PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtTodos los modelos se descargarán automáticamente. También puede optar por descargar manualmente desde esta URL.
| Modelo | #parámetros | URL | Descargar en OpenXLab |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | vae | vae |
| PixArt-α-SAM-256 | 0,6 mil millones | PixArt-XL-2-SAM-256x256.pth o versión difusores | 256-SAM |
| PixArt-α-256 | 0,6 mil millones | PixArt-XL-2-256x256.pth o versión difusores | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0,6 mil millones | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0,6 mil millones | PixArt-XL-2-512x512.pth o versión difusores | 512 |
| PixArt-α-1024 | 0,6 mil millones | PixArt-XL-2-1024-MS.pth o versión difusores | 1024 |
| PixArt-δ-1024-LCM | 0,6 mil millones | versión difusores | |
| Codificador ControlNet-HED | 30M | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0,9 mil millones | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0,9 mil millones | PixArt-XL-2-1024-ControlNet.pth | 1024 |
TAMBIÉN encuentre todos los modelos en OpenXLab_PixArt-alpha
En primer lugar.
Gracias a @kopyl, puedes reproducir todo el flujo de entrenamiento en el conjunto de datos de Pokémon de HugginFace con cuadernos:
Luego, para más detalles.
Aquí tomamos la configuración de entrenamiento del conjunto de datos SAM como ejemplo, pero, por supuesto, también puedes preparar tu propio conjunto de datos siguiendo este método.
SOLO necesita cambiar el archivo de configuración en config y el cargador de datos en el conjunto de datos.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256La estructura de directorios para el conjunto de datos SAM es:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Aquí preparamos data_toy para una mejor comprensión.
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyEntonces, aquí hay un ejemplo de archivo partición/part0.txt.
Además, para la capacitación guiada sobre archivos json, aquí hay un archivo json de juguete para una mejor comprensión.
Siguiendo las instrucciones de formación Pixart + DreamBooth
Siguiendo la guía de formación PixArt + LCM
Siguiendo la guía de capacitación PixArt + ControlNet
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision= " fp16 "
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column= " text "
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler= " constant " --lr_warmup_steps=0
--seed=42
--output_dir= " pixart-pokemon-model "
--validation_prompt= " cute dragon creature " --report_to= " tensorboard "
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16 La inferencia requiere al menos 23GB de memoria GPU con este repositorio, mientras que 11GB and 8GB se usan en ? difusores.
Actualmente soporte:
Para comenzar, primero instale las dependencias requeridas. Asegúrese de haber descargado los modelos en la carpeta salida/pretrained_models y luego ejecútelos en su máquina local:
DEMO_PORT=12345 python app/app.pyComo alternativa, se proporciona un Dockerfile de muestra para crear un contenedor de tiempo de ejecución que inicie la aplicación Gradio.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v < path_to_huggingface_cache > :/root/.cache/huggingface pixartO utilice Docker-Compose. Tenga en cuenta que si desea cambiar el contexto de la versión 1024 a 512 o LCM de la aplicación, simplemente cambie la variable de entorno APP_CONTEXT en el archivo docker-compose.yml. El valor predeterminado es 1024
docker compose build
docker compose up Echemos un vistazo a un ejemplo sencillo utilizando http://your-server-ip:12345 .
Asegúrese de tener las versiones actualizadas de las siguientes bibliotecas:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4Y luego:
import torch
from diffusers import PixArtAlphaPipeline , ConsistencyDecoderVAE , AutoencoderKL
device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline . from_pretrained ( "PixArt-alpha/PixArt-XL-2-1024-MS" , torch_dtype = torch . float16 , use_safetensors = True )
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe . to ( device )
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe ( prompt ). images [ 0 ]
image . save ( "./catcus.png" )Consulte la documentación para obtener más información sobre SA-Solver Sampler.
Esta integración permite ejecutar la canalización con un tamaño de lote de 4 con 11 GB de GPU VRAM. Consulte la documentación para obtener más información.
PixArtAlphaPipeline en menos de 8 GB de GPU VRAMAhora se admite el consumo de GPU VRAM inferior a 8 GB; consulte la documentación para obtener más información.
Para comenzar, primero instale las dependencias requeridas y luego ejecútelas en su máquina local:
# diffusers version
DEMO_PORT=12345 python app/app.py Echemos un vistazo a un ejemplo sencillo utilizando http://your-server-ip:12345 .
También puede hacer clic aquí para obtener una prueba gratuita en Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True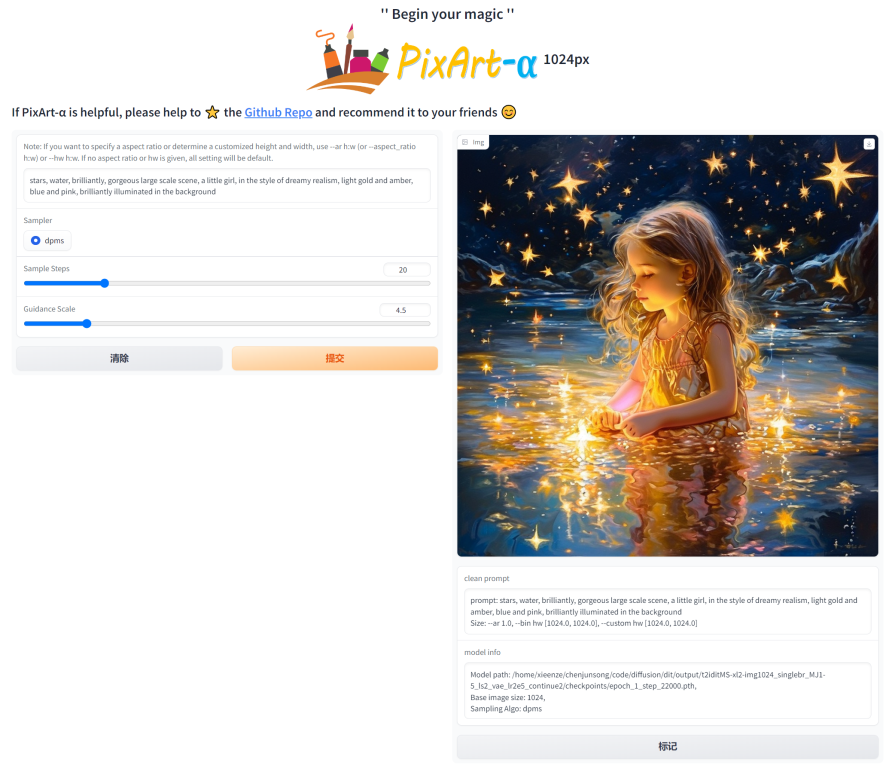
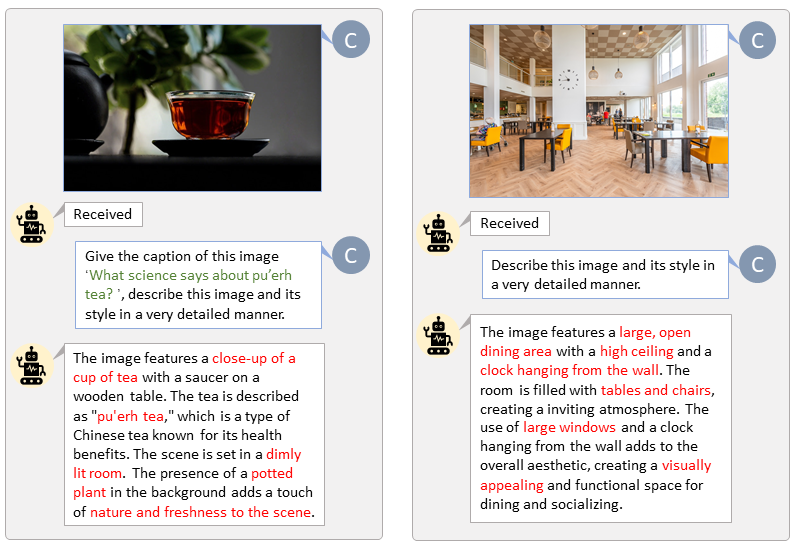
Gracias al código base de LLaVA-Lightning-MPT, podemos subtitular el conjunto de datos LAION y SAM con el siguiente código de lanzamiento:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonPresentamos etiquetado automático con indicaciones personalizadas para LAION (izquierda) y SAM (derecha). Las palabras resaltadas en verde representan el título original en LAION, mientras que las marcadas en rojo indican los títulos detallados etiquetados por LLaVA.
Prepare la función de texto T5 y la función de imagen VAE con anticipación acelerará el proceso de capacitación y ahorrará memoria de la GPU.
python tools/extract_features.py --img_size=1024
--json_path " data/data_info.json "
--t5_save_root " data/SA1B/caption_feature_wmask "
--vae_save_root " data/SA1B/img_vae_features "
--pretrained_models_dir " output/pretrained_models "
--dataset_root " data/SA1B/Images/ " Realizamos un vídeo comparando PixArt con los modelos Text-to-Image más potentes actuales.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


