ai pizza
1.0.0
Aún así, nadie sabe si una máquina puede crear algo nuevo o si se limita a lo que ya sabe. Pero incluso ahora, la inteligencia artificial puede resolver problemas complicados y analizar conjuntos de datos no estructurados. En Dodo decidimos realizar un experimento. Organizar y describir estructuralmente algo que se considera caótico y subjetivo: el sabor. Decidimos utilizar la inteligencia artificial para encontrar las combinaciones más extravagantes de ingredientes que, sin embargo, la mayoría de la gente considerará deliciosas.
En colaboración con expertos de MIPT y Skoltech, creamos inteligencia artificial que ha analizado más de 300.000 recetas y resultados de investigaciones sobre combinaciones moleculares de ingredientes realizadas por Cambridge y varias otras universidades de EE. UU. En base a esto, la IA ha aprendido a encontrar conexiones no obvias entre ingredientes y a comprender cómo combinarlos y cómo la presencia de cada uno influye en las combinaciones de todos los demás.
Para cualquier modelo necesitas datos. Por eso, para entrenar nuestra IA, recopilamos más de 300.000 recetas de cocina.
La parte difícil no fue recolectarlos sino lograr que tuvieran la misma forma. Por ejemplo, el ají en las recetas aparece como “chilli”, “chili”, “chiles” o incluso “chillis”. Para nosotros es obvio que todos estos significan "chile", pero la red neuronal considera a cada uno de ellos como una entidad individual.
Inicialmente, teníamos más de 100.000 ingredientes únicos y, después de limpiar los datos, solo quedaron 1.000 posiciones únicas.
Una vez que obtuvimos el conjunto de datos, hicimos un análisis inicial. Primero, hicimos una evaluación cuantitativa de cuántas cocinas estaban presentes en nuestro conjunto de datos.
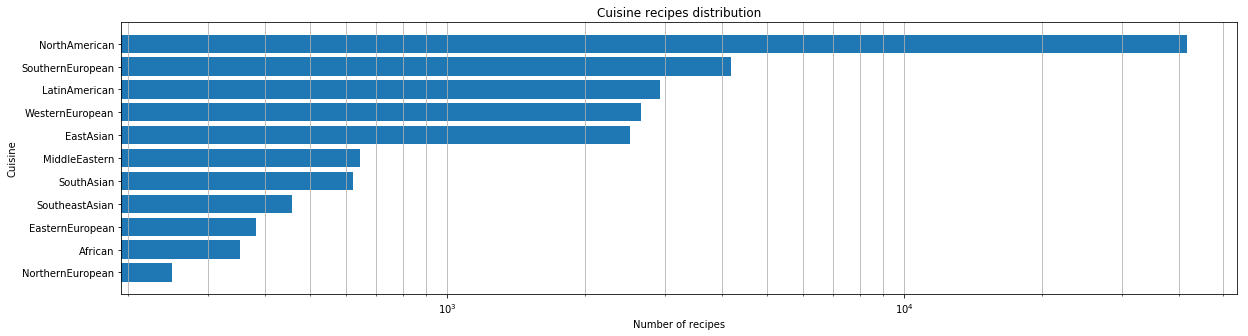
Para cada cocina, hemos identificado los ingredientes más populares.
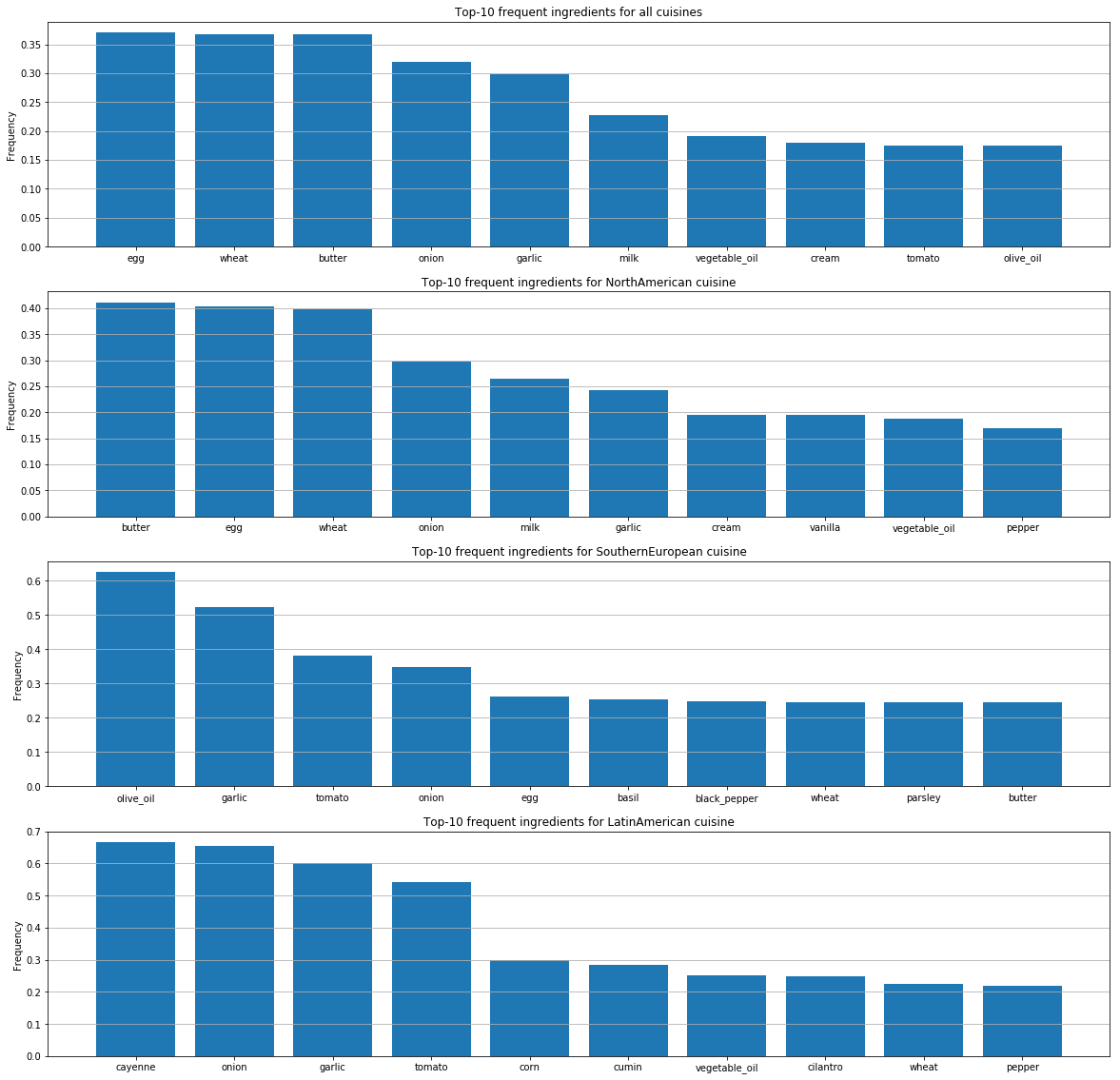
Estos gráficos muestran diferencias en las preferencias gustativas de las personas por país y diferencias en la forma en que combinan los ingredientes.
Después de eso, decidimos analizar recetas de pizza de todo el mundo para descubrir los patrones. Estas son las conclusiones que hemos sacado.
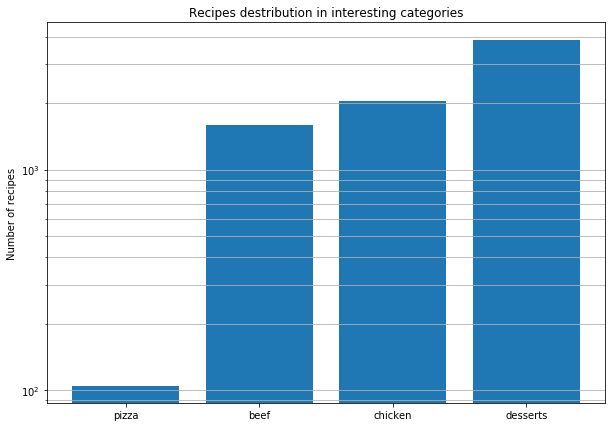
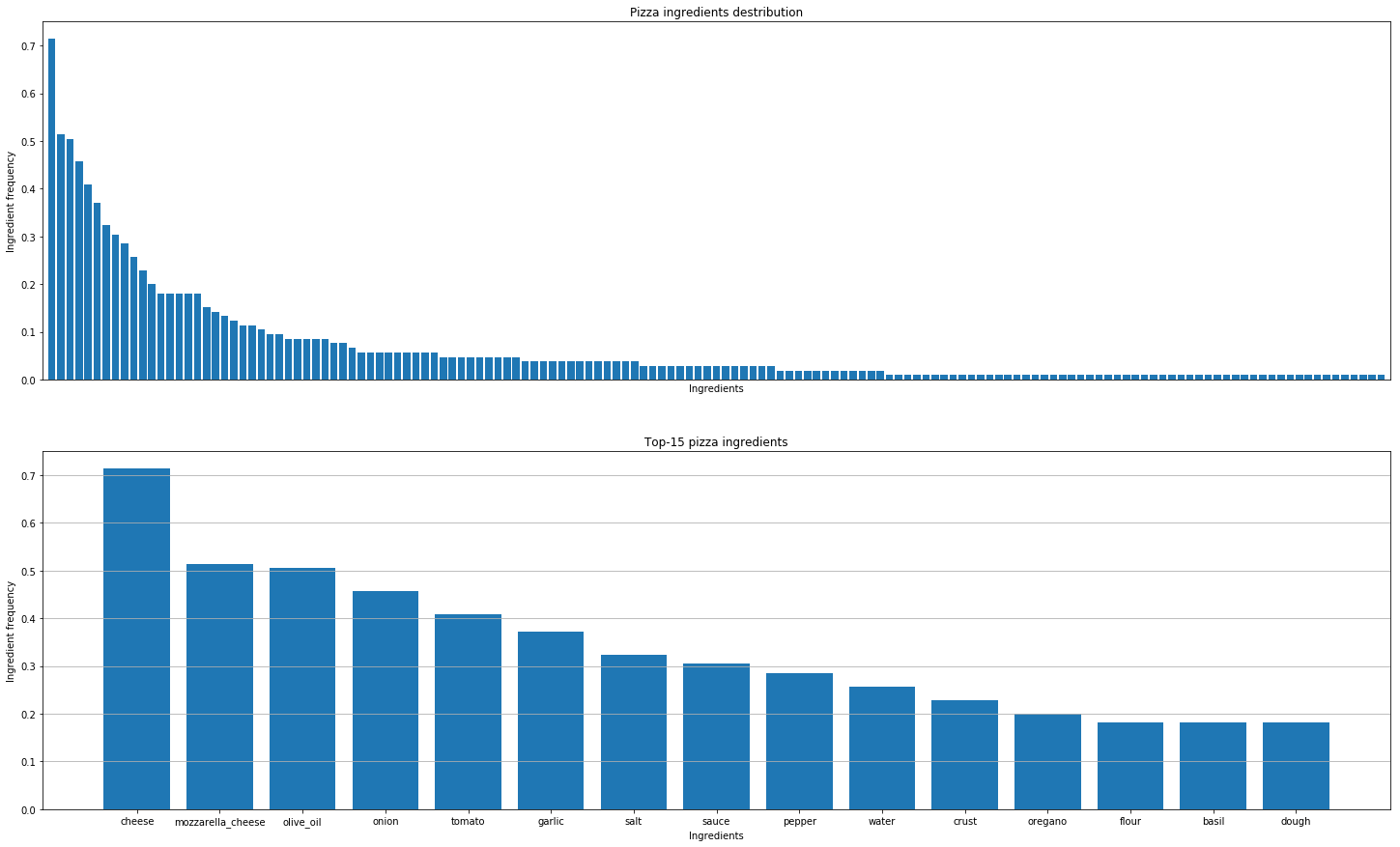
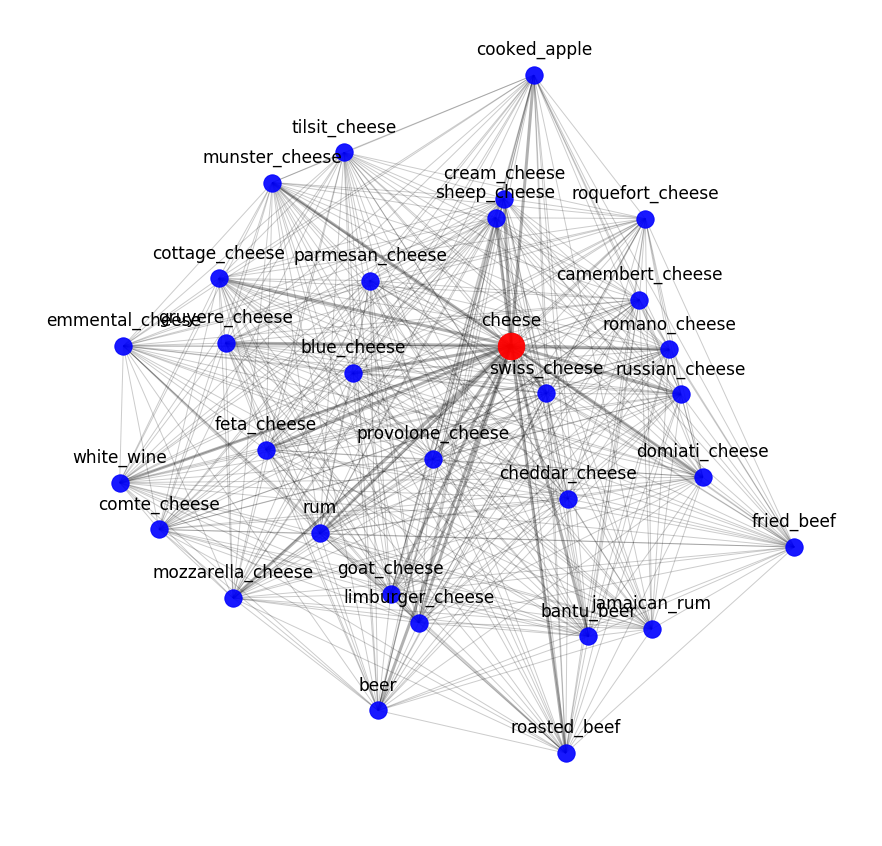
Encontrar combinaciones de sabores reales no es lo mismo que descubrir combinaciones moleculares. Todos los quesos tienen la misma composición molecular, pero eso no significa que las buenas combinaciones solo puedan surgir de los ingredientes más parecidos.
Sin embargo, son las combinaciones de ingredientes molecularmente similares las que necesitamos ver cuando convertimos los ingredientes en matemáticas. Porque objetos similares (los mismos quesos) deben seguir siendo similares, sin importar cómo los describamos. De esta manera podemos determinar si los objetos están descritos correctamente.
Para presentar la receta en una forma comprensible para la red neuronal, utilizamos Skip-Gram Negative Sampling (SGNS), un algoritmo de word2vec basado en la aparición de palabras en contexto.
Decidimos no utilizar modelos word2vec previamente entrenados porque la estructura semántica de la receta es diferente a la de los textos simples. Y con estos modelos podríamos perder información importante.
Puede evaluar el resultado de word2vec observando los vecinos semánticos más cercanos. Por ejemplo, esto es lo que nuestro modelo sabe sobre el queso:
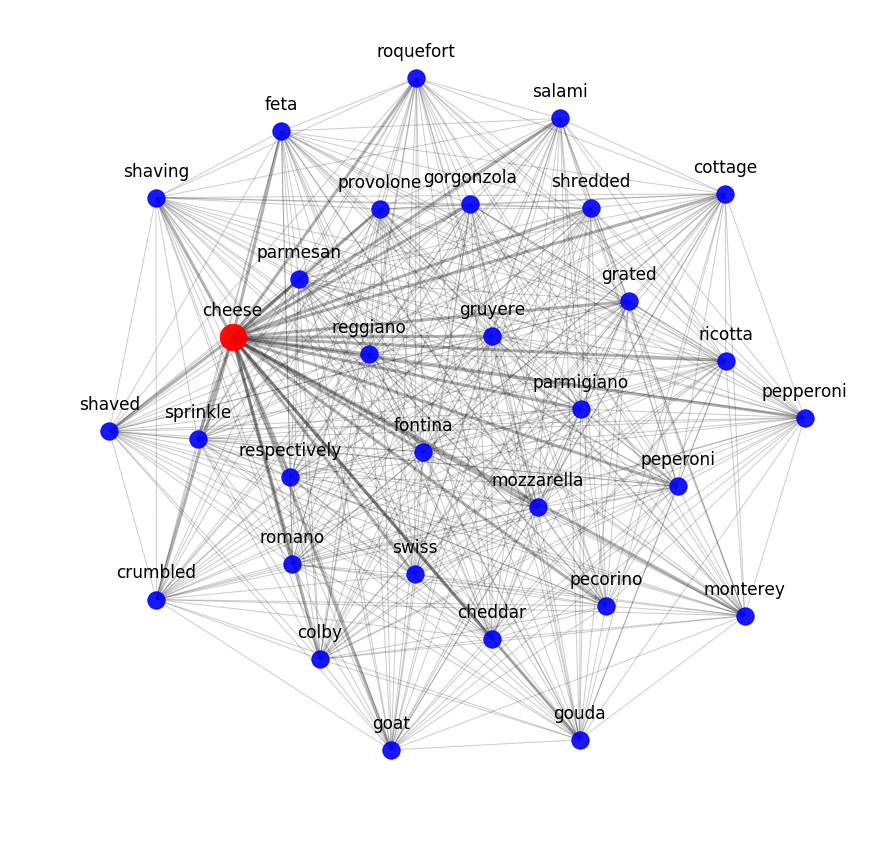
Para probar hasta qué punto los modelos semánticos pueden capturar las interrelaciones de los ingredientes en las recetas, aplicamos un modelo temático. En otras palabras, intentamos dividir el conjunto de datos de recetas en grupos según regularidades determinadas matemáticamente.
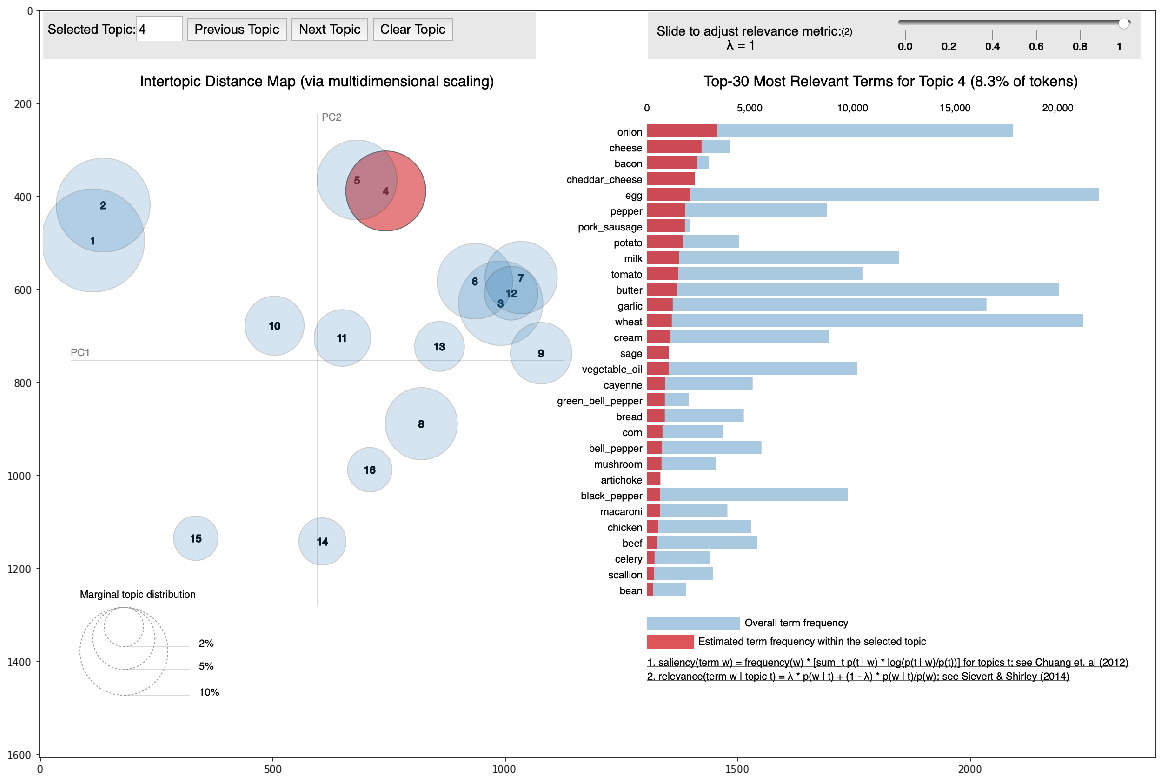
Para todas las recetas, conocíamos determinados grupos a los que correspondían. Para recetas de muestra, conocíamos su conexión con grupos reales. En base a esto encontramos el vínculo entre estos dos tipos de clusters.
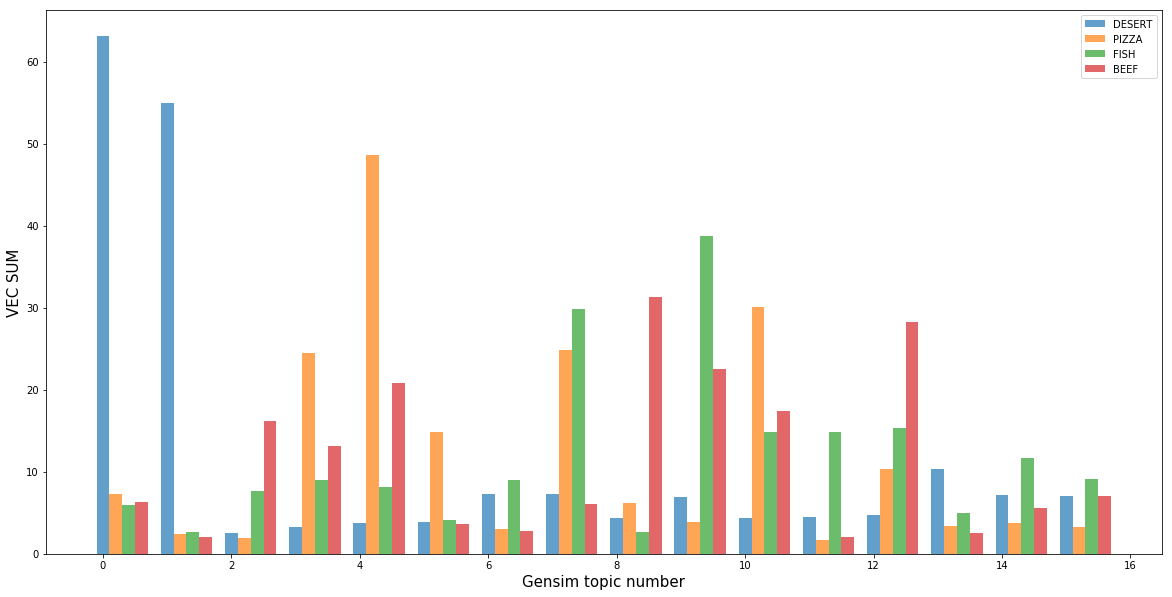
La más evidente fue la clase de postres, que se incluyeron en los temas 0 y 1, generados por el modelo de temas. Además de los postres, casi no hay otras clases sobre estos temas, lo que sugiere que los postres se separan fácilmente de otras clases de platos. Además, cada tema tiene una clase que lo describe mejor. Esto significa que nuestros modelos han logrado definir matemáticamente el significado no obvio de "sabor".
Usamos dos redes neuronales recurrentes para crear nuevas recetas. Para ello partimos del supuesto de que en todo el espacio de recetas hay un subespacio que corresponde a las recetas de pizza. Y para que la red neuronal aprendiera a crear nuevas recetas de pizza, teníamos que encontrar este subespacio.
Esta tarea es similar a la codificación automática de imágenes, en la que presentamos la imagen como un vector de baja dimensión. Estos vectores pueden contener mucha información específica sobre la imagen.
Por ejemplo, estos vectores pueden almacenar información sobre el color de cabello de una persona en una celda separada para el reconocimiento facial en una fotografía. Elegimos este enfoque precisamente por las propiedades únicas del subespacio oculto.
Para identificar el subespacio de pizza, pasamos las recetas de pizza a través de dos redes neuronales recurrentes. El primero recibió la receta de la pizza y encontró su representación como un vector latente. El segundo recibió un vector latente de la primera red neuronal y creó una receta basada en él. Las recetas en la entrada de la primera red neuronal y en la salida de la segunda deberían haber coincidido.
De esta forma, dos redes neuronales aprendieron a transformar correctamente la receta de un vector latente. Y a partir de esto pudimos encontrar un subespacio oculto que corresponde a toda la gama de recetas de pizza.
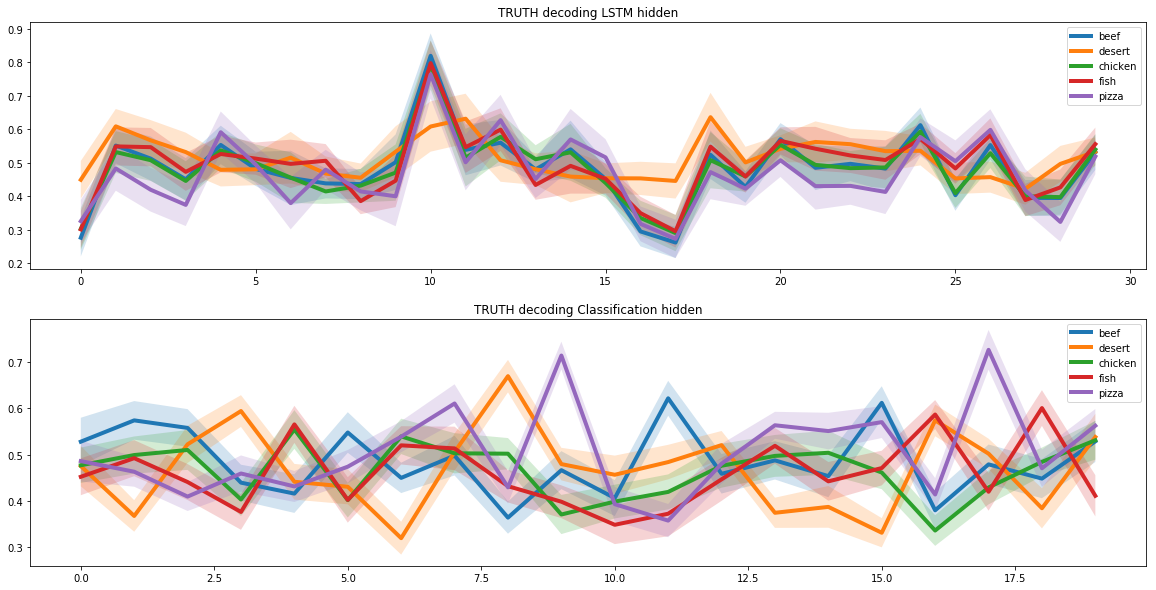
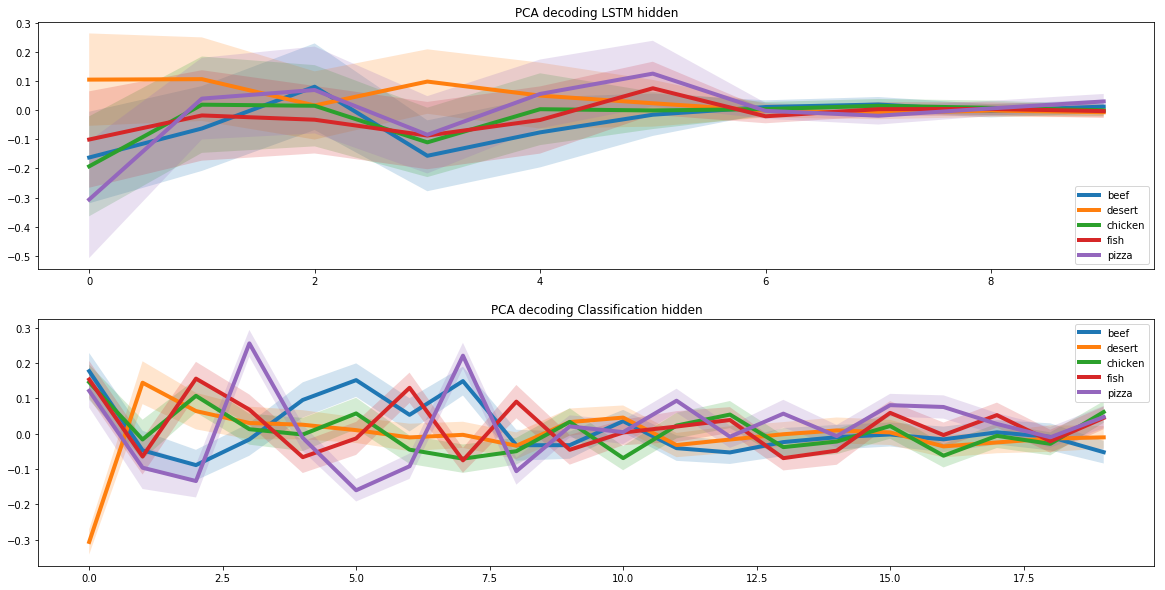
Cuando resolvimos el problema de crear una receta de pizza, tuvimos que agregar criterios de combinación molecular al modelo. Para ello utilizamos los resultados de un estudio conjunto de científicos de Cambridge y varias universidades estadounidenses.
El estudio encontró que los ingredientes con los pares moleculares más comunes forman las mejores combinaciones. Por lo tanto, al crear la receta, la red neuronal prefirió ingredientes con una estructura molecular similar.
Como resultado, nuestra red neuronal aprendió a crear recetas de pizza. Al ajustar los coeficientes, la red neuronal puede producir tanto recetas clásicas como margaritas o pepperoni como recetas inusuales, una de las cuales es el corazón de Opensource Pizza.
| No | Receta |
|---|---|
| 1 | espinacas, queso, tomate, aceituna negra, aceituna, ajo, pimienta, albahaca, cítricos, melón, brote, suero de leche, limón, lubina, nuez, colinabo |
| 2 | cebolla, tomate, aceituna, pimienta negra, pan, masa |
| 3 | pollo, cebolla, aceituna_negra, queso, salsa, tomate, aceite_de_oliva, queso_mozzarella |
| 4 | tomate, mantequilla, queso_crema, pimienta, aceite_de_oliva, queso, pimienta_negra, queso_mozzarella |
Open Source Pizza tiene licencia MIT.
Golodyaev Arseniy, MIPT, Skoltech, [email protected]
Egor Baryshnikov, Skoltech, [email protected]


