar los puntos de control manualmente, primero descargue los archivos de tensores de seguridad de los enlaces anteriores y llame a:
from fourm . utils import load_safetensors
from fourm . vq . vqvae import VQVAE , DiVAE
ckpt , config = load_safetensors ( '/path/to/checkpoint.safetensors' )
tok = VQVAE ( config = config ) # Or DiVAE for models with a diffusion decoder
tok . load_state_dict ( ckpt )El código de este repositorio se publica bajo la licencia Apache 2.0 como se encuentra en el archivo LICENCIA.
Los pesos de los modelos en este repositorio se publican bajo la licencia de Código de muestra que se encuentra en el archivo LICENSE_WEIGHTS.
Si encuentra útil este repositorio, considere citar nuestro trabajo:
@inproceedings{4m,
title={{4M}: Massively Multimodal Masked Modeling},
author={David Mizrahi and Roman Bachmann and O{u{g}}uzhan Fatih Kar and Teresa Yeo and Mingfei Gao and Afshin Dehghan and Amir Zamir},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
@article{4m21,
title={{4M-21}: An Any-to-Any Vision Model for Tens of Tasks and Modalities},
author={Roman Bachmann and O{u{g}}uzhan Fatih Kar and David Mizrahi and Ali Garjani and Mingfei Gao and David Griffiths and Jiaming Hu and Afshin Dehghan and Amir Zamir},
journal={arXiv 2024},
year={2024},
}


