system design 101
1.0.0
【 ?? YouTube | ? Boletín 】
Explicar sistemas complejos utilizando imágenes y términos simples.
Ya sea que se esté preparando para una entrevista de diseño de sistemas o simplemente desee comprender cómo funcionan los sistemas debajo de la superficie, esperamos que este repositorio lo ayude a lograrlo.
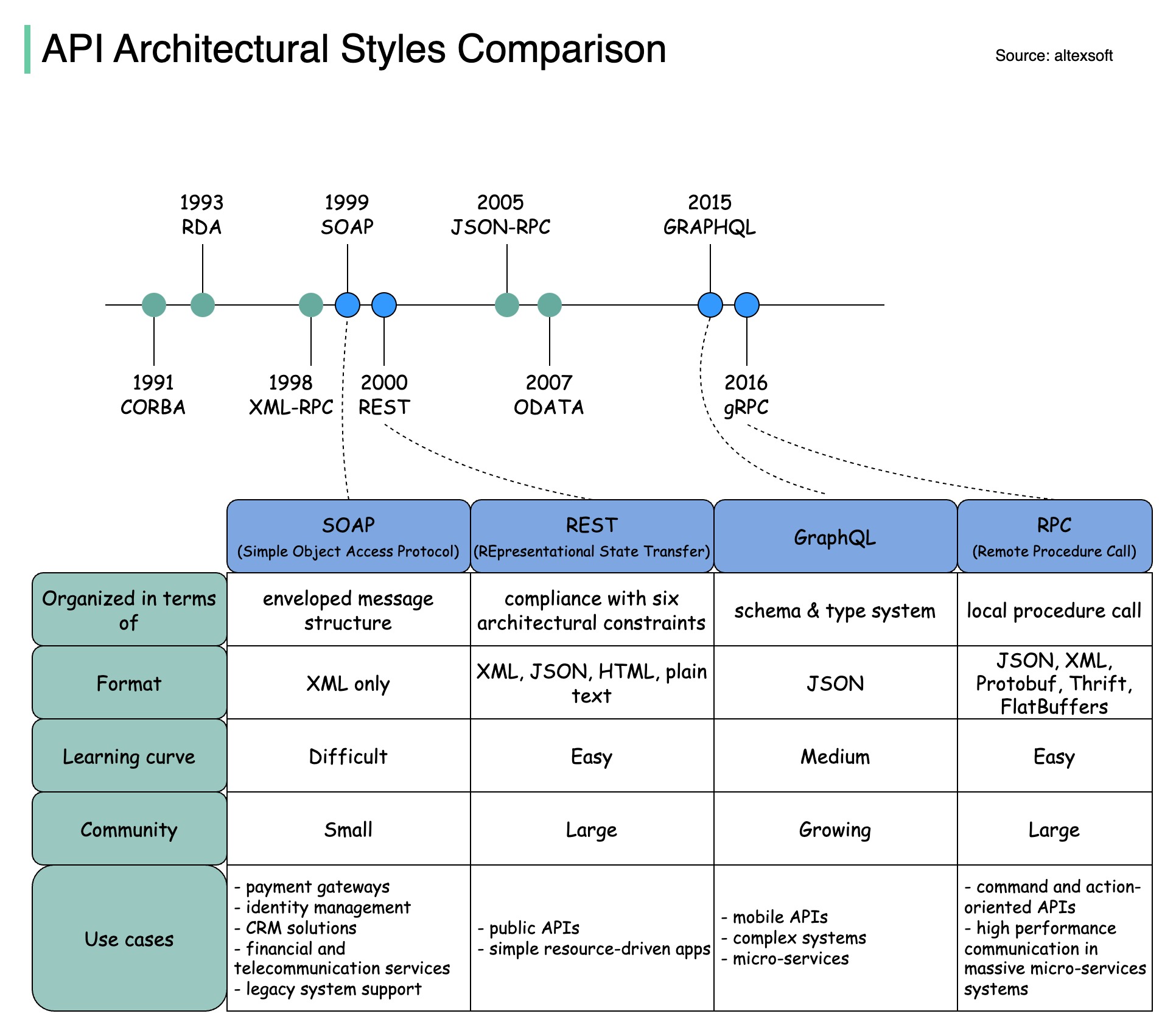
Los estilos de arquitectura definen cómo interactúan entre sí los diferentes componentes de una interfaz de programación de aplicaciones (API). Como resultado, garantizan eficiencia, confiabilidad y facilidad de integración con otros sistemas al proporcionar un enfoque estándar para diseñar y construir API. Estos son los estilos más utilizados:
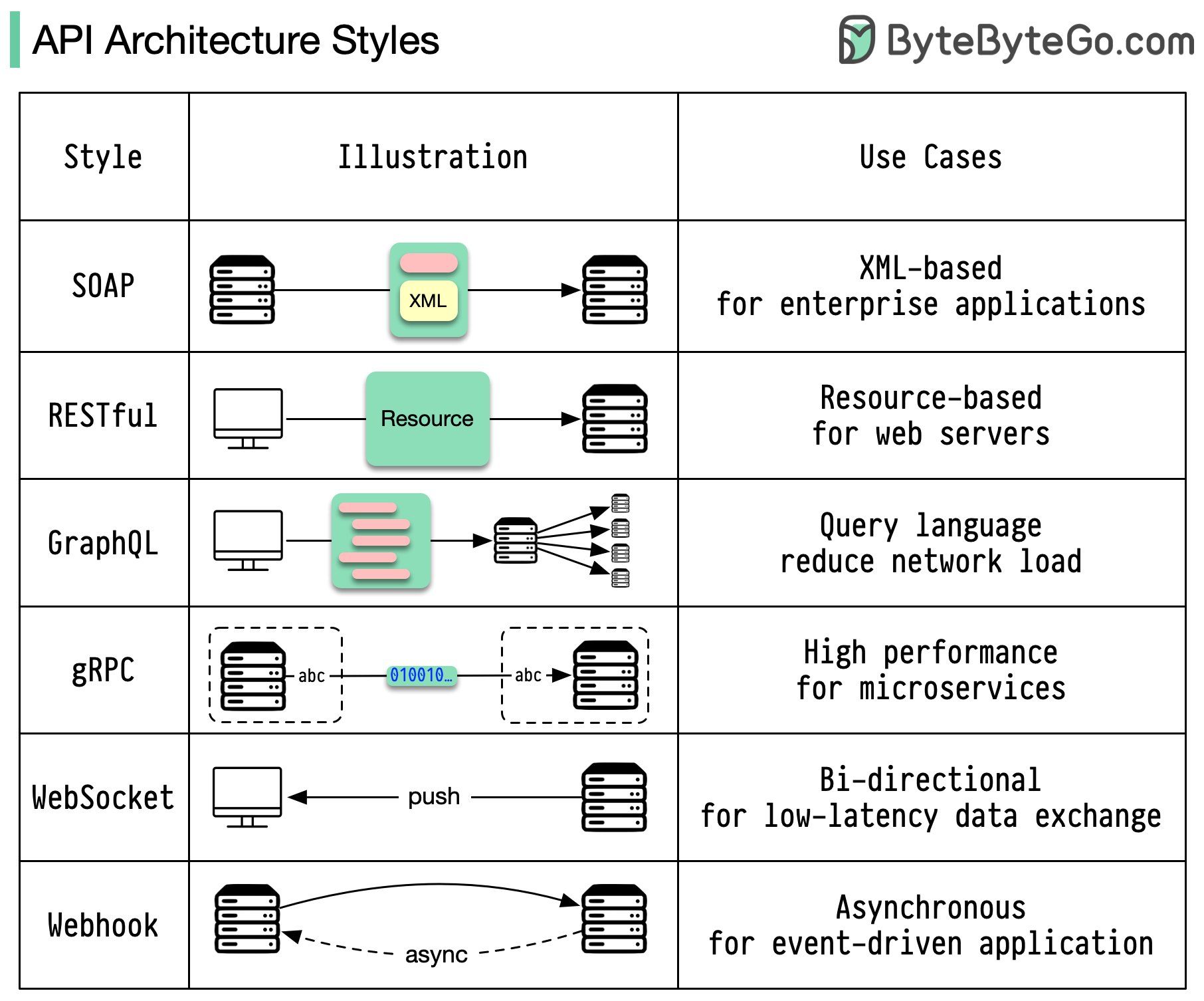
JABÓN:
Maduro, completo, basado en XML
Lo mejor para aplicaciones empresariales
Sosegado:
Métodos HTTP populares y fáciles de implementar
Ideal para servicios web
GráficoQL:
Lenguaje de consulta, solicitar datos específicos
Reduce la sobrecarga de la red, respuestas más rápidas
gRPC:
Búfers de protocolo modernos y de alto rendimiento
Adecuado para arquitecturas de microservicios
WebSocket:
Conexiones persistentes, bidireccionales y en tiempo real.
Perfecto para el intercambio de datos de baja latencia
Gancho web:
Devoluciones de llamadas HTTP controladas por eventos, asincrónicas
Notifica a los sistemas cuando ocurren eventos
Cuando se trata de diseño de API, REST y GraphQL tienen cada uno sus propias fortalezas y debilidades.
El siguiente diagrama muestra una comparación rápida entre REST y GraphQL.
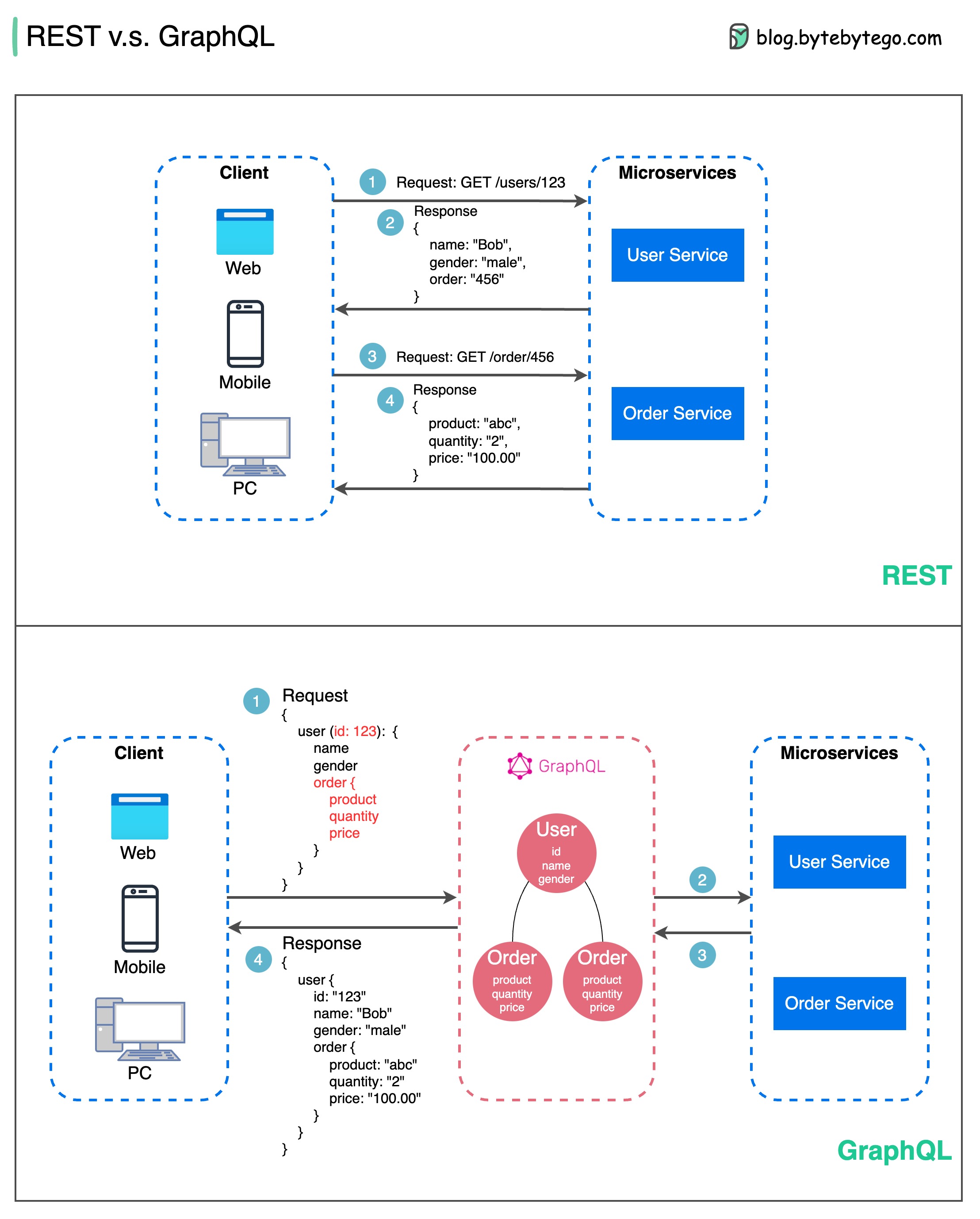
DESCANSAR
GrafoQL
La mejor elección entre REST y GraphQL depende de los requisitos específicos del equipo de desarrollo y aplicación. GraphQL es una buena opción para necesidades frontend complejas o que cambian con frecuencia, mientras que REST se adapta a aplicaciones donde se prefieren contratos simples y consistentes.
Ninguno de los enfoques API es una solución milagrosa. Es importante evaluar cuidadosamente los requisitos y las compensaciones para elegir el estilo correcto. Tanto REST como GraphQL son opciones válidas para exponer datos y potenciar aplicaciones modernas.
RPC (llamada a procedimiento remoto) se denomina " remoto " porque permite las comunicaciones entre servicios remotos cuando los servicios se implementan en diferentes servidores bajo una arquitectura de microservicio. Desde el punto de vista del usuario, actúa como una llamada a función local.
El siguiente diagrama ilustra el flujo de datos general para gRPC .
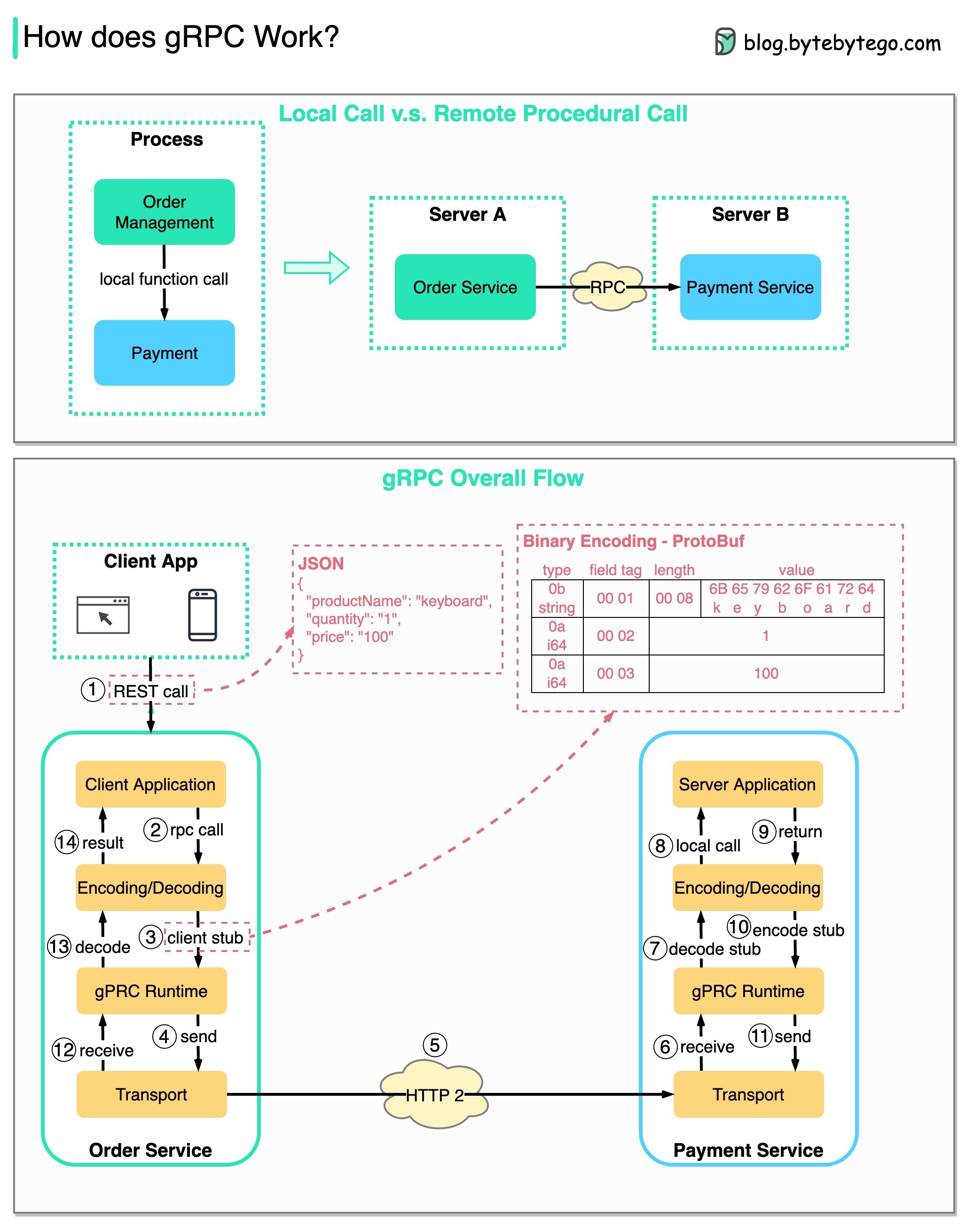
Paso 1: Se realiza una llamada REST desde el cliente. El cuerpo de la solicitud suele estar en formato JSON.
Pasos 2 a 4: el servicio de pedidos (cliente gRPC) recibe la llamada REST, la transforma y realiza una llamada RPC al servicio de pago. gRPC codifica el código auxiliar del cliente en un formato binario y lo envía a la capa de transporte de bajo nivel.
Paso 5: gRPC envía los paquetes a través de la red a través de HTTP2. Debido a la codificación binaria y las optimizaciones de red, se dice que gRPC es 5 veces más rápido que JSON.
Pasos 6 a 8: el servicio de pago (servidor gRPC) recibe los paquetes de la red, los decodifica e invoca la aplicación del servidor.
Pasos 9 a 11: el resultado se devuelve desde la aplicación del servidor, se codifica y se envía a la capa de transporte.
Pasos 12 a 14: el servicio de pedidos recibe los paquetes, los decodifica y envía el resultado a la aplicación cliente.
El siguiente diagrama muestra una comparación entre sondeo y Webhook.
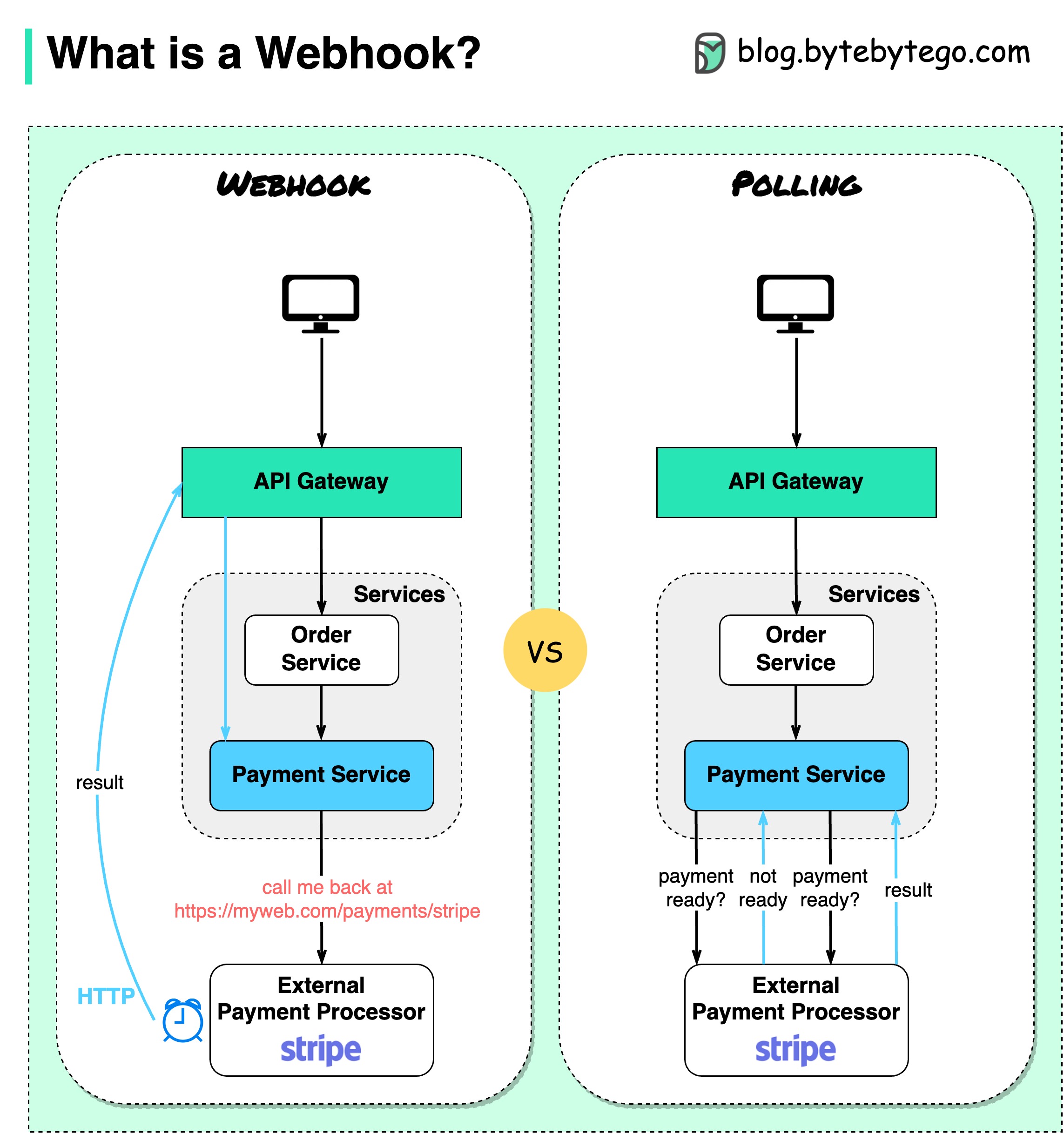
Supongamos que ejecutamos un sitio web de comercio electrónico. Los clientes envían pedidos al servicio de pedidos a través de la puerta de enlace API, que va al servicio de pago para las transacciones de pago. Luego, el servicio de pago habla con un proveedor de servicios de pago (PSP) externo para completar las transacciones.
Hay dos formas de manejar las comunicaciones con la PSP externa.
1. Encuesta breve
Después de enviar la solicitud de pago al PSP, el servicio de pago sigue preguntando al PSP sobre el estado del pago. Después de varias rondas, la PSP finalmente regresa con el estado.
Las encuestas breves tienen dos inconvenientes:
2. Webhook
Podemos registrar un webhook con el servicio externo. Significa: llámame a una determinada URL cuando tengas actualizaciones sobre la solicitud. Cuando el PSP haya completado el procesamiento, invocará la solicitud HTTP para actualizar el estado del pago.
De esta manera, se cambia el paradigma de programación y el servicio de pago ya no necesita desperdiciar recursos para sondear el estado del pago.
¿Qué pasa si la PSP nunca devuelve la llamada? Podemos configurar un trabajo de limpieza para verificar el estado del pago cada hora.
Los webhooks a menudo se denominan API inversas o API push porque el servidor envía solicitudes HTTP al cliente. Debemos prestar atención a 3 cosas al utilizar un webhook:
El siguiente diagrama muestra 5 trucos comunes para mejorar el rendimiento de la API.
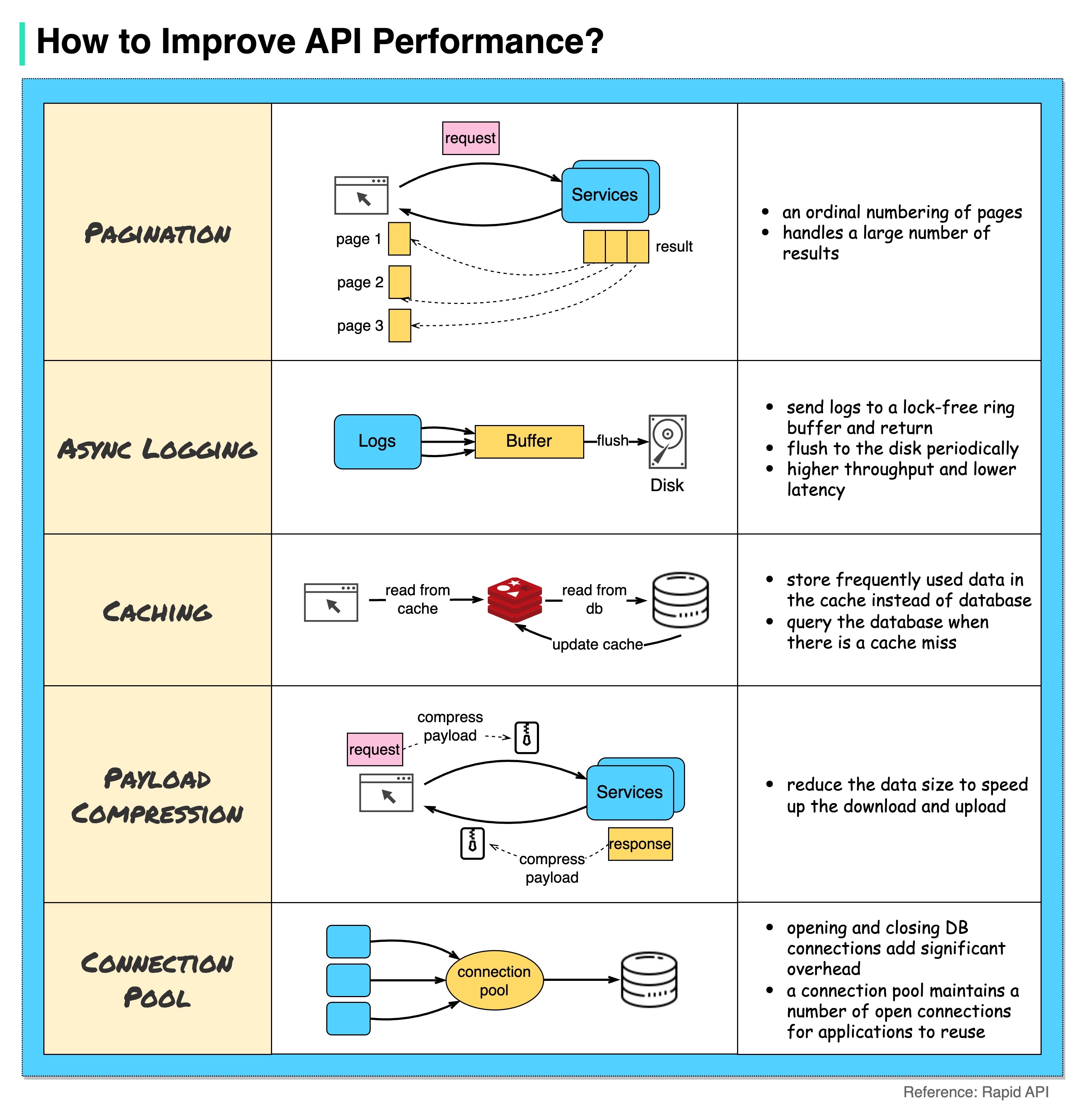
Paginación
Esta es una optimización común cuando el tamaño del resultado es grande. Los resultados se transmiten al cliente para mejorar la capacidad de respuesta del servicio.
Registro asincrónico
El registro sincrónico se ocupa del disco para cada llamada y puede ralentizar el sistema. El registro asincrónico envía primero los registros a un búfer sin bloqueo y regresa inmediatamente. Los registros se descargarán periódicamente en el disco. Esto reduce significativamente la sobrecarga de E/S.
Almacenamiento en caché
Podemos almacenar datos a los que se accede con frecuencia en un caché. El cliente puede consultar primero el caché en lugar de visitar la base de datos directamente. Si falta el caché, el cliente puede consultar desde la base de datos. Los cachés como Redis almacenan datos en la memoria, por lo que el acceso a los datos es mucho más rápido que la base de datos.
Compresión de carga útil
Las solicitudes y respuestas se pueden comprimir usando gzip, etc. para que el tamaño de los datos transmitidos sea mucho menor. Esto acelera la carga y descarga.
Grupo de conexiones
Al acceder a recursos, a menudo necesitamos cargar datos de la base de datos. Abrir las conexiones de base de datos de cierre agrega una sobrecarga significativa. Entonces deberíamos conectarnos a la base de datos a través de un grupo de conexiones abiertas. El grupo de conexiones es responsable de gestionar el ciclo de vida de la conexión.
¿Qué problema resuelve cada generación de HTTP?
El siguiente diagrama ilustra las características clave.
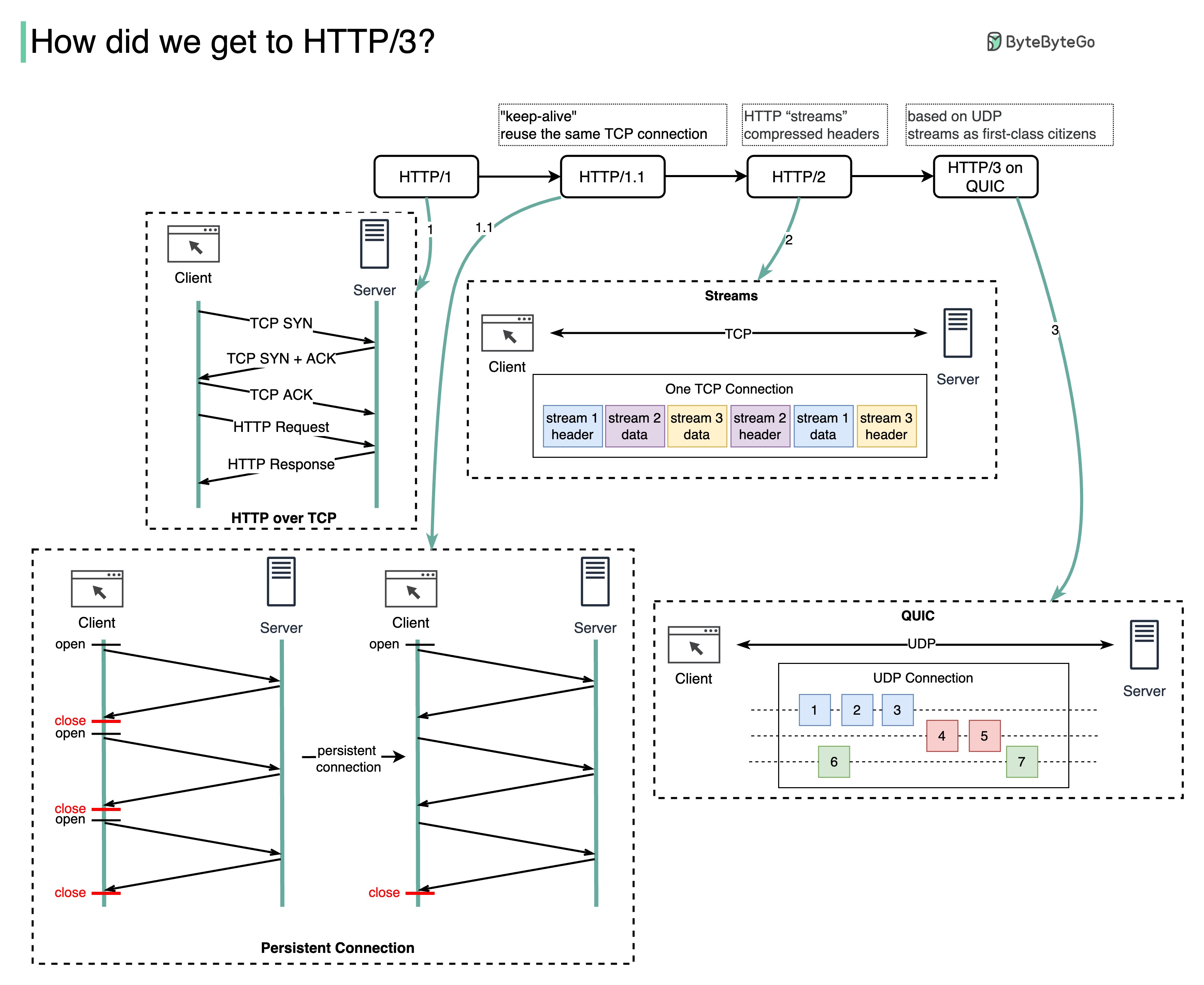
HTTP 1.0 se finalizó y documentó completamente en 1996. Cada solicitud al mismo servidor requiere una conexión TCP separada.
HTTP 1.1 se publicó en 1997. Una conexión TCP se puede dejar abierta para su reutilización (conexión persistente), pero no resuelve el problema de bloqueo HOL (cabeza de línea).
Bloqueo HOL: cuando se agota la cantidad de solicitudes paralelas permitidas en el navegador, las solicitudes posteriores deben esperar a que se completen las anteriores.
HTTP 2.0 se publicó en 2015. Aborda el problema de HOL mediante la multiplexación de solicitudes, lo que elimina el bloqueo de HOL en la capa de aplicación, pero HOL todavía existe en la capa de transporte (TCP).
Como puede ver en el diagrama, HTTP 2.0 introdujo el concepto de "flujos" HTTP: una abstracción que permite multiplexar diferentes intercambios HTTP en la misma conexión TCP. No es necesario enviar cada transmisión en orden.
El primer borrador de HTTP 3.0 se publicó en 2020. Es el sucesor propuesto de HTTP 2.0. Utiliza QUIC en lugar de TCP para el protocolo de transporte subyacente, eliminando así el bloqueo HOL en la capa de transporte.
QUIC se basa en UDP. Introduce a las corrientes como ciudadanos de primera clase en la capa de transporte. Los flujos QUIC comparten la misma conexión QUIC, por lo que no se requieren apretones de enlace adicionales ni inicios lentos para crear otros nuevos, pero los flujos QUIC se entregan de forma independiente, de modo que en la mayoría de los casos la pérdida de paquetes que afecta a un flujo no afecta a los demás.
El siguiente diagrama ilustra la comparación de la línea de tiempo de API y los estilos de API.
Con el tiempo, se lanzan diferentes estilos arquitectónicos de API. Cada uno de ellos tiene sus propios patrones de estandarización del intercambio de datos.
Puede consultar los casos de uso de cada estilo en el diagrama.
El siguiente diagrama muestra las diferencias entre el desarrollo de código primero y el desarrollo de API primero. ¿Por qué queremos considerar el primer diseño de API?
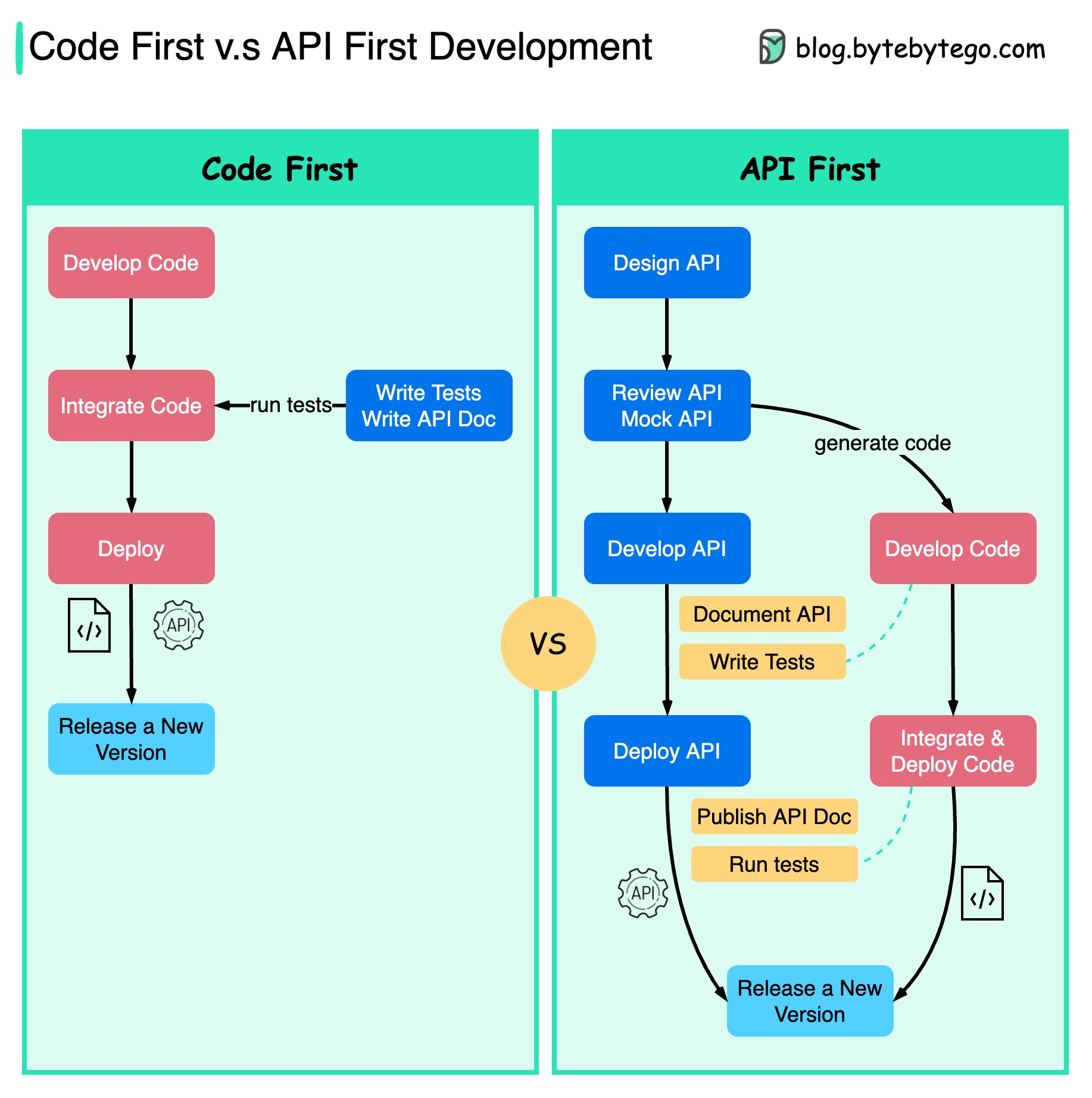
Es mejor pensar en la complejidad del sistema antes de escribir el código y definir cuidadosamente los límites de los servicios.
Podemos simular solicitudes y respuestas para validar el diseño de la API antes de escribir el código.
Los desarrolladores también están contentos con el proceso porque pueden centrarse en el desarrollo funcional en lugar de negociar cambios repentinos.
Se reduce la posibilidad de tener sorpresas hacia el final del ciclo de vida del proyecto.
Debido a que primero diseñamos la API, las pruebas se pueden diseñar mientras se desarrolla el código. En cierto modo, también tenemos TDD (Test Driven Design) cuando utilizamos el primer desarrollo de API.
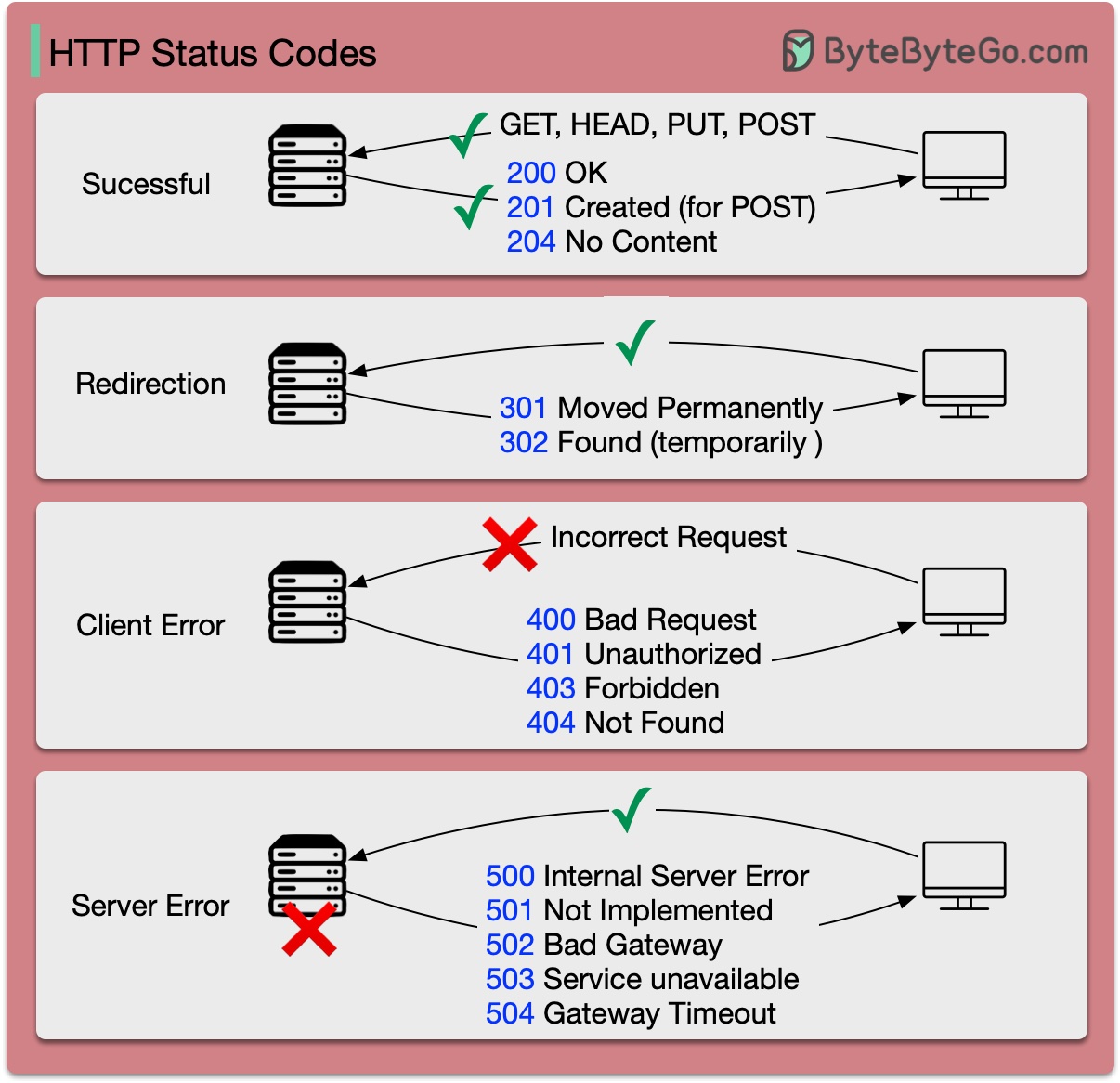
Los códigos de respuesta para HTTP se dividen en cinco categorías:
Informativo (100-199) Éxito (200-299) Redirección (300-399) Error del cliente (400-499) Error del servidor (500-599)
El siguiente diagrama muestra los detalles.
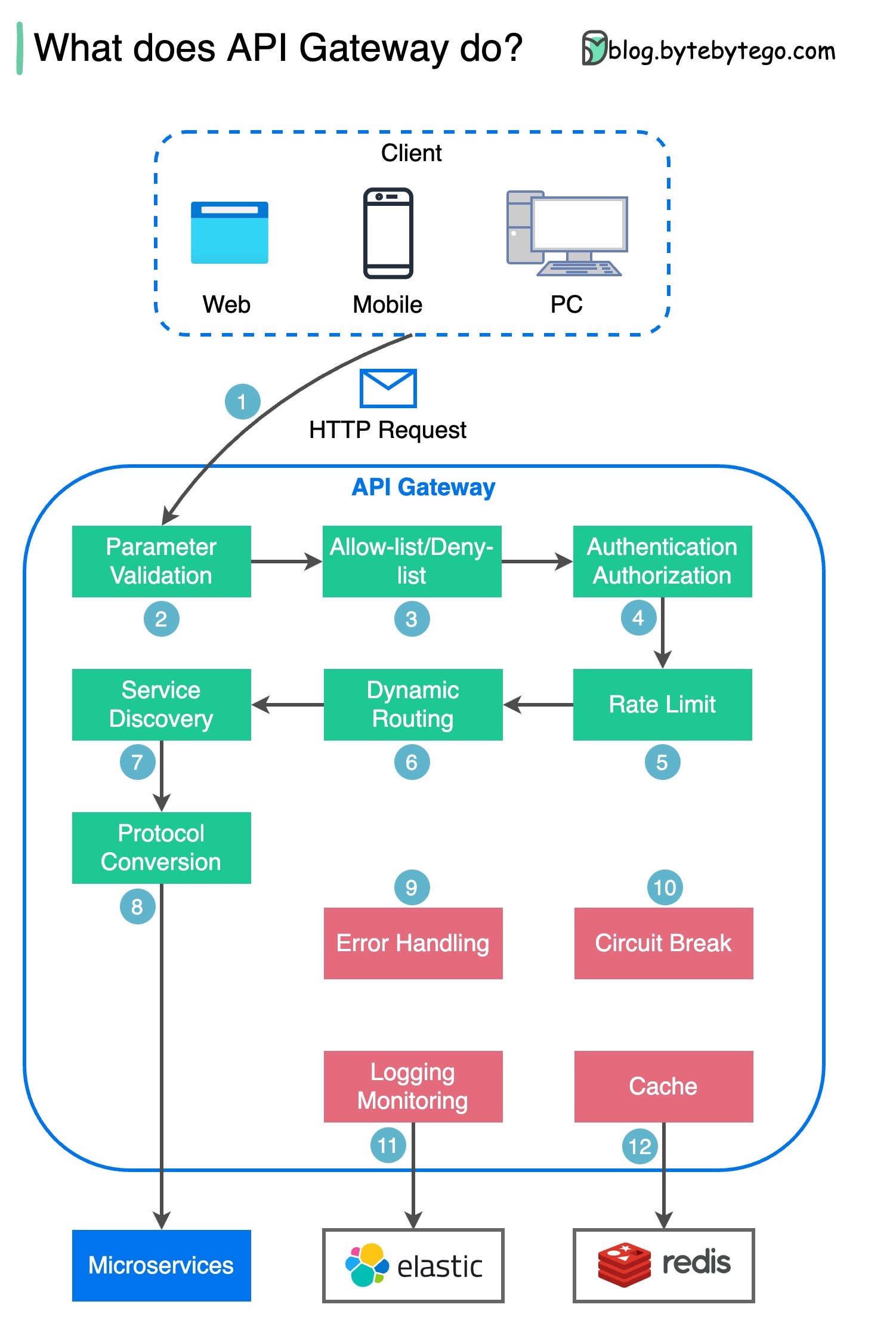
Paso 1: el cliente envía una solicitud HTTP a la puerta de enlace API.
Paso 2: la puerta de enlace API analiza y valida los atributos en la solicitud HTTP.
Paso 3: la puerta de enlace API realiza comprobaciones de la lista de permitidos/lista de denegados.
Paso 4: la puerta de enlace API se comunica con un proveedor de identidad para autenticación y autorización.
Paso 5: las reglas de limitación de tarifas se aplican a la solicitud. Si supera el límite, la solicitud se rechaza.
Pasos 6 y 7: ahora que la solicitud ha pasado las comprobaciones básicas, la puerta de enlace API encuentra el servicio relevante al que dirigirse mediante la coincidencia de ruta.
Paso 8: la puerta de enlace API transforma la solicitud en el protocolo apropiado y la envía a los microservicios de backend.
Pasos 9 a 12: la puerta de enlace API puede manejar los errores correctamente y se ocupa de las fallas si el error tarda más en recuperarse (ruptura del circuito). También puede aprovechar la pila ELK (Elastic-Logstash-Kibana) para registro y monitoreo. A veces almacenamos datos en caché en la puerta de enlace API.
El siguiente diagrama muestra diseños de API típicos con un ejemplo de carrito de compras.
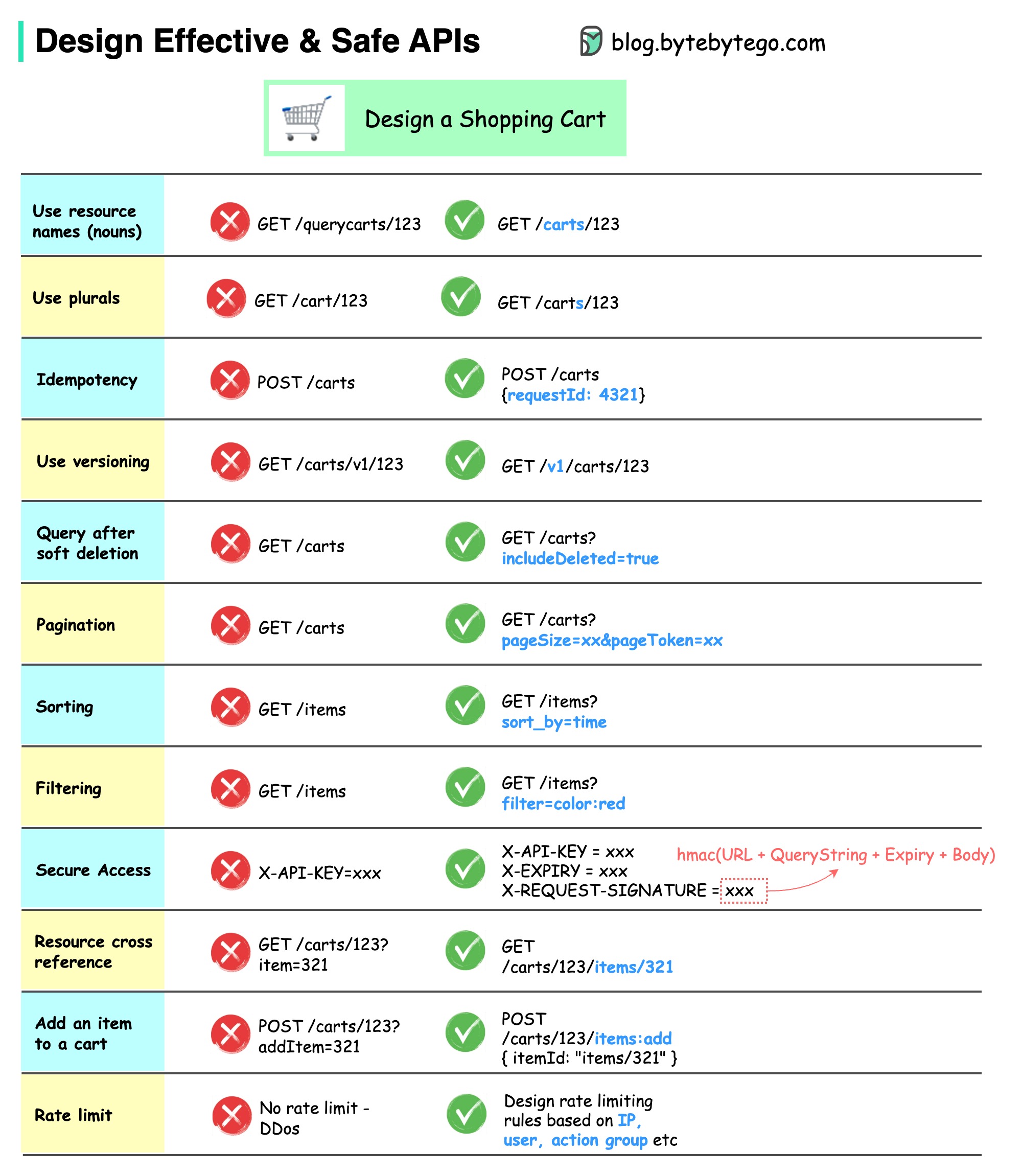
Tenga en cuenta que el diseño de API no es solo el diseño de rutas URL. La mayoría de las veces, debemos elegir los nombres de recursos, identificadores y patrones de ruta adecuados. Es igualmente importante diseñar campos de encabezado HTTP adecuados o diseñar reglas efectivas de limitación de velocidad dentro de la puerta de enlace API.
¿Cómo se envían los datos a través de la red? ¿Por qué necesitamos tantas capas en el modelo OSI?
El siguiente diagrama muestra cómo se encapsulan y desencapsulan los datos cuando se transmiten a través de la red.
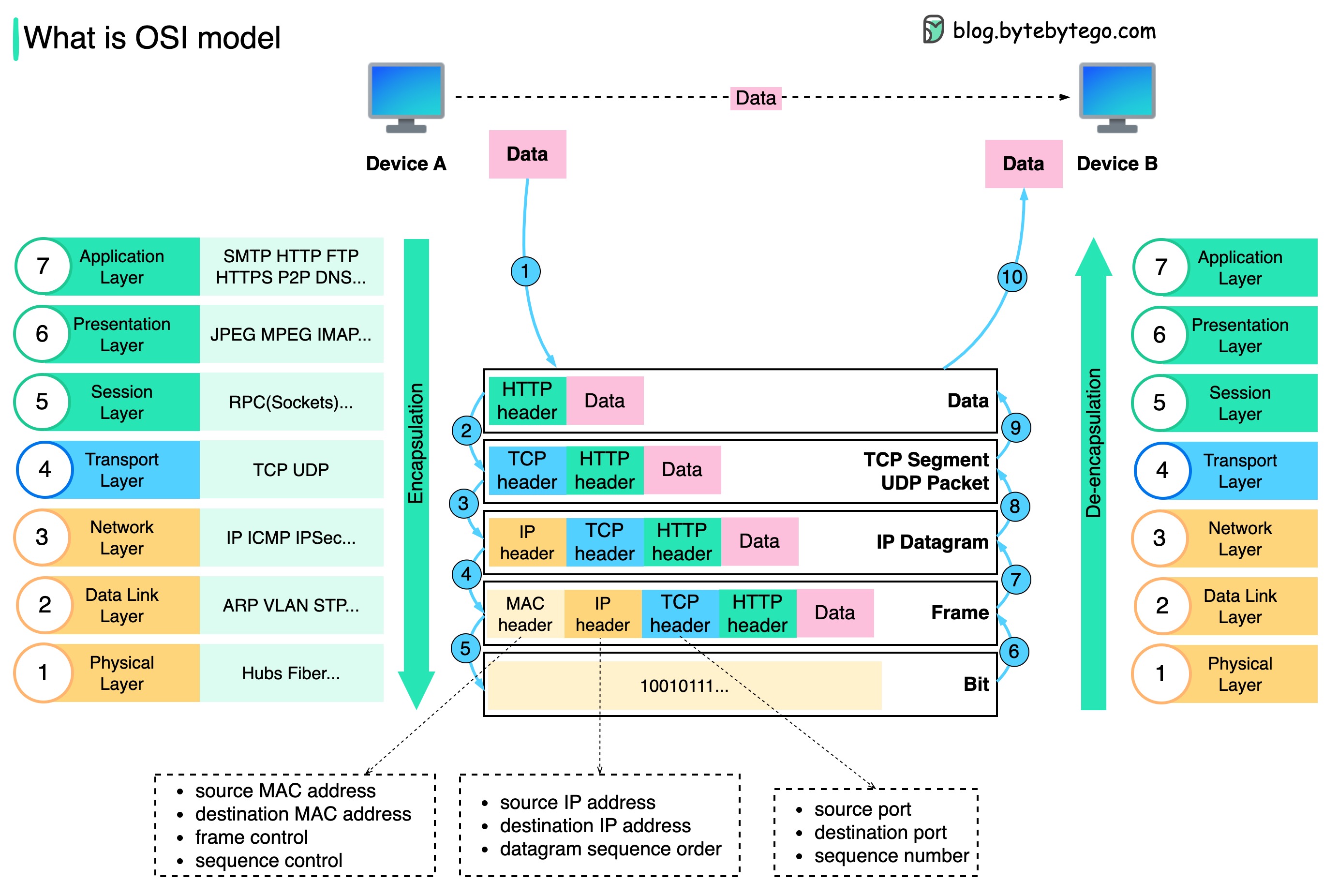
Paso 1: Cuando el Dispositivo A envía datos al Dispositivo B a través de la red mediante el protocolo HTTP, primero se agrega un encabezado HTTP en la capa de aplicación.
Paso 2: Luego se agrega un encabezado TCP o UDP a los datos. Está encapsulado en segmentos TCP en la capa de transporte. El encabezado contiene el puerto de origen, el puerto de destino y el número de secuencia.
Paso 3: Luego, los segmentos se encapsulan con un encabezado IP en la capa de red. El encabezado IP contiene las direcciones IP de origen/destino.
Paso 4: Al datagrama IP se le agrega un encabezado MAC en la capa de enlace de datos, con direcciones MAC de origen/destino.
Paso 5: Las tramas encapsuladas se envían a la capa física y se envían a través de la red en bits binarios.
Pasos 6 a 10: cuando el Dispositivo B recibe los bits de la red, realiza el proceso de desencapsulación, que es un procesamiento inverso del proceso de encapsulación. Los encabezados se eliminan capa por capa y, finalmente, el dispositivo B puede leer los datos.
Necesitamos capas en el modelo de red porque cada capa se centra en sus propias responsabilidades. Cada capa puede confiar en los encabezados para procesar instrucciones y no necesita conocer el significado de los datos de la última capa.
El siguiente diagrama muestra las diferencias entre un ??????? ????? y un ??????? ?????.
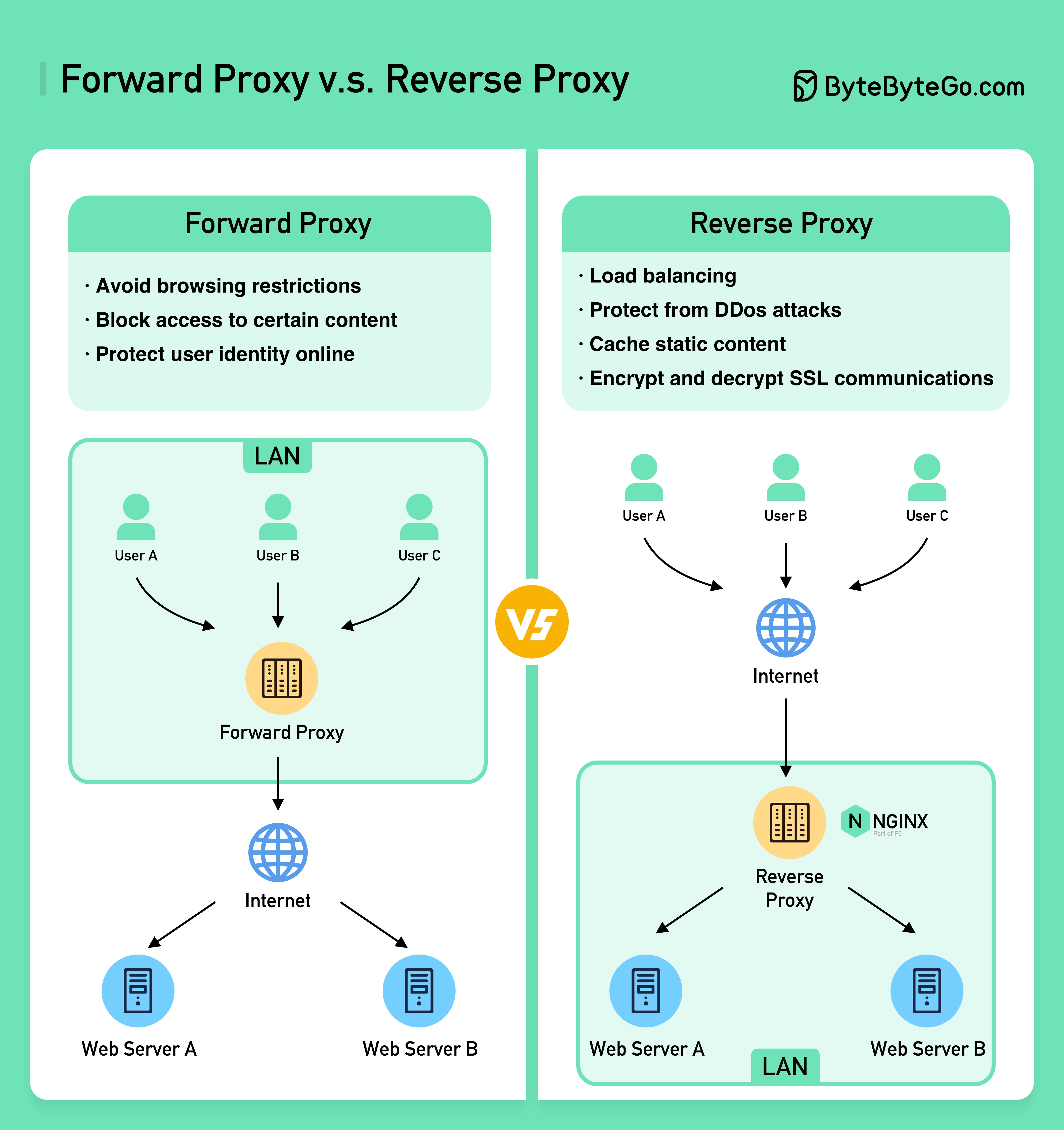
Un proxy de reenvío es un servidor que se encuentra entre los dispositivos de los usuarios e Internet.
Un proxy de reenvío se usa comúnmente para:
Un proxy inverso es un servidor que acepta una solicitud del cliente, reenvía la solicitud a los servidores web y devuelve los resultados al cliente como si el servidor proxy hubiera procesado la solicitud.
Un proxy inverso es bueno para:
El siguiente diagrama muestra 6 algoritmos comunes.
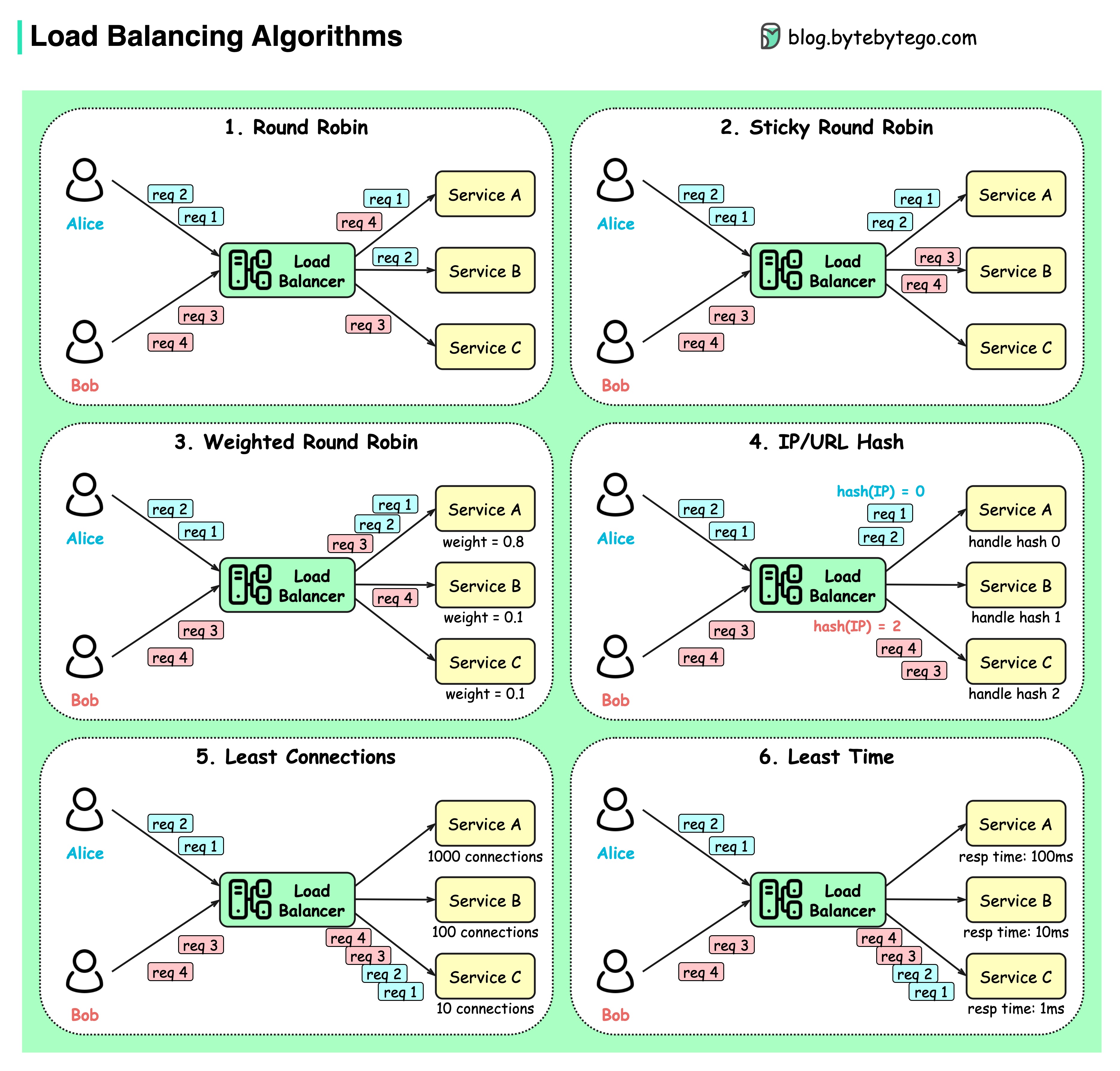
Todos contra todos
Las solicitudes de los clientes se envían a diferentes instancias de servicio en orden secuencial. Por lo general, se requiere que los servicios sean apátridas.
Round Robin pegajoso
Esta es una mejora del algoritmo round-robin. Si la primera solicitud de Alice va al servicio A, las siguientes solicitudes también van al servicio A.
Round-robin ponderado
El administrador puede especificar el peso de cada servicio. Los que tienen mayor peso manejan más solicitudes que otros.
Picadillo
Este algoritmo aplica una función hash en la IP o URL de las solicitudes entrantes. Las solicitudes se enrutan a instancias relevantes según el resultado de la función hash.
Menos conexiones
Se envía una nueva solicitud a la instancia de servicio con la menor cantidad de conexiones simultáneas.
Menor tiempo de respuesta
Se envía una nueva solicitud a la instancia de servicio con el tiempo de respuesta más rápido.
El siguiente diagrama muestra una comparación de URL, URI y URN.
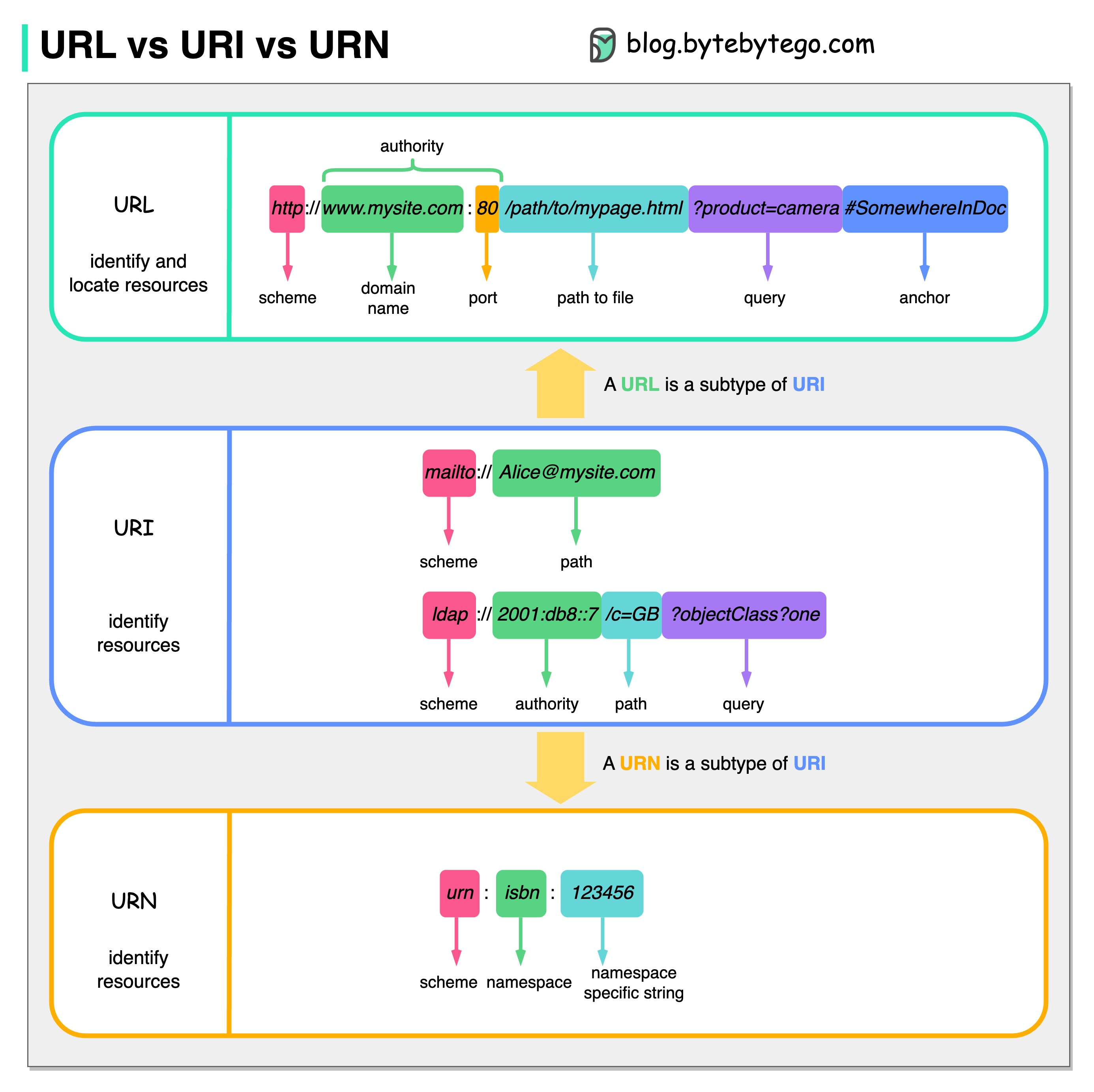
URI significa Identificador uniforme de recursos. Identifica un recurso lógico o físico en la web. URL y URN son subtipos de URI. La URL localiza un recurso, mientras que la URN nombra un recurso.
Un URI se compone de las siguientes partes: esquema:[//autoridad]ruta[?consulta][#fragmento]
URL significa Localizador uniforme de recursos, el concepto clave de HTTP. Es la dirección de un recurso único en la web. Se puede utilizar con otros protocolos como FTP y JDBC.
URN significa Nombre de recurso uniforme. Utiliza el esquema de la urna. Las URN no se pueden utilizar para localizar un recurso. Un ejemplo sencillo que se muestra en el diagrama se compone de un espacio de nombres y una cadena específica del espacio de nombres.
Si desea obtener más detalles sobre el tema, recomendaría la aclaración del W3C.
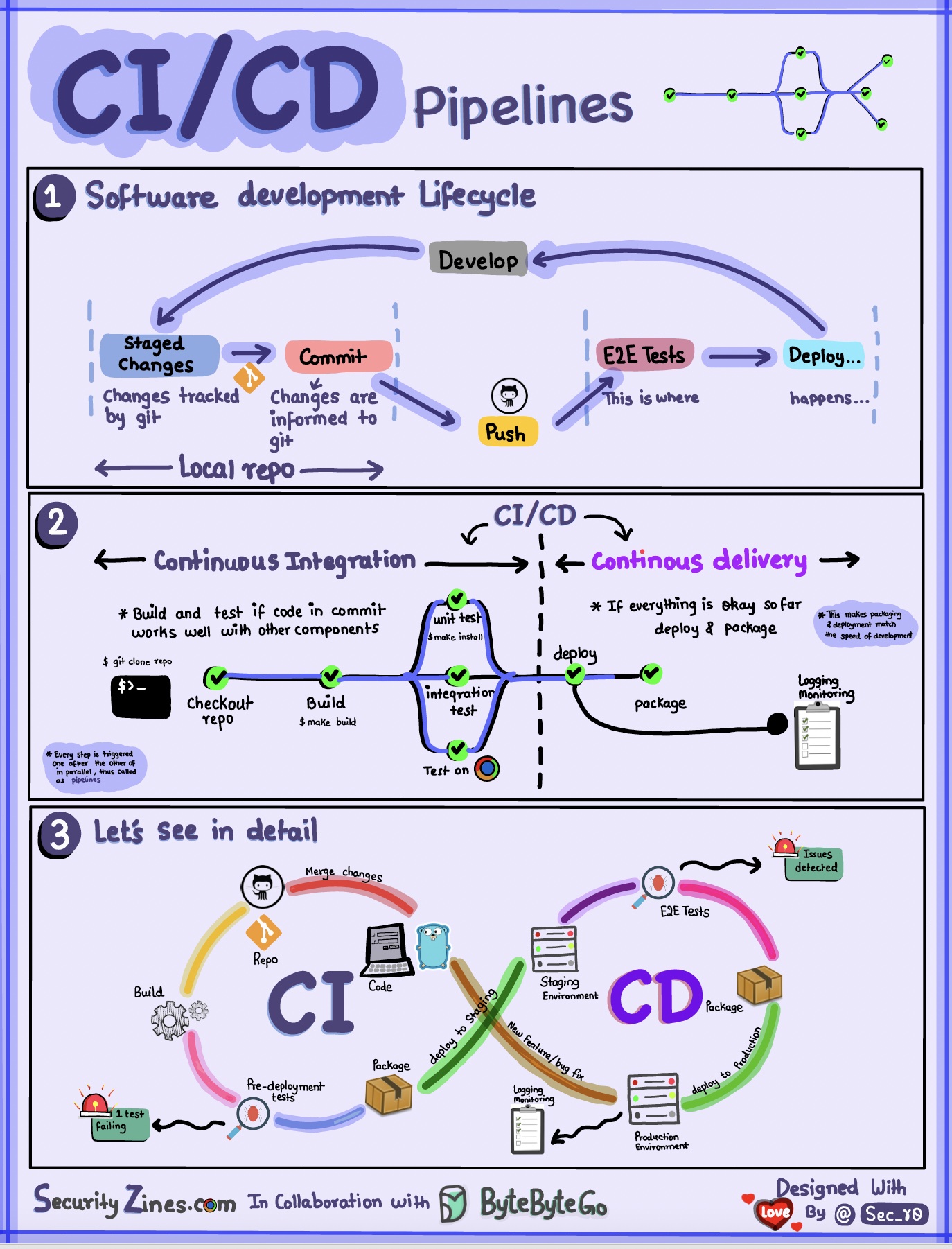
Sección 1: SDLC con CI/CD
El ciclo de vida del desarrollo de software (SDLC) consta de varias etapas clave: desarrollo, prueba, implementación y mantenimiento. CI/CD automatiza e integra estas etapas para permitir lanzamientos más rápidos y confiables.
Cuando el código se envía a un repositorio de git, se activa un proceso de compilación y prueba automatizado. Se ejecutan casos de prueba de un extremo a otro (e2e) para validar el código. Si las pruebas pasan, el código se puede implementar automáticamente en etapa de preparación/producción. Si se encuentran problemas, el código se devuelve al desarrollo para corregirlos. Esta automatización proporciona retroalimentación rápida a los desarrolladores y reduce el riesgo de errores en producción.
Sección 2 - Diferencia entre CI y CD
La integración continua (CI) automatiza el proceso de creación, prueba y fusión. Ejecuta pruebas cada vez que se confirma código para detectar problemas de integración de manera temprana. Esto fomenta las confirmaciones frecuentes de código y la retroalimentación rápida.
La entrega continua (CD) automatiza los procesos de lanzamiento, como los cambios de infraestructura y la implementación. Garantiza que el software pueda publicarse de forma fiable en cualquier momento a través de flujos de trabajo automatizados. CD también puede automatizar los pasos de prueba y aprobación manuales necesarios antes de la implementación en producción.
Sección 3: Canalización de CI/CD
Una canalización de CI/CD típica tiene varias etapas conectadas:
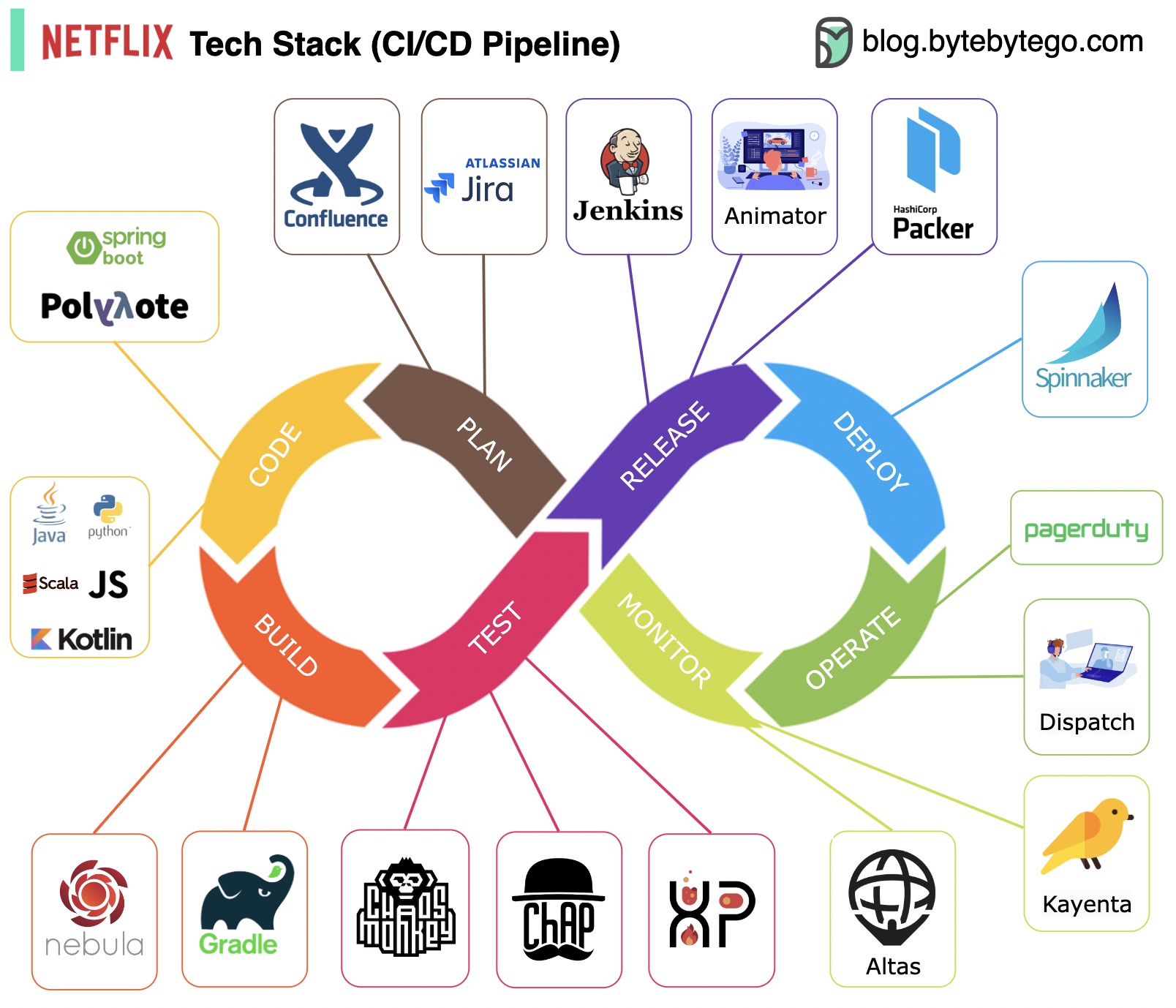
Planificación: Netflix Engineering utiliza JIRA para la planificación y Confluence para la documentación.
Codificación: Java es el lenguaje de programación principal para el servicio backend, mientras que otros lenguajes se utilizan para diferentes casos de uso.
Compilación: Gradle se usa principalmente para la construcción y los complementos de Gradle están diseñados para admitir varios casos de uso.
Empaquetado: el paquete y las dependencias se empaquetan en una imagen de máquina de Amazon (AMI) para su lanzamiento.
Pruebas: Las pruebas enfatizan el enfoque de la cultura de producción en la creación de herramientas del caos.
Implementación: Netflix utiliza su Spinnaker de construcción propia para la implementación de Canary.
Monitoreo: Las métricas de monitoreo están centralizadas en Atlas y Kayenta se utiliza para detectar anomalías.
Informe de incidentes: los incidentes se envían según la prioridad y PagerDuty se utiliza para el manejo de incidentes.
Estos patrones de arquitectura se encuentran entre los más utilizados en el desarrollo de aplicaciones, ya sea en plataformas iOS o Android. Los desarrolladores los han introducido para superar las limitaciones de patrones anteriores. Entonces, ¿en qué se diferencian?
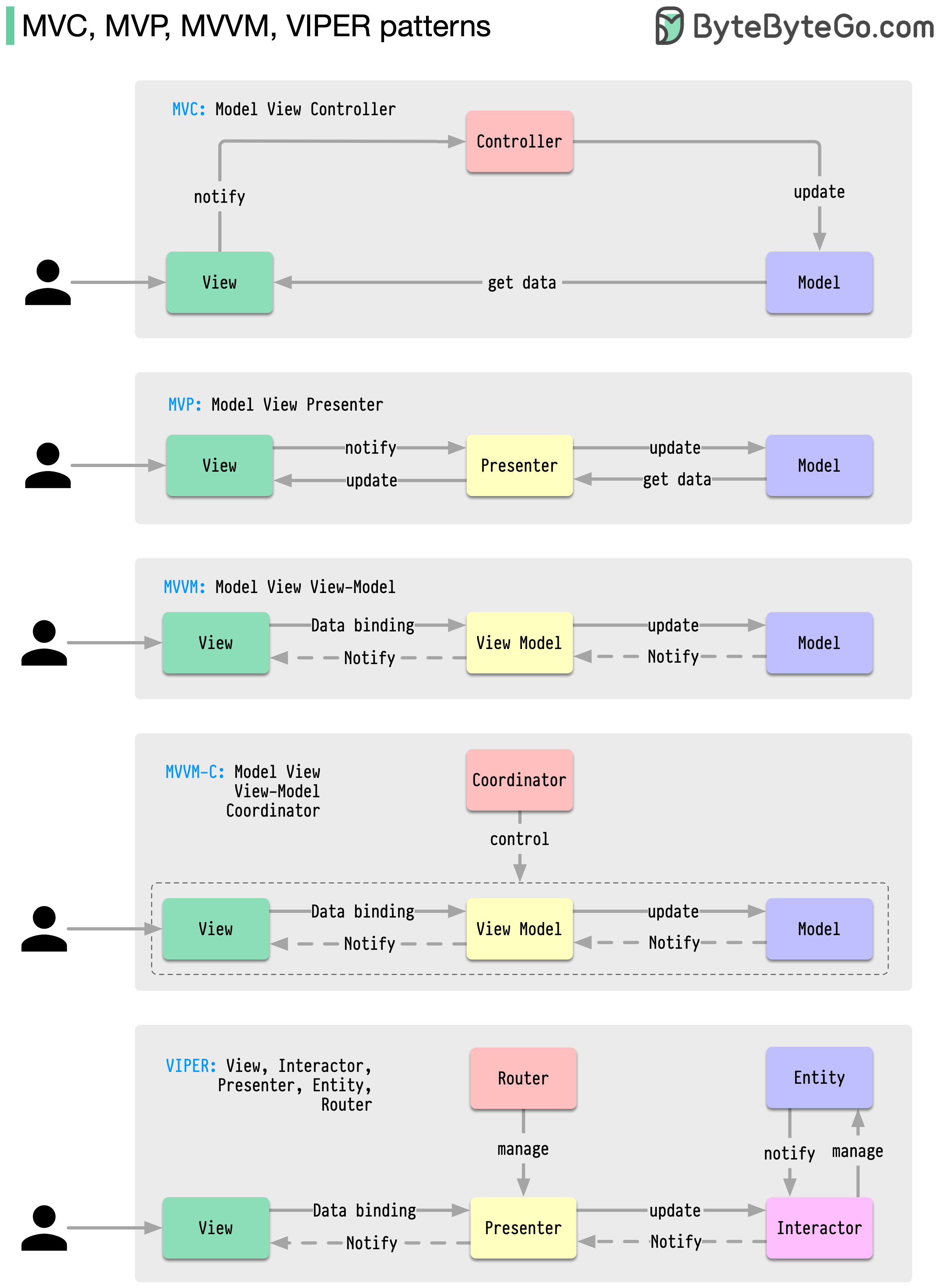
Los patrones son soluciones reutilizables a problemas de diseño comunes, lo que da como resultado un proceso de desarrollo más fluido y eficiente. Sirven como modelo para construir mejores estructuras de software. Estos son algunos de los patrones más populares:

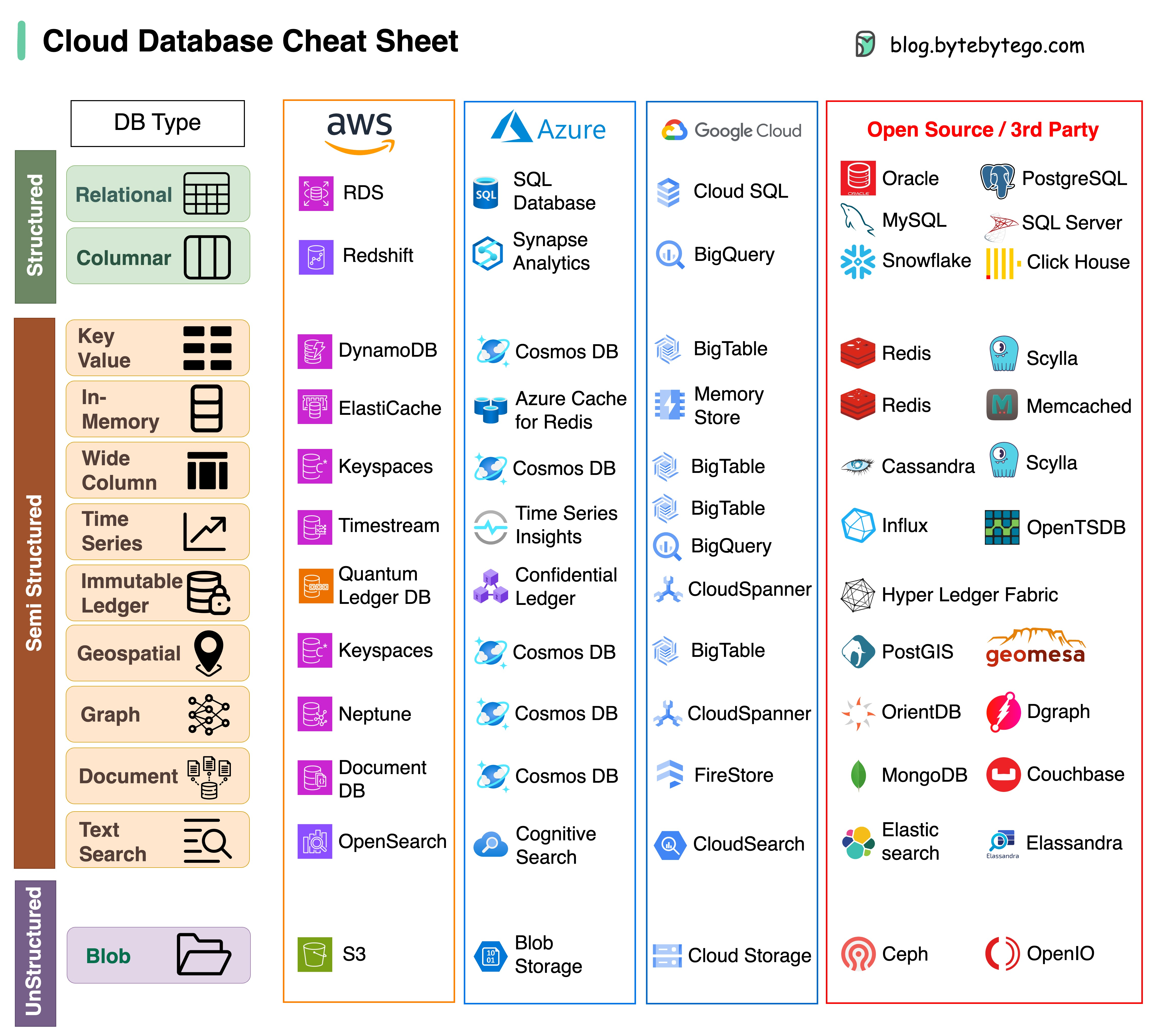
Elegir la base de datos adecuada para su proyecto es una tarea compleja. Muchas opciones de bases de datos, cada una de ellas adaptada a distintos casos de uso, pueden generar rápidamente fatiga en la toma de decisiones.
Esperamos que esta hoja de referencia proporcione orientación de alto nivel para identificar el servicio adecuado que se alinee con las necesidades de su proyecto y evitar posibles obstáculos.
Nota: Google tiene documentación limitada para sus casos de uso de bases de datos. Aunque hicimos todo lo posible para ver lo que estaba disponible y llegamos a la mejor opción, es posible que algunas de las entradas deban ser más precisas.
La respuesta variará según su caso de uso. Los datos se pueden indexar en la memoria o en el disco. De manera similar, los formatos de datos varían, como números, cadenas, coordenadas geográficas, etc. El sistema puede requerir mucha escritura o lectura. Todos estos factores afectan la elección del formato de índice de la base de datos.
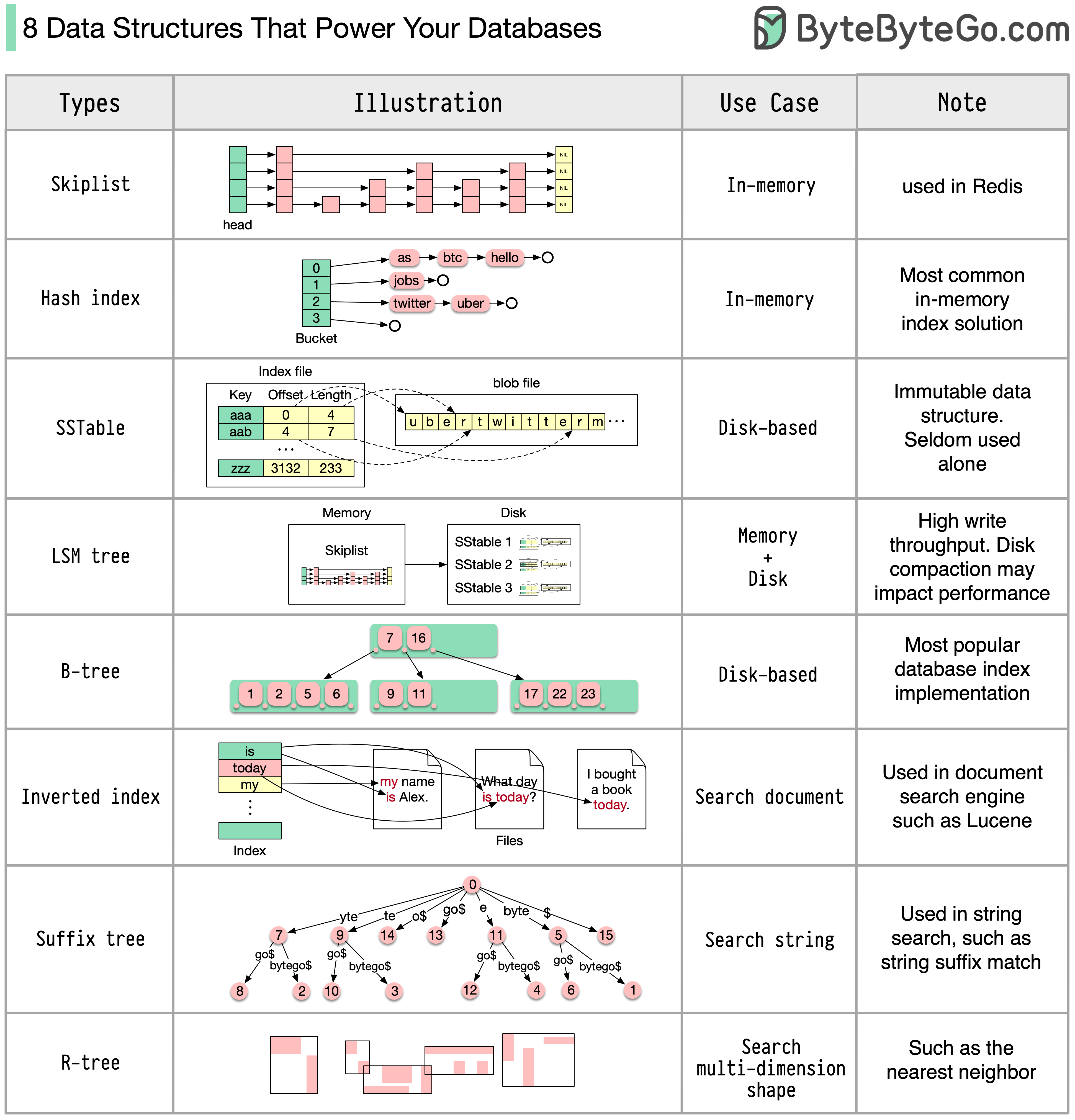
Las siguientes son algunas de las estructuras de datos más populares utilizadas para indexar datos:
El siguiente diagrama muestra el proceso. Tenga en cuenta que las arquitecturas para diferentes bases de datos son diferentes; el diagrama muestra algunos diseños comunes.
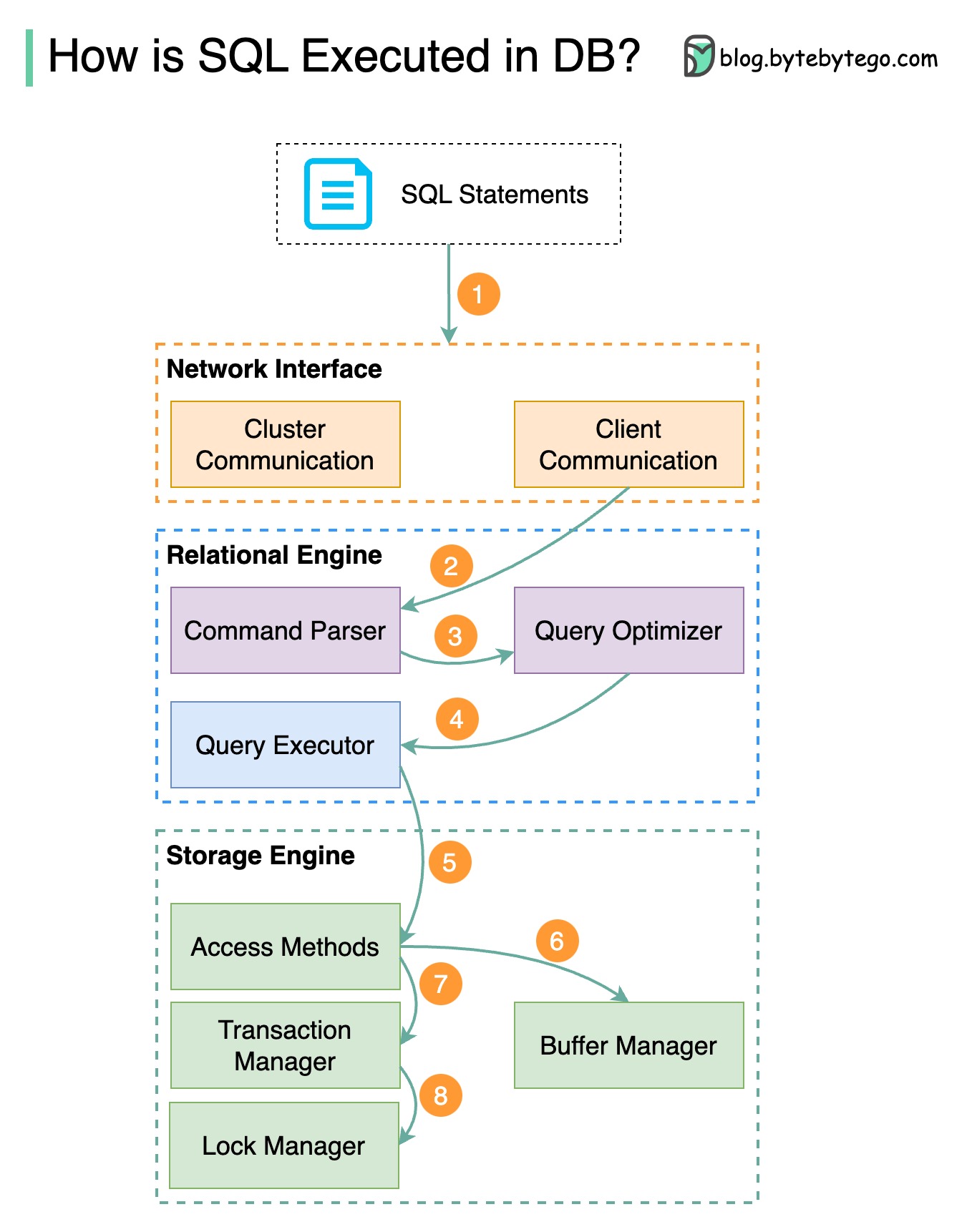
Paso 1: se envía una declaración SQL a la base de datos a través de un protocolo de capa de transporte (por ejemplo, TCP).
Paso 2: la declaración SQL se envía al analizador de comandos, donde pasa por un análisis sintáctico y semántico, y luego se genera un árbol de consultas.
Paso 3: el árbol de consultas se envía al optimizador. El optimizador crea un plan de ejecución.
Paso 4: el plan de ejecución se envía al ejecutor. El ejecutor recupera datos de la ejecución.
Paso 5: los métodos de acceso proporcionan la lógica de recuperación de datos necesaria para la ejecución, recuperando datos del motor de almacenamiento.
Paso 6: los métodos de acceso deciden si la declaración SQL es de solo lectura. Si la consulta es de solo lectura (sentencia SELECT), se pasa al administrador del búfer para su posterior procesamiento. El administrador de búfer busca los datos en el caché o en los archivos de datos.
Paso 7: si la declaración es una ACTUALIZACIÓN o una INSERCIÓN, se pasa al administrador de transacciones para su posterior procesamiento.
Paso 8: durante una transacción, los datos están en modo de bloqueo. Esto lo garantiza el administrador de cerraduras. También garantiza las propiedades ACID de la transacción.
El teorema CAP es uno de los términos más famosos en informática, pero apuesto a que diferentes desarrolladores tienen diferentes interpretaciones. Examinemos qué es y por qué puede resultar confuso.
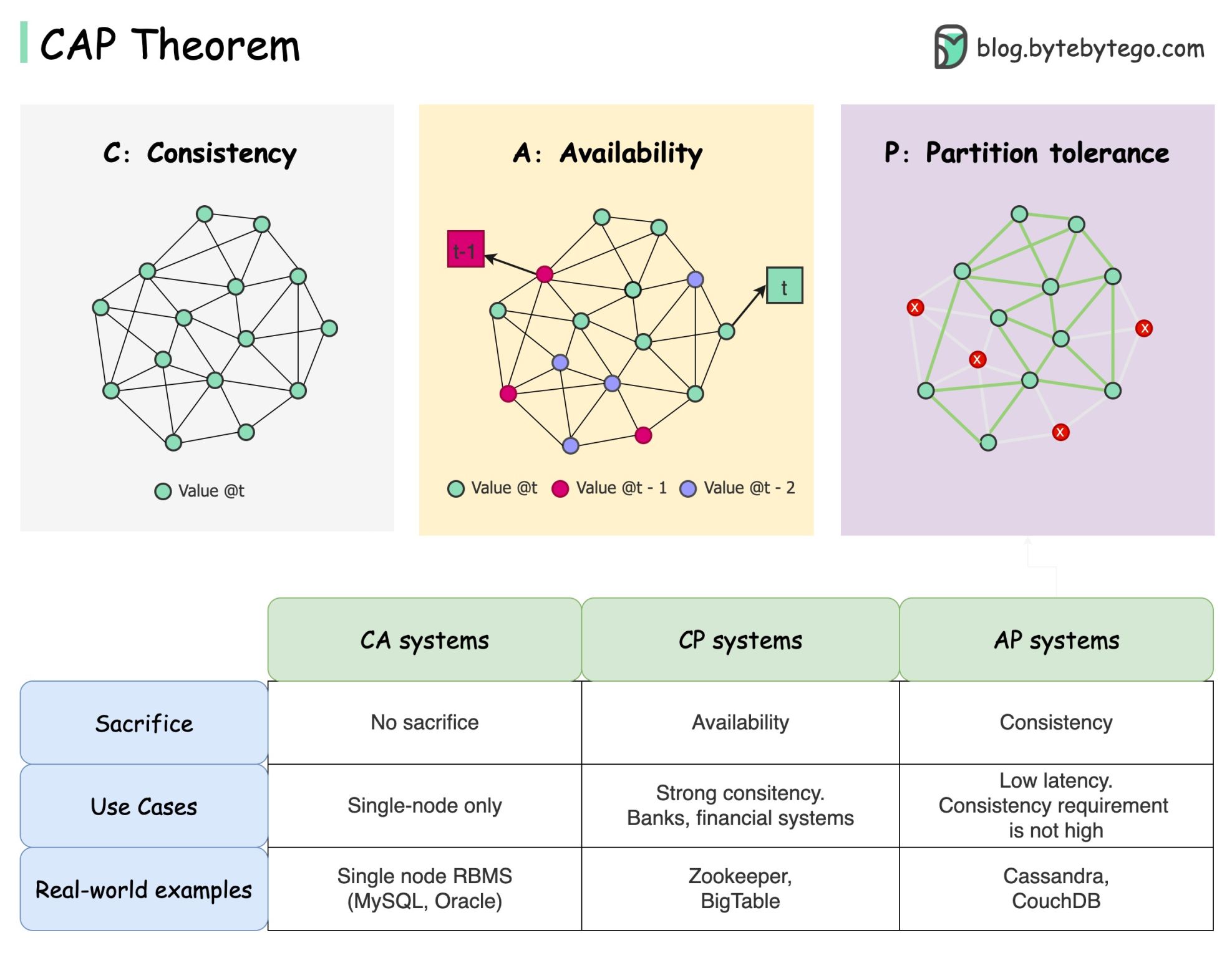
El teorema CAP establece que un sistema distribuido no puede proporcionar más de dos de estas tres garantías simultáneamente.
Coherencia : coherencia significa que todos los clientes ven los mismos datos al mismo tiempo sin importar a qué nodo se conecten.
Disponibilidad : disponibilidad significa que cualquier cliente que solicite datos obtiene una respuesta incluso si algunos de los nodos están inactivos.
Tolerancia de partición : una partición indica una interrupción de la comunicación entre dos nodos. La tolerancia a la partición significa que el sistema continúa funcionando a pesar de las particiones de la red.
La formulación “2 de 3” puede resultar útil, pero esta simplificación podría inducir a error .
Elegir una base de datos no es fácil. No basta con justificar nuestra elección basándonos únicamente en el teorema CAP. Por ejemplo, las empresas no eligen Cassandra para aplicaciones de chat simplemente porque es un sistema AP. Hay una lista de buenas características que hacen de Cassandra una opción deseable para almacenar mensajes de chat. Necesitamos profundizar más.
“La CAP prohíbe sólo una pequeña parte del espacio de diseño: perfecta disponibilidad y coherencia en la presencia de particiones, que son raras”. Citado del artículo: CAP doce años después: cómo han cambiado las “reglas”.
El teorema trata sobre el 100% de disponibilidad y coherencia. Una discusión más realista sería la de las compensaciones entre latencia y coherencia cuando no hay partición de red. Consulte el teorema de PACELC para obtener más detalles.
¿Es realmente útil el teorema CAP?
Creo que sigue siendo útil porque abre nuestras mentes a una serie de debates sobre compensaciones, pero es sólo una parte de la historia. Necesitamos profundizar más a la hora de elegir la base de datos adecuada.
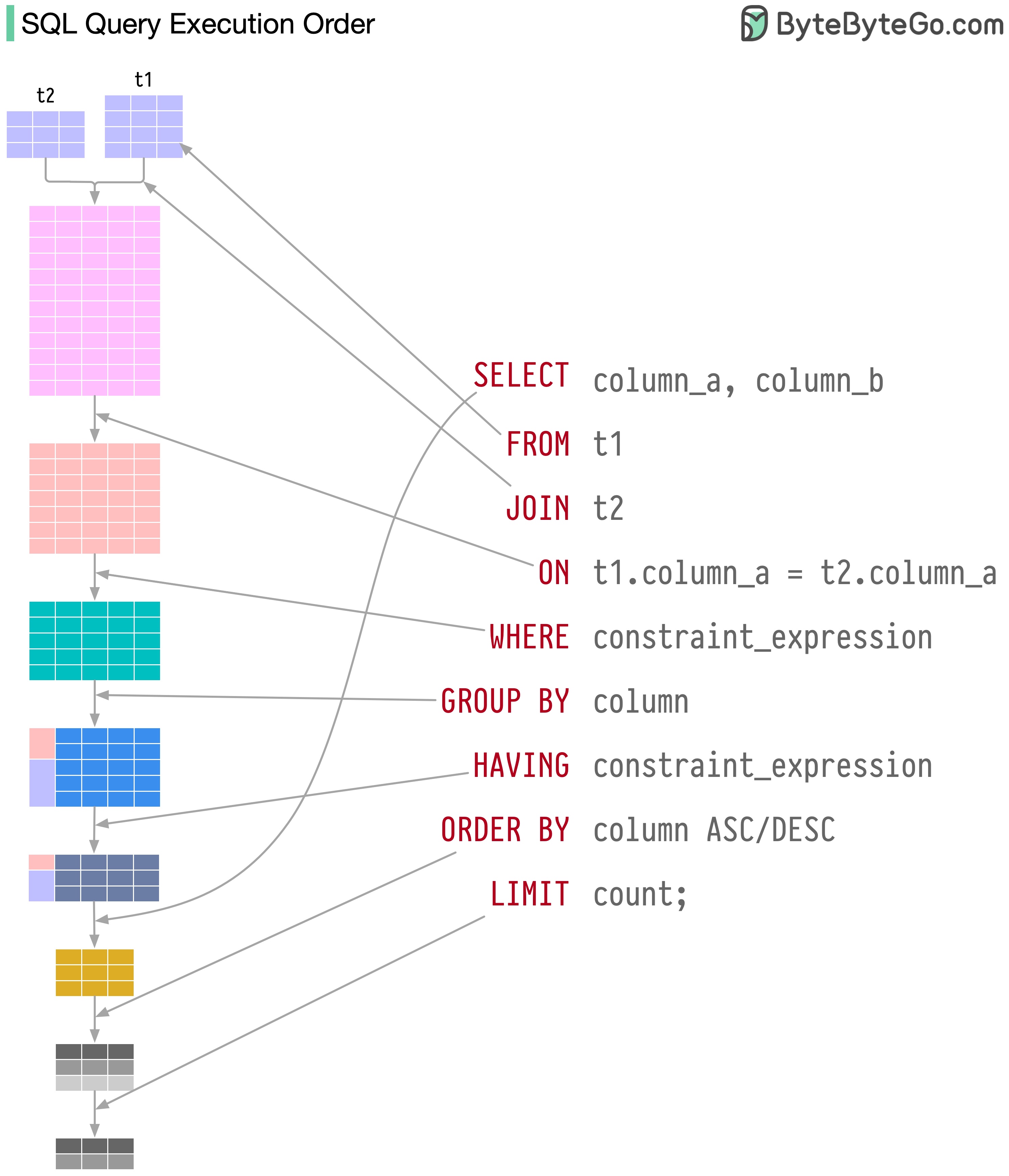
El sistema de base de datos ejecuta las declaraciones SQL en varios pasos, que incluyen:
La ejecución de SQL es altamente compleja e involucra muchas consideraciones, tales como:
En 1986, SQL (lenguaje de consulta estructurado) se convirtió en un estándar. Durante los siguientes 40 años, se convirtió en el lenguaje dominante para los sistemas de gestión de bases de datos relacionales. Leer el último estándar (ANSI SQL 2016) puede llevar mucho tiempo. ¿Cómo puedo aprenderlo?
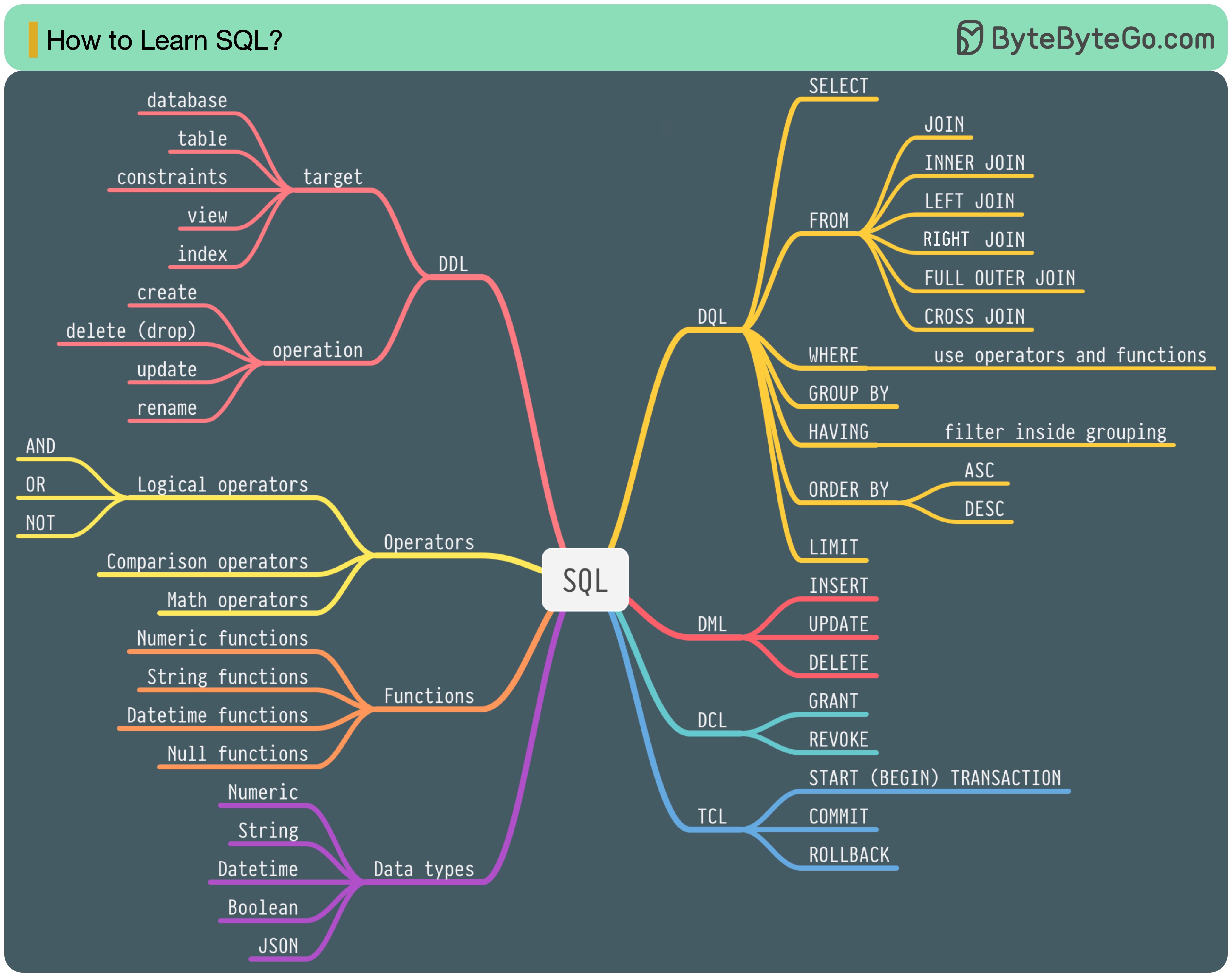
Hay 5 componentes del lenguaje SQL:
Para un ingeniero de backend, es posible que necesite saber la mayor parte. Como analista de datos, es posible que necesite tener un buen conocimiento de DQL. Seleccione los temas que sean más relevantes para usted.
Este diagrama ilustra dónde almacenamos en caché los datos en una arquitectura típica.
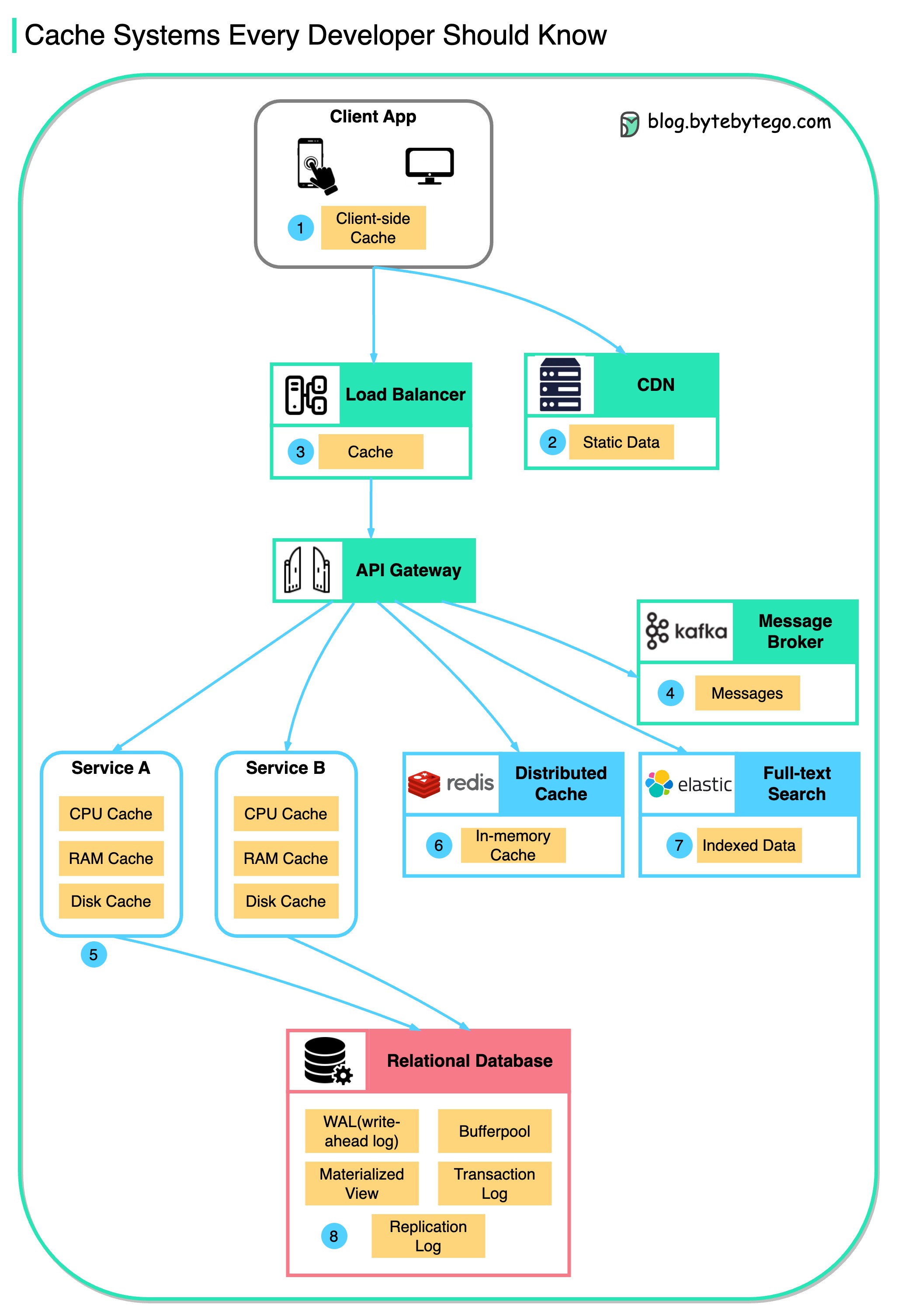
Hay múltiples capas a lo largo del flujo.
Hay 3 razones principales, como se muestra en el siguiente diagrama.
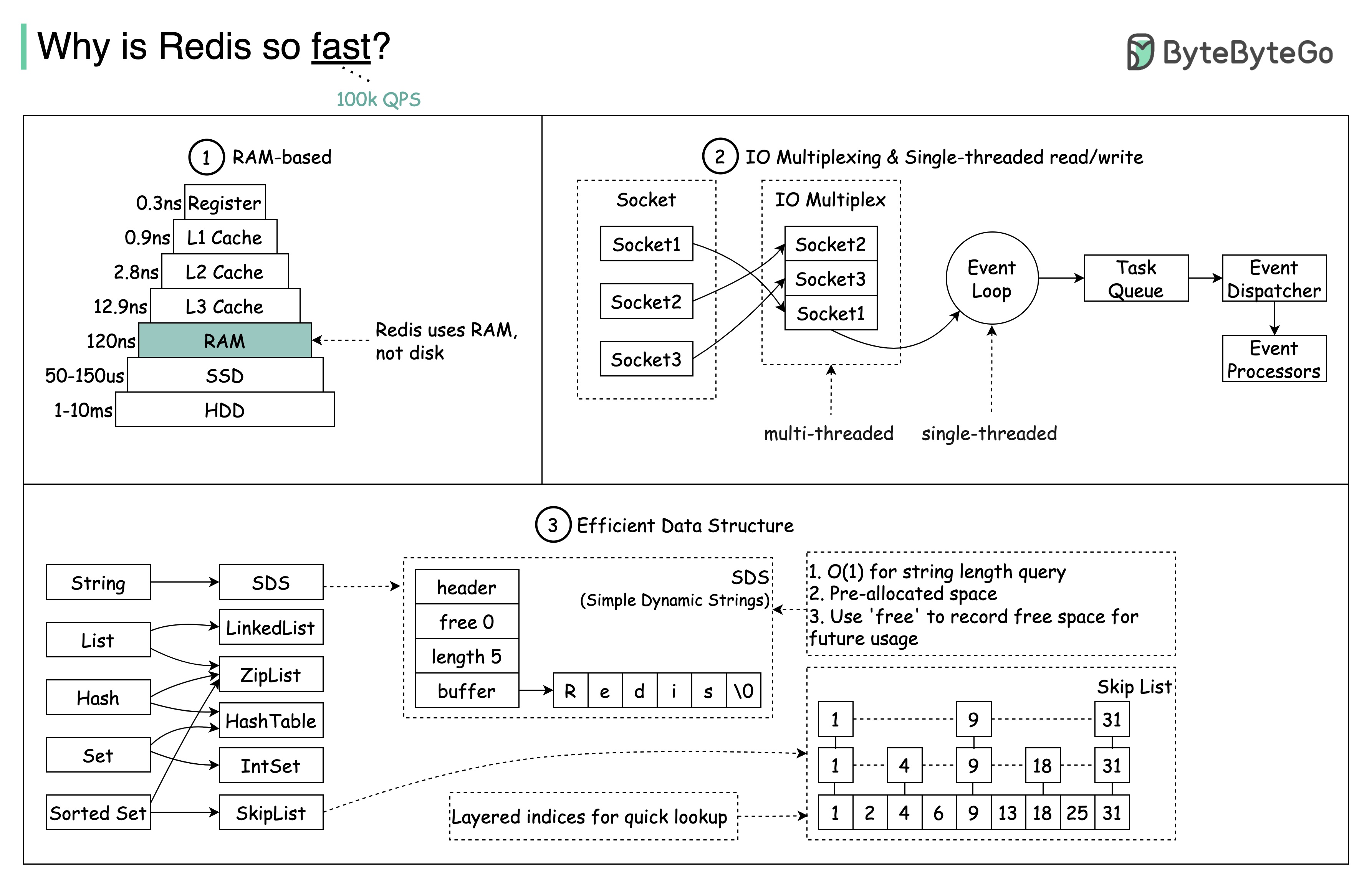
Pregunta: Otro almacén en memoria popular es Memcached. ¿Conoces las diferencias entre Redis y Memcached?
Es posible que hayas notado que el estilo de este diagrama es diferente al de mis publicaciones anteriores. Por favor déjame saber cuál prefieres.
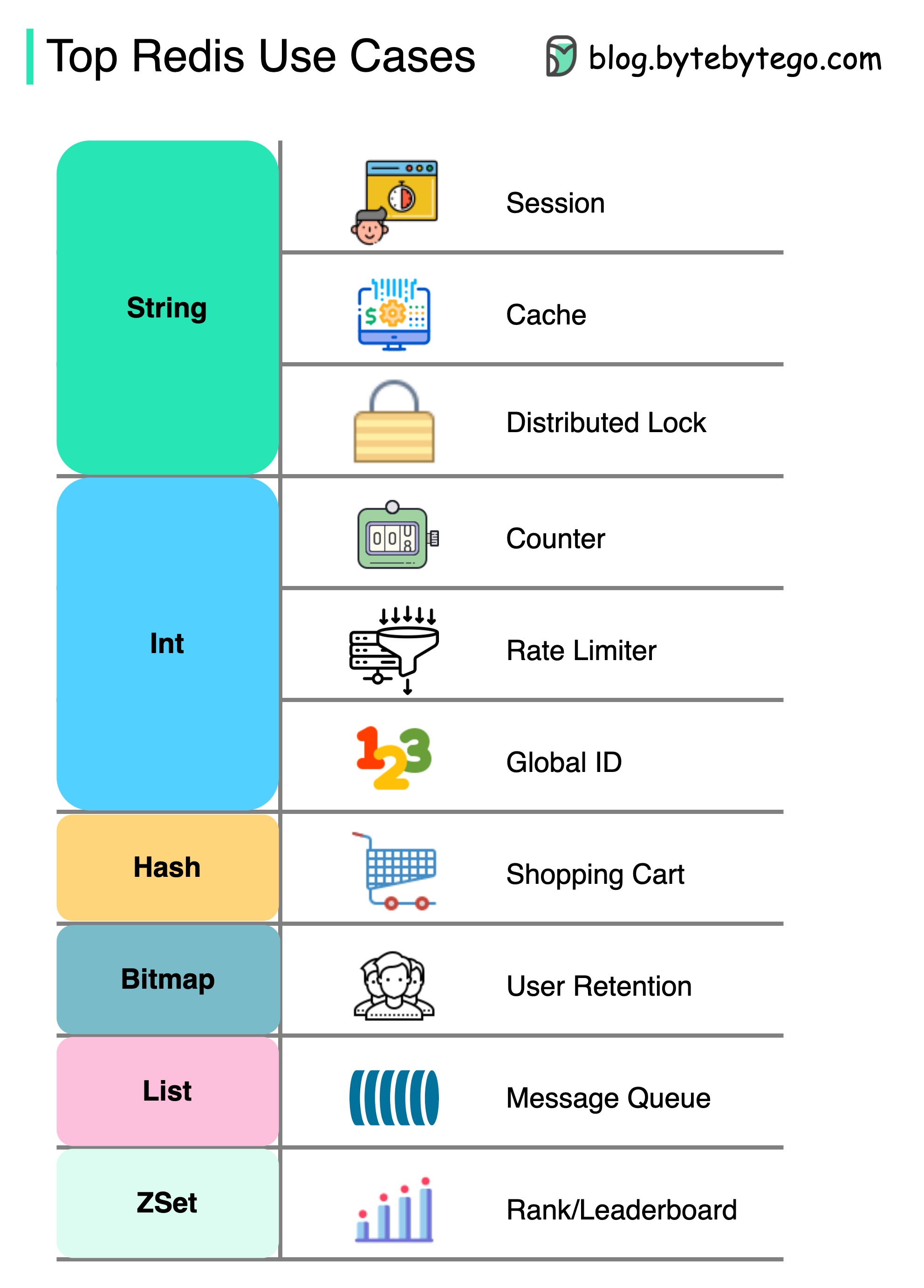
Redis es más que solo el almacenamiento en caché.
Redis se puede utilizar en una variedad de escenarios como se muestra en el diagrama.
Sesión
Podemos usar Redis para compartir datos de la sesión del usuario entre diferentes servicios.
Cache
Podemos usar Redis para almacenar en caché objetos o páginas, especialmente para datos de puntos de acceso.
Cerradura distribuida
Podemos usar una cadena Redis para adquirir cerraduras entre los servicios distribuidos.
Encimera
Podemos contar cuántos me gusta o cuántas lecturas para artículos.
Limitador de tasas
Podemos aplicar un limitador de velocidad para ciertos IPS de usuario.
Generador de identificación global
Podemos usar Redis Int para ID Global.
Carro de la compra
Podemos usar Redis Hash para representar pares de valores clave en un carrito de compras.
Calcular la retención de usuarios
Podemos usar Bitmap para representar al usuario inicio de sesión diariamente y calcular la retención del usuario.
Cola de mensajes
Podemos usar la lista para una cola de mensajes.
Categoría
Podemos usar ZSET para ordenar los artículos.
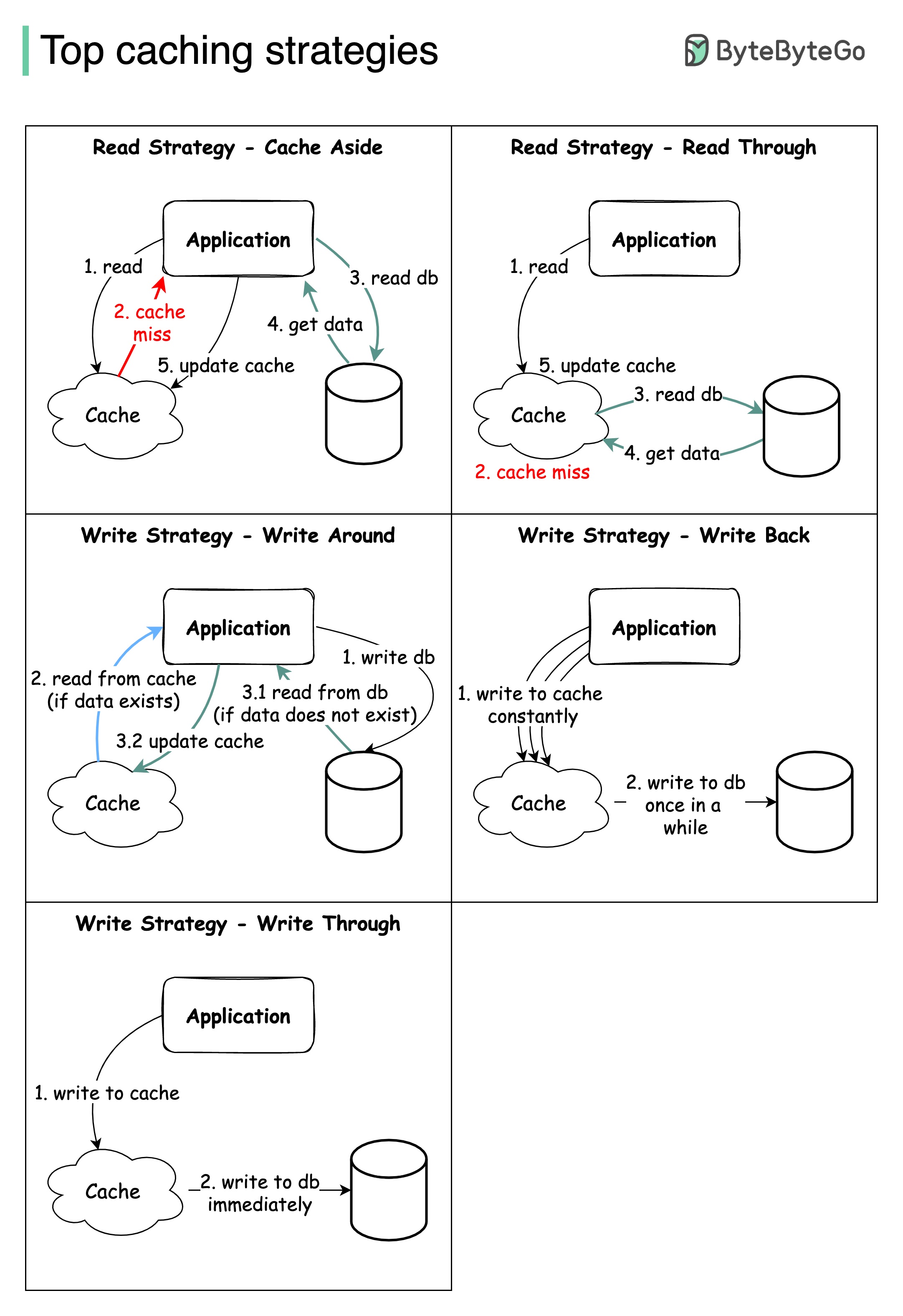
El diseño de sistemas a gran escala generalmente requiere una consideración cuidadosa del almacenamiento en caché. A continuación hay cinco estrategias de almacenamiento en caché que se utilizan con frecuencia.
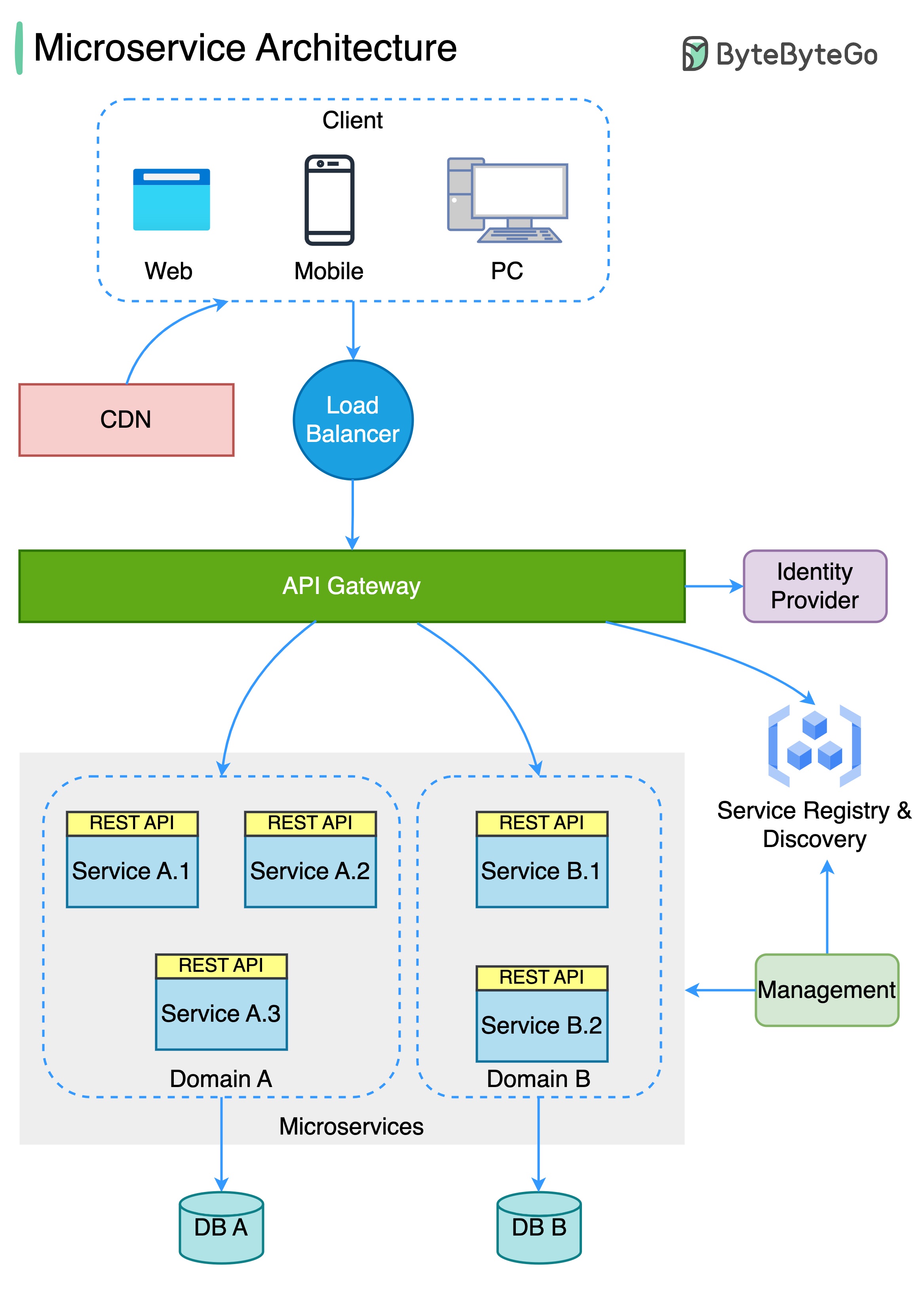
El siguiente diagrama muestra una arquitectura de microservicio típica.
Beneficios de los microservicios:
Una imagen vale más que mil palabras: 9 mejores prácticas para desarrollar microservicios.
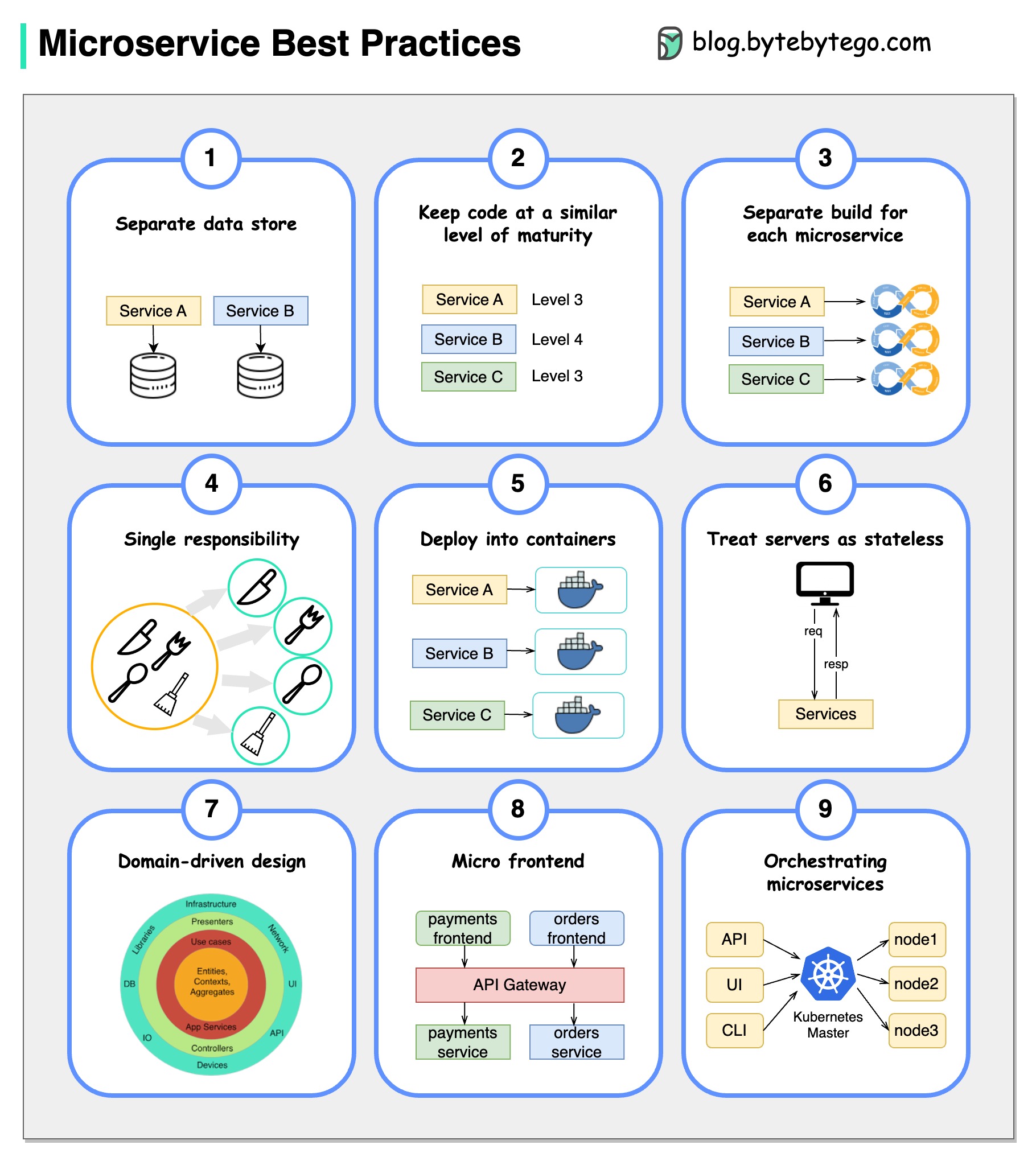
Cuando desarrollamos microservicios, necesitamos seguir las siguientes mejores prácticas:
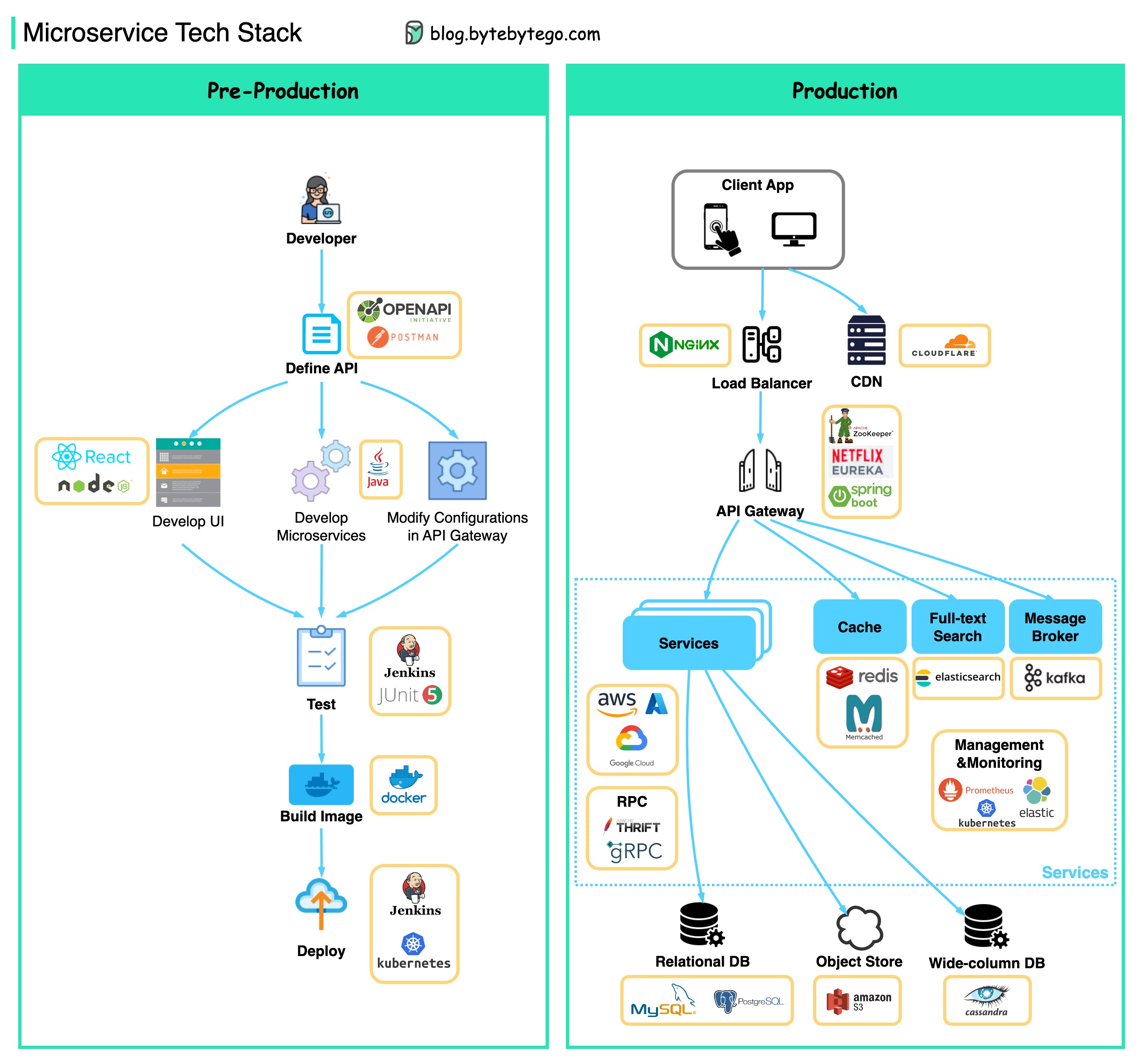
A continuación encontrará un diagrama que muestra la pila de tecnología de microservicio, tanto para la fase de desarrollo como para la producción.
Hay muchas decisiones de diseño que contribuyeron al rendimiento de Kafka. En esta publicación, nos centraremos en dos. Creemos que estos dos tenían el mayor peso.
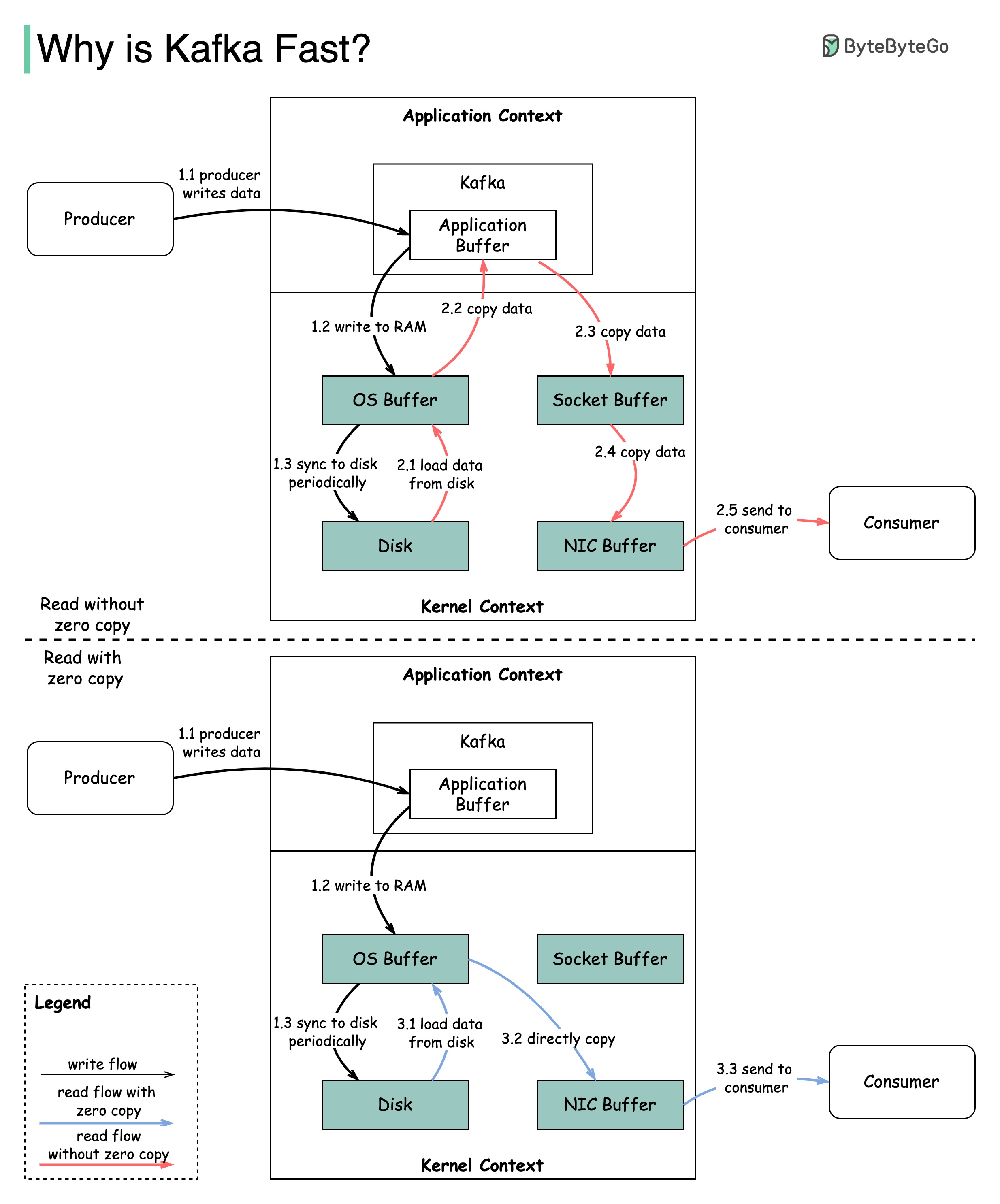
El diagrama ilustra cómo se transmiten los datos entre el productor y el consumidor, y qué significa cero copias.
2.1 Los datos se cargan del disco al caché del sistema operativo
2.2 Los datos se copian de OS Cache a la aplicación Kafka
2.3 La aplicación Kafka copia los datos en el búfer de socket
2.4 Los datos se copian de Socket Buffer a la tarjeta de red
2.5 La tarjeta de red envía datos al consumidor
3.1: Los datos se cargan desde el disco al OS Cache 3.2 El caché del sistema operativo copia directamente los datos a la tarjeta de red a través del comando sendFile () 3.3 La tarjeta de red envía datos al consumidor
Zero Copy es un atajo para guardar las múltiples copias de datos entre el contexto de la aplicación y el contexto del núcleo.
El siguiente diagrama muestra la economía del flujo de pago de la tarjeta de crédito.
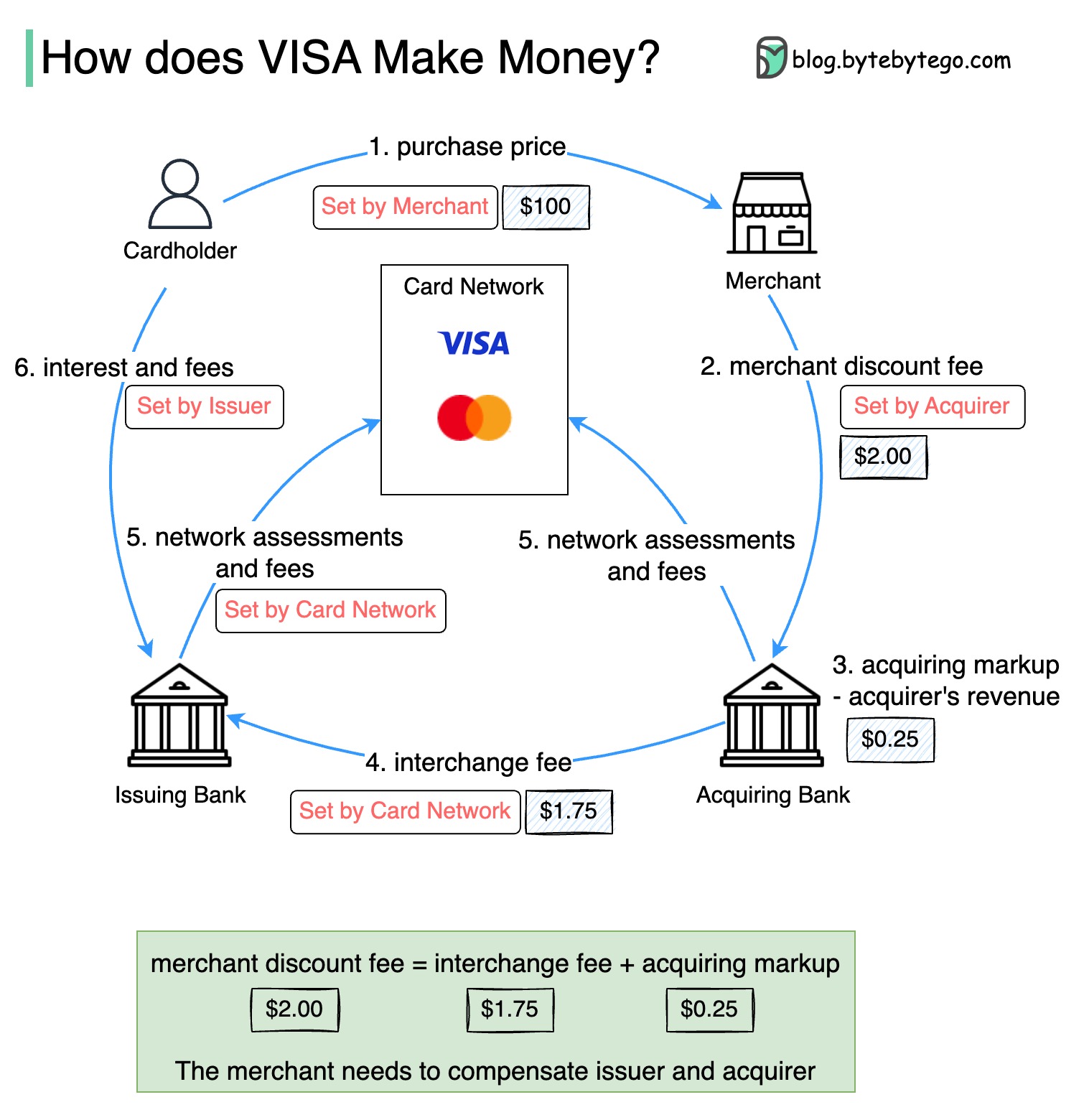
1. El titular de la tarjeta paga a un comerciante $ 100 para comprar un producto.
2. El comerciante se beneficia del uso de la tarjeta de crédito con un mayor volumen de ventas y necesita compensar al emisor y a la red de tarjetas para proporcionar el servicio de pago. El banco adquirente establece una tarifa con el comerciante, llamado "tarifa de descuento comercial".
3 - 4. El banco adquirente mantiene $ 0.25 como el marcado adquirente, y $ 1.75 se paga al banco emisor como la tarifa de intercambio. La tarifa de descuento comercial debe cubrir la tarifa de intercambio.
La tarifa de intercambio es establecida por la red de tarjetas porque es menos eficiente para cada banco emisor negociar tarifas con cada comerciante.
5. La red de tarjetas establece las evaluaciones y tarifas de la red con cada banco, que paga la red de tarjetas por sus servicios cada mes. Por ejemplo, Visa cobra una evaluación del 0.11%, más una tarifa de uso de $ 0.0195, por cada deslizamiento.
6. El titular de la tarjeta paga al banco emisor por sus servicios.
¿Por qué debería compensarse el banco emisor?
Visa, MasterCard y American Express actúan como redes de tarjetas para la compensación y el asentamiento de fondos. La tarjeta que adquiere el banco y el banco emisor de la tarjeta pueden ser, y a menudo, son diferentes. Si los bancos liquidaran las transacciones una por una sin un intermediario, cada banco tendría que liquidar las transacciones con todos los demás bancos. Esto es bastante ineficiente.
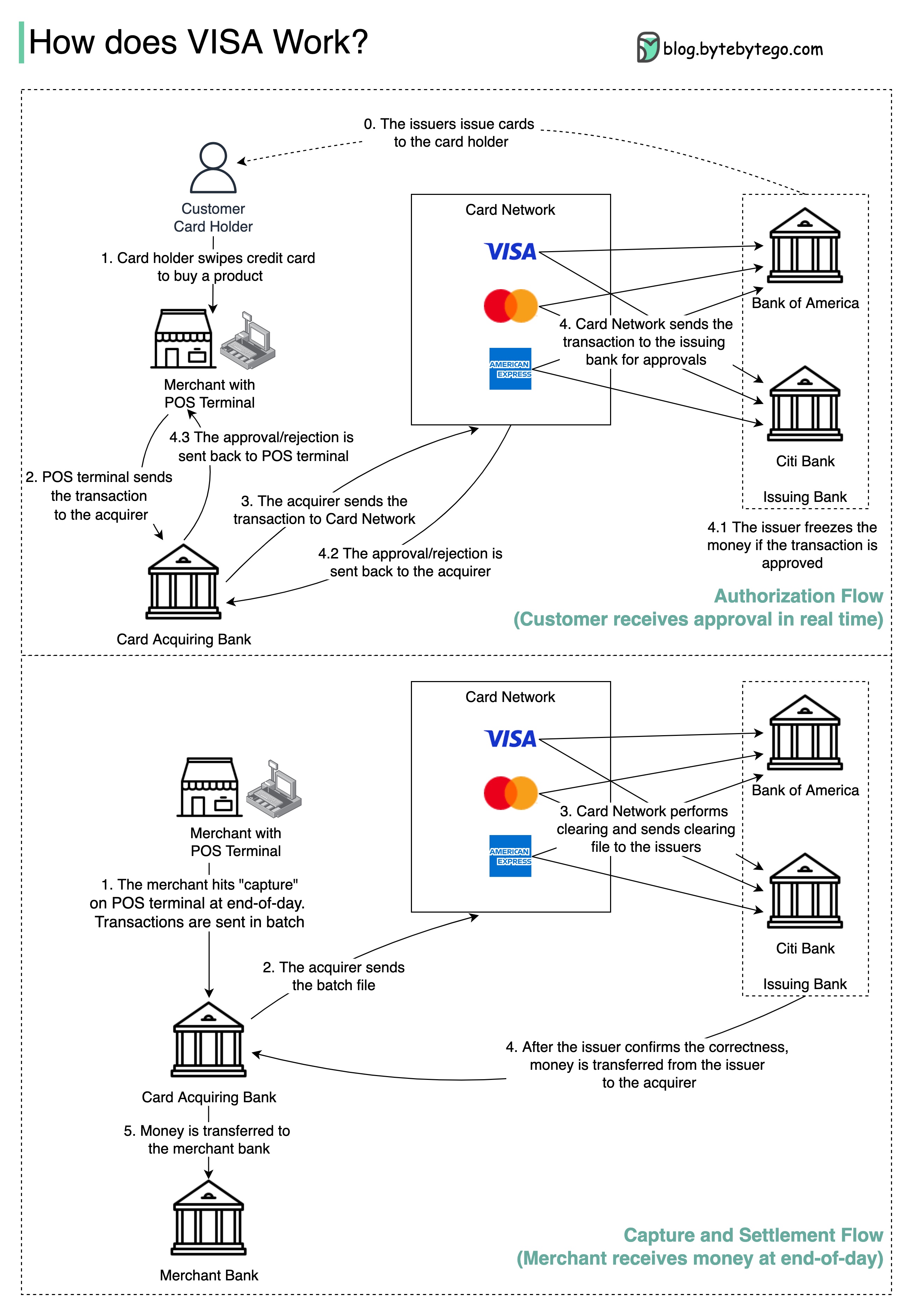
El siguiente diagrama muestra el papel de Visa en el proceso de pago de la tarjeta de crédito. Hay dos flujos involucrados. El flujo de autorización ocurre cuando el cliente desliza la tarjeta de crédito. El flujo de captura y liquidación ocurre cuando el comerciante quiere obtener el dinero al final del día.
Paso 0: La tarjeta que emite bancos emite tarjetas de crédito a sus clientes.
Paso 1: El titular de la tarjeta quiere comprar un producto y desliza la tarjeta de crédito en la terminal Point of Sale (POS) en la tienda del comerciante.
Paso 2: El terminal POS envía la transacción al banco adquirente, que ha proporcionado el terminal POS.
Pasos 3 y 4: El banco adquirente envía la transacción a la red de tarjetas, también llamada esquema de tarjeta. La red de tarjetas envía la transacción al banco emisor para su aprobación.
Pasos 4.1, 4.2 y 4.3: El banco emisor congela el dinero si se aprueba la transacción. La aprobación o rechazo se devuelve al adquirente, así como al terminal POS.
Pasos 1 y 2: El comerciante quiere recoger el dinero al final del día, por lo que golpean "capturar" en la terminal POS. Las transacciones se envían al adquirente en lote. El adquirente envía el archivo por lotes con transacciones a la red de tarjetas.
Paso 3: La red de tarjetas realiza la eliminación de las transacciones recopiladas de diferentes compradores y envía los archivos de compensación a diferentes bancos emisores.
Paso 4: Los bancos emisores confirman la exactitud de los archivos de compensación y transfieren dinero a los bancos adquirentes correspondientes.
Paso 5: El banco adquirente luego transfiere dinero al banco del comerciante.
Paso 4: La red de tarjetas borra las transacciones de diferentes bancos adquirentes. La compensación es un proceso en el que se anotan las transacciones de compensación mutua, por lo que se reduce el número de transacciones totales.
En el proceso, la red de tarjetas asume la carga de hablar con cada banco y recibe tarifas de servicio a cambio.
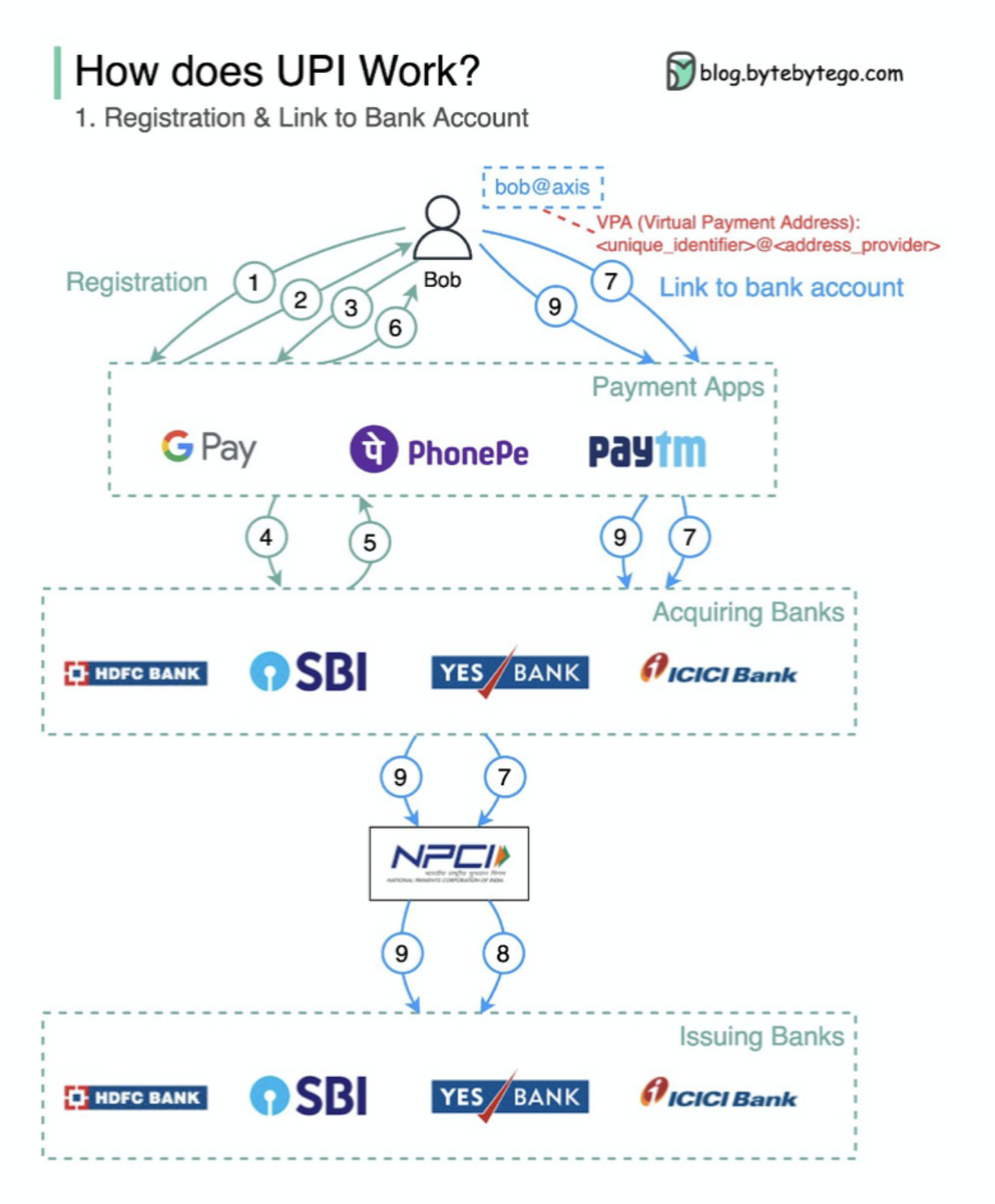
¿Qué es UPI? UPI es un sistema de pago instantáneo en tiempo real desarrollado por la National Payments Corporation of India.
Representa el 60% de las transacciones minoristas digitales en India hoy.
UPI = lenguaje de marcado de pago + estándar para pagos interoperables
Los conceptos de Ingeniería DevOps, SRE e Plataforma han surgido en diferentes momentos y han sido desarrollados por varias personas y organizaciones.
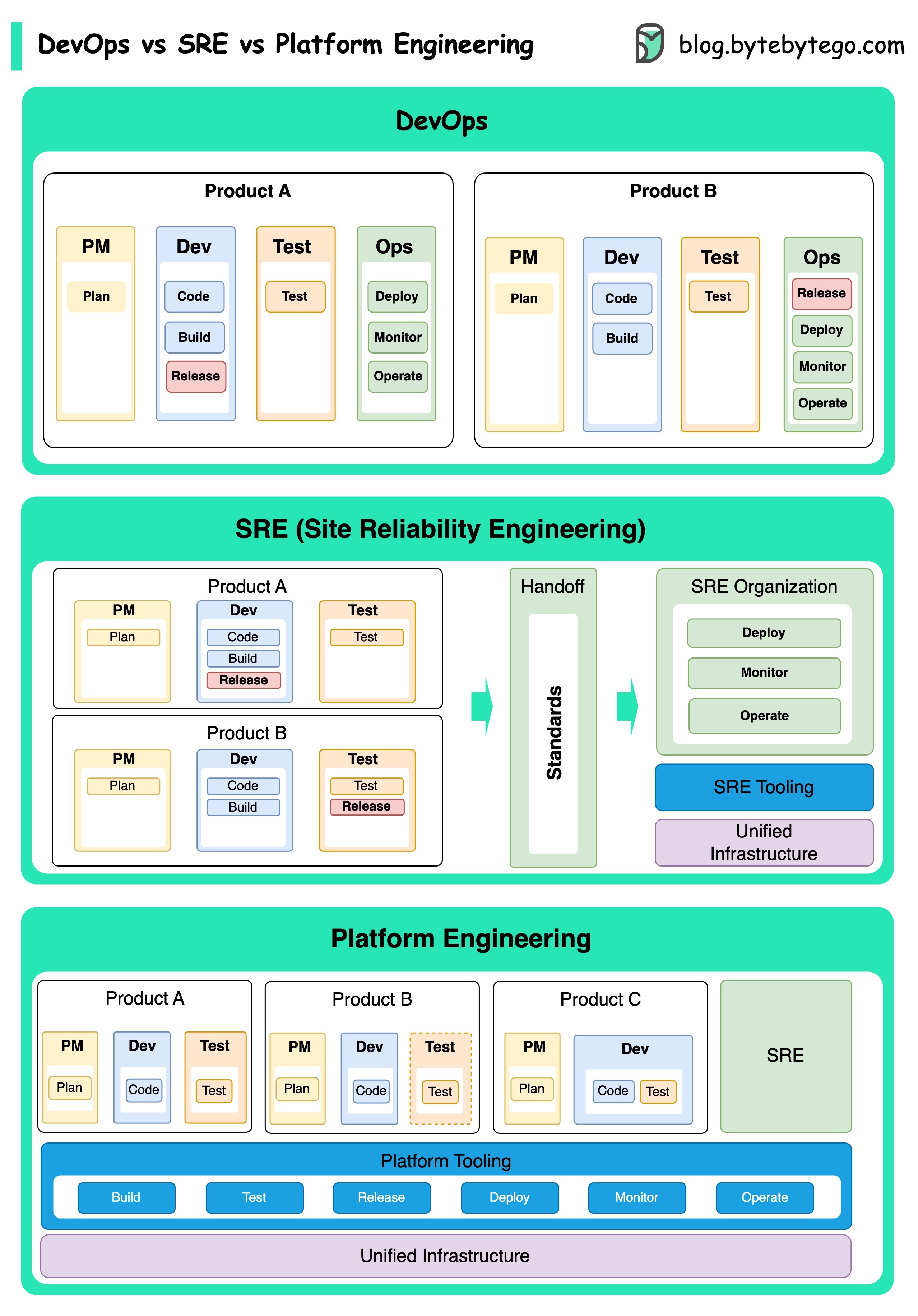
DevOps como concepto fue introducido en 2009 por Patrick DeBois y Andrew Shafer en la Conferencia Agile. Intentaron cerrar la brecha entre el desarrollo y las operaciones de software promoviendo una cultura colaborativa y compartieron la responsabilidad de todo el ciclo de vida del desarrollo de software.
SRE, o ingeniería de confiabilidad del sitio, fue pionera en Google a principios de la década de 2000 para abordar los desafíos operativos en la gestión de sistemas complejos a gran escala. Google desarrolló prácticas y herramientas de SRE, como el sistema de gestión de clúster Borg y el sistema de monitoreo Monarch, para mejorar la confiabilidad y la eficiencia de sus servicios.
Platform Engineering es un concepto más reciente, basándose en la base de la ingeniería SRE. Los orígenes precisos de la ingeniería de la plataforma son menos claros, pero generalmente se entiende como una extensión de las prácticas DevOps y SRE, con un enfoque en ofrecer una plataforma integral para el desarrollo de productos que respalde toda la perspectiva comercial.
Vale la pena señalar que si bien estos conceptos surgieron en diferentes momentos. Todos están relacionados con la tendencia más amplia de mejorar la colaboración, la automatización y la eficiencia en el desarrollo y las operaciones de software.
K8S es un sistema de orquestación de contenedores. Se utiliza para la implementación y gestión de contenedores. Su diseño se ve muy afectado por el sistema interno Borg de Google.
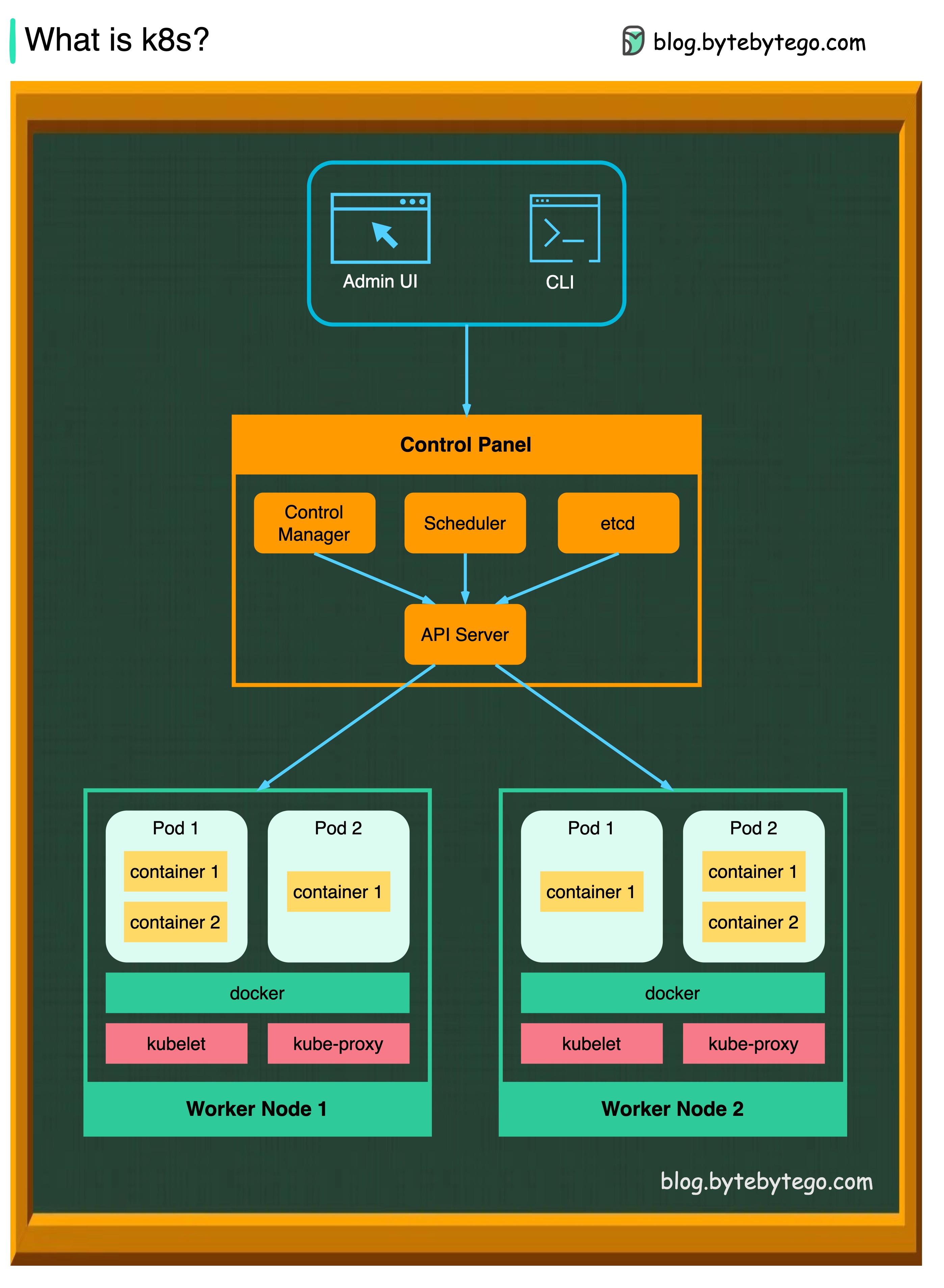
Un clúster K8S consiste en un conjunto de máquinas de trabajadores, llamadas nodos, que ejecutan aplicaciones contenedores. Cada clúster tiene al menos un nodo de trabajador.
Los nodos de trabajadores alojan las cápsulas que son los componentes de la carga de trabajo de la aplicación. El plano de control administra los nodos de los trabajadores y las cápsulas en el clúster. En los entornos de producción, el plano de control generalmente se ejecuta en múltiples computadoras, y un clúster generalmente ejecuta múltiples nodos, proporcionando tolerancia a fallas y alta disponibilidad.
Servidor API
El servidor API habla con todos los componentes en el clúster K8S. Todas las operaciones en POD se ejecutan hablando con el servidor API.
Programador
El Scheduler observa cargas de trabajo POD y asigna cargas en POD recién creados.
Gerente de controlador
El administrador del controlador ejecuta los controladores, incluido el controlador de nodo, el controlador de trabajo, el controlador de punto final y el controlador ServiceCcount.
Etcd
ETCD es un almacén de valores clave utilizado como almacenamiento de Kubernetes para todos los datos del clúster.
Vaina
Una cápsula es un grupo de contenedores y es la unidad más pequeña que administra K8s. Las vainas tienen una sola dirección IP aplicada a cada contenedor dentro de la vaina.
Kubelet
Un agente que se ejecuta en cada nodo en el clúster. Asegura que los contenedores funcionen en una cápsula.
Kube proxy
Kube-Proxy es un proxy de red que se ejecuta en cada nodo en su clúster. Enruta el tráfico que llega a un nodo desde el servicio. Reenvía solicitudes de trabajo a los contenedores correctos.

¿Qué es Docker?
Docker es una plataforma de código abierto que le permite empaquetar, distribuir y ejecutar aplicaciones en contenedores aislados. Se centra en la contenedorización, proporcionando entornos livianos que encapsulan las aplicaciones y sus dependencias.
¿Qué es Kubernetes?
Kubernetes, a menudo denominado K8S, es una plataforma de orquestación de contenedores de código abierto. Proporciona un marco para automatizar la implementación, escala y administración de aplicaciones contenedores en un clúster de nodos.
¿En qué se diferentes el uno del otro?
Docker: Docker opera a nivel de contenedor individual en un solo host del sistema operativo.
Debe administrar manualmente cada host y configurar redes, políticas de seguridad y el almacenamiento para múltiples contenedores relacionados pueden ser complejos.
Kubernetes: Kubernetes opera a nivel de clúster. Gestiona múltiples aplicaciones contenedores en múltiples hosts, proporcionando automatización para tareas como el equilibrio de carga, el escala y la garantía del estado de aplicaciones deseado.
En resumen, Docker se centra en la contenedorización y en la ejecución de contenedores en hosts individuales, mientras que Kubernetes se especializa en administrar y orquestar contenedores a escala a través de un clúster de hosts.
El siguiente diagrama muestra la arquitectura de Docker y cómo funciona cuando ejecutamos "Docker Build", "Docker Pull" y "Docker Run".
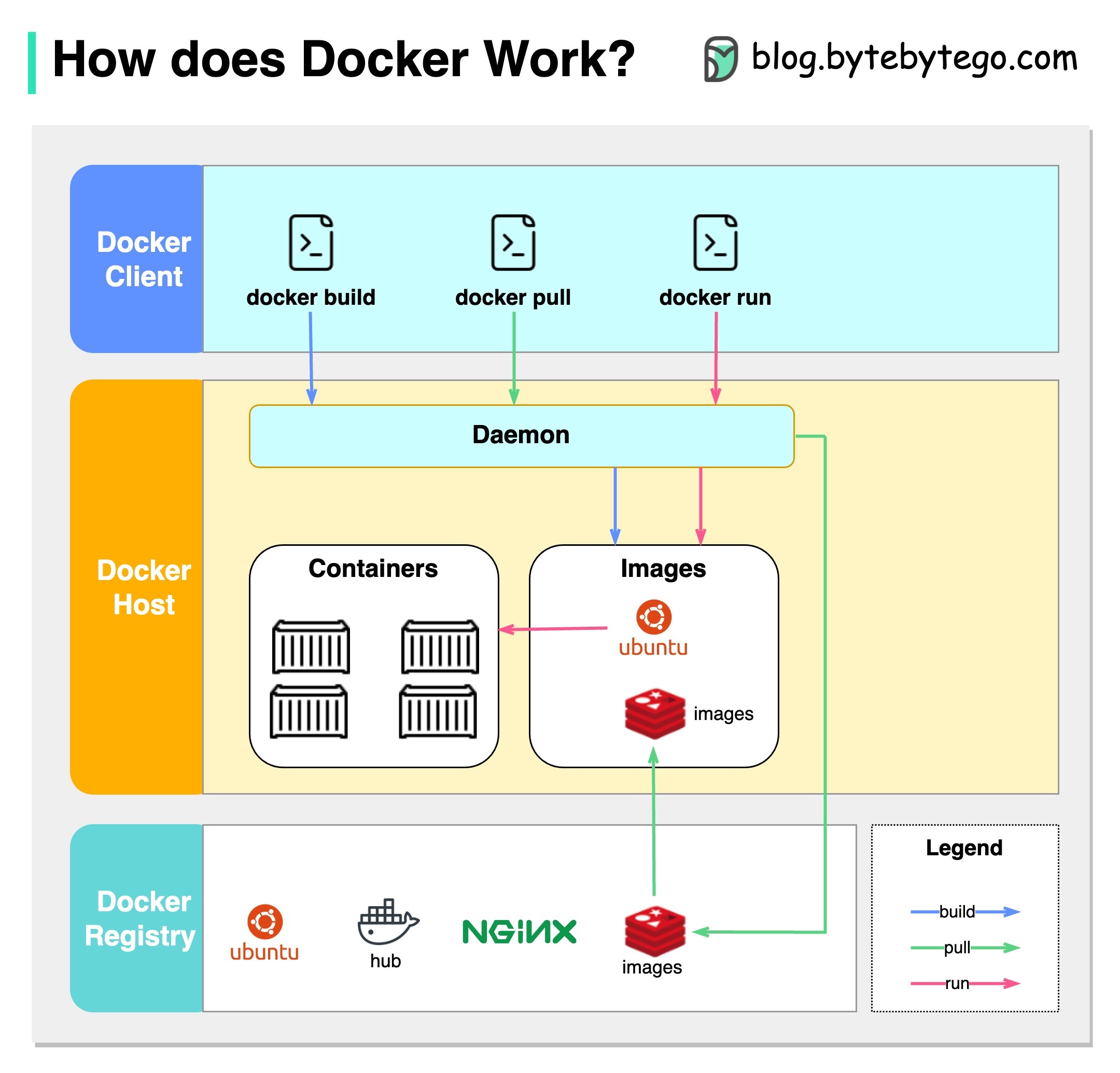
Hay 3 componentes en Docker Architecture:
Cliente de Docker
El cliente de Docker habla con Docker Daemon.
Anfitrión de Docker
El Docker Daemon escucha las solicitudes de la API de Docker y administra objetos Docker como imágenes, contenedores, redes y volúmenes.
Registro de Docker
Un registro de Docker almacena imágenes Docker. Docker Hub es un registro público que cualquiera puede usar.
Tomemos el comando "Docker Run" como ejemplo.
Para empezar, es esencial identificar dónde se almacena nuestro código. La suposición común es que solo hay dos ubicaciones, una en un servidor remoto como GitHub y el otro en nuestra máquina local. Sin embargo, esto no es del todo preciso. Git mantiene tres almacenes locales en nuestra máquina, lo que significa que nuestro código se puede encontrar en cuatro lugares:
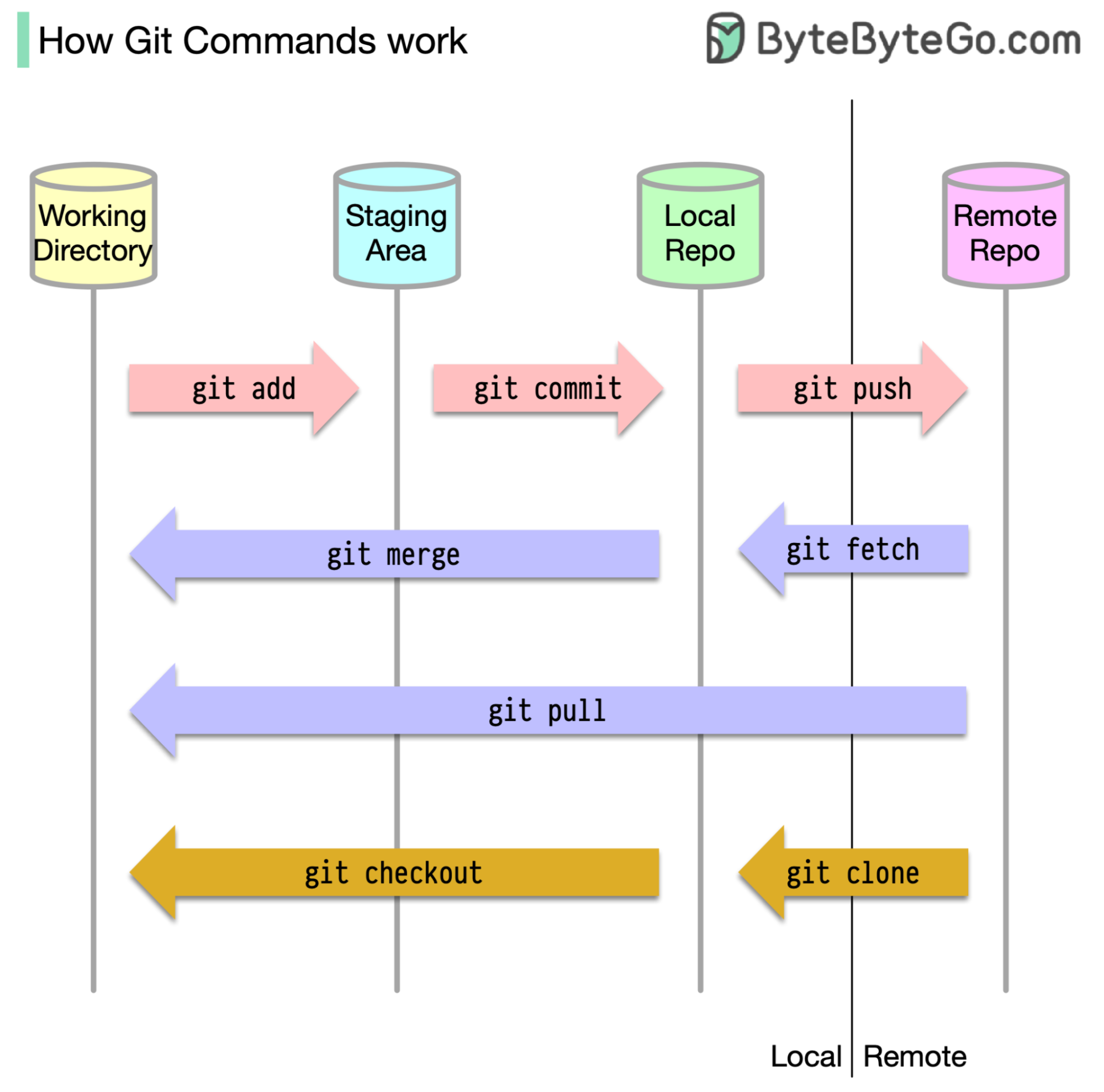
La mayoría de los comandos GIT mueven principalmente archivos entre estas cuatro ubicaciones.
El siguiente diagrama muestra el flujo de trabajo Git.
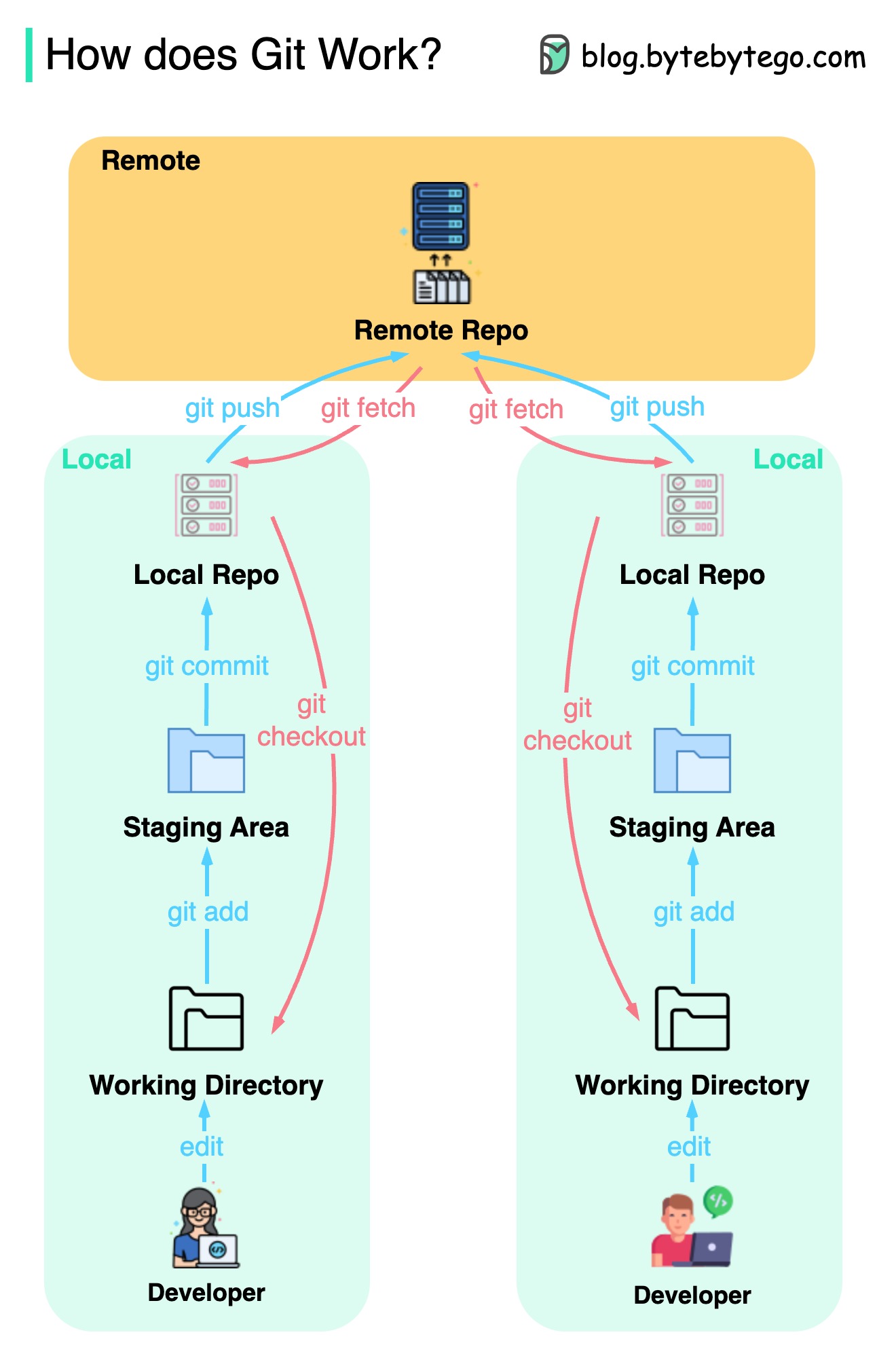
Git es un sistema de control de versiones distribuido.
Cada desarrollador mantiene una copia local del principal repositorio y edita y se compromete a la copia local.
La confirmación es muy rápida porque la operación no interactúa con el repositorio remoto.
Si el repositorio remoto se bloquea, los archivos se pueden recuperar de los repositorios locales.
¿Cuáles son las diferencias?


