meme search engine
1.0.0
¿Tienes una carpeta grande de memes que deseas buscar semánticamente? ¿Tiene un servidor Linux con una GPU Nvidia? Tú haces; esto ahora es obligatorio.
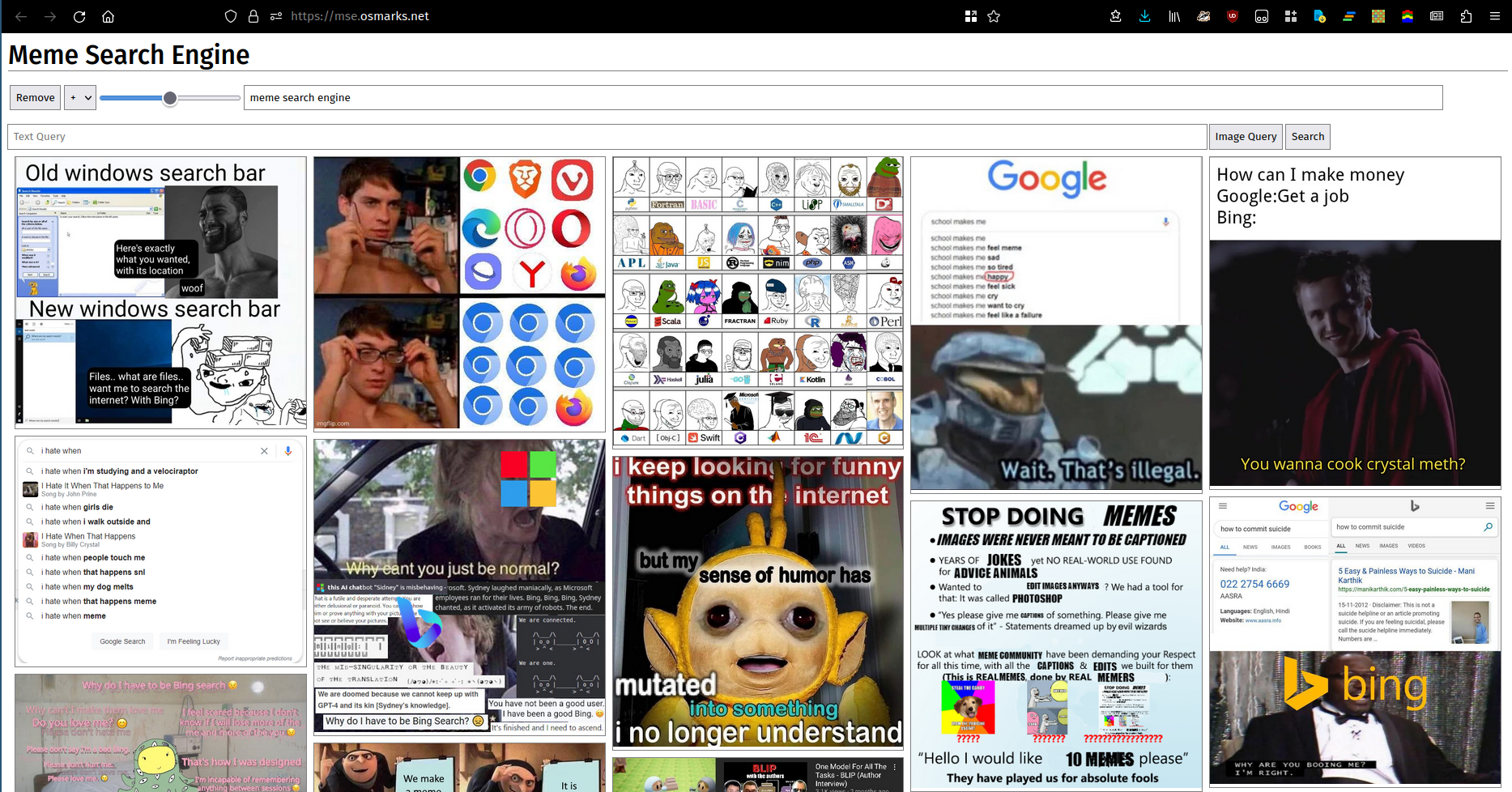
Dicen que una imagen vale más que mil palabras. Desafortunadamente, muchos (¿la mayoría?) conjuntos de palabras no pueden describirse adecuadamente mediante imágenes. De todos modos, aquí hay una foto. Puede utilizar una instancia en ejecución aquí.
Esto no está probado. Podría funcionar. La nueva versión de Rust simplifica algunos pasos (integra su propia miniatura).
python -m http.server .pip desde requirements.txt (las versiones probablemente no deberían coincidir exactamente si necesita cambiarlas; solo puse lo que tengo instalado actualmente).transformers debido a la compatibilidad con SigLIP.thumbnailer.py (periódicamente, al mismo tiempo que se recarga el índice, idealmente)clip_server.py (como servicio en segundo plano).clip_server_config.json .device probablemente debería ser cuda o cpu . El modelo seguirá funcionando aquí.model esmodel_name es el nombre del modelo a efectos de métricas.max_batch_size controla el tamaño de lote máximo permitido. Los valores más altos generalmente dan como resultado un rendimiento algo mejor (aunque el cuello de botella en la mayoría de los casos está en otra parte en este momento) a costa de un mayor uso de VRAM.port es el puerto para ejecutar el servidor HTTP.meme-search-engine (Rust) (también como servicio en segundo plano).clip_server es la URL completa del servidor backend.db_path es la ruta a la base de datos SQLite de imágenes y vectores de incrustación.files es desde donde se leerán los archivos meme. Los subdirectorios están indexados.port es el puerto en el que se sirve HTTP.enable_thumbs en true para mostrar imágenes comprimidas.npm install , node src/build.js .frontend_config.json .image_path es la URL base de su servidor web de memes (con una barra diagonal).backend_url es la URL en la que se expone mse.py (la barra diagonal probablemente sea opcional).clip_server.py . Consulte aquí para obtener información sobre MemeThresher, el nuevo sistema automático de adquisición/clasificación de memes (en meme-rater ). Se prevé que implementarlo usted mismo será algo complicado, pero debería ser aproximadamente factible:
crawler.py con su propia fuente y ejecútelo para recopilar un conjunto de datos inicial.mse.py con un archivo de configuración como el proporcionado para indexarlo.rater_server.py para recopilar un conjunto de datos inicial de pares.train.py para entrenar un modelo. Es posible que deba ajustar los hiperparámetros ya que no tengo idea de cuáles son buenos.active_learning.py en el mejor punto de control disponible para obtener nuevos pares para calificar.copy_into_queue.py para copiar los nuevos pares en la cola rater_server.py .library_processing_server.py y programe meme_pipeline.py para que se ejecute periódicamente. Meme Search Engine usa un índice FAISS en memoria para contener sus vectores de incrustación, porque era vago y funciona bien (~100 MB de RAM total usado para mis 8000 memes). Si desea almacenar mucho más que eso, tendrá que cambiar a un índice más eficiente/compacto (ver aquí). Como los índices vectoriales se guardan exclusivamente en la memoria, deberá conservarlos en el disco o utilizar aquellos que sean rápidos de crear, eliminar o agregar (presumiblemente índices PCA/PQ). En algún momento, si aumenta el tráfico total, el modelo CLIP también puede convertirse en un cuello de botella, ya que tampoco tengo una estrategia de procesamiento por lotes. Actualmente, la indexación está vinculada a la GPU, ya que el nuevo modelo parece algo más lento en lotes de gran tamaño y mejoré el proceso de carga de imágenes. Es posible que también desee reducir los memes mostrados para reducir las necesidades de ancho de banda.


