Agent FLAN
1.0.0
[? AbrazandoCara] [? OpenXLab] [? Documento] [Página del proyecto]
Los modelos de lenguaje grande (LLM) de código abierto han logrado un gran éxito en diversas tareas de PNL; sin embargo, todavía son muy inferiores a los modelos basados en API cuando actúan como agentes. Cómo integrar la capacidad de los agentes en los LLM generales se convierte en un problema crucial y urgente. Este artículo ofrece primero tres observaciones clave: (1) el corpus de entrenamiento de agentes actual está enredado tanto con los formatos de seguimiento como con el razonamiento de los agentes, lo que cambia significativamente con respecto a la distribución de sus datos previos al entrenamiento; (2) Los LLM exhiben diferentes velocidades de aprendizaje sobre las capacidades requeridas por las tareas de los agentes; y (3) los enfoques actuales tienen efectos secundarios al mejorar las habilidades de los agentes mediante la introducción de alucinaciones. Con base en los hallazgos anteriores, proponemos Agent-FLAN para ajustar de manera efectiva los modelos de lenguaje para los agentes. Mediante una cuidadosa descomposición y rediseño del corpus de capacitación, Agent-FLAN permite a Llama2-7B superar los mejores trabajos anteriores en un 3,5 % en varios conjuntos de datos de evaluación de agentes. Con muestras negativas construidas de manera integral, Agent-FLAN alivia en gran medida los problemas de alucinaciones según nuestro punto de referencia de evaluación establecido. Además, mejora constantemente la capacidad del agente de los LLM al escalar el tamaño del modelo al tiempo que mejora ligeramente la capacidad general de los LLM.
La serie Agent-FLAN está optimizada en AgentInstruct y Toolbench mediante la aplicación del proceso de generación de datos propuesto en el documento Agent-FLAN, que tiene sólidas capacidades en diversas tareas del agente y utilización de herramientas.
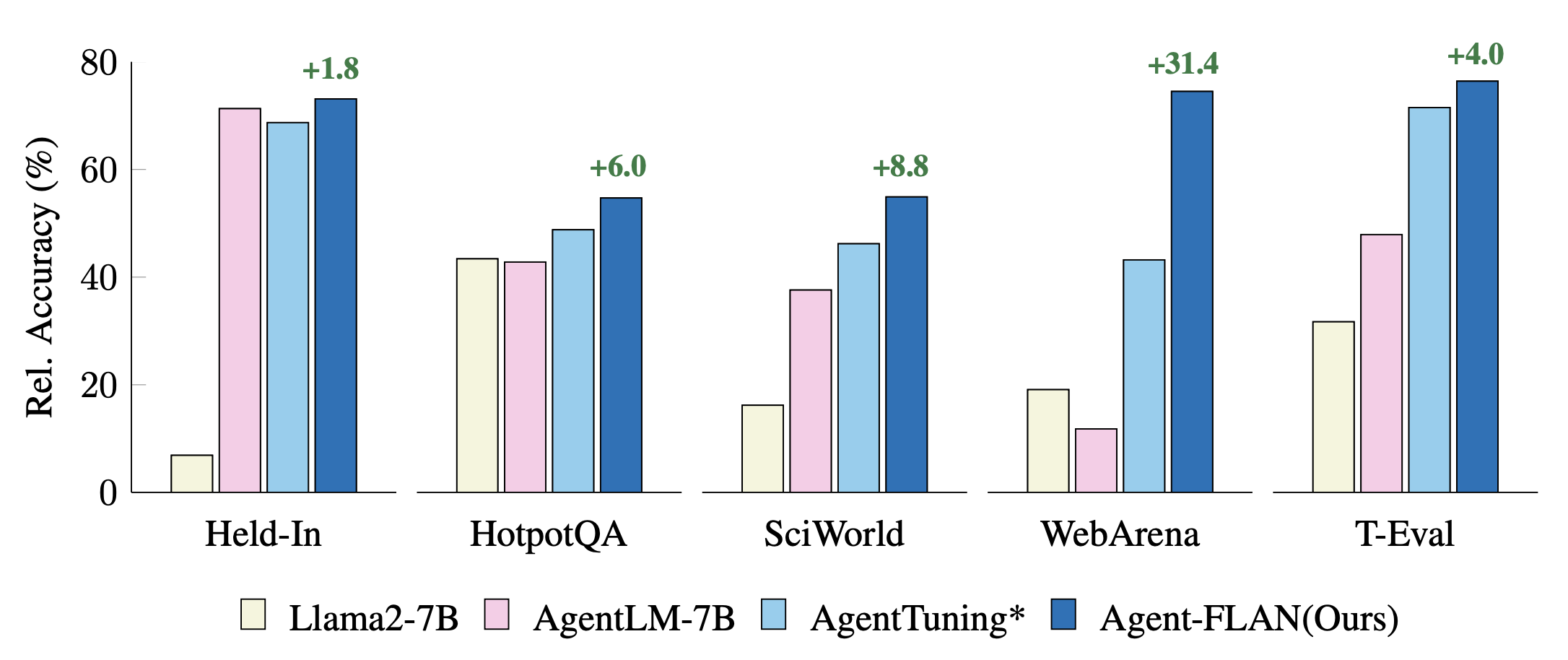
Comparación de enfoques recientes de ajuste de agentes en tareas retenidas y retenidas. El rendimiento está normalizado con los resultados de GPT-4 para una mejor visualización. * denota nuestra reimplementación para una comparación justa.
Agent-FLAN se produce mediante capacitación mixta en conjuntos de datos AgentInstruct, ToolBench y ShareGPT de la serie Llama2-chat.
Los modelos siguen el formato de conversación de Llama-2-chat, con el protocolo de plantilla como:
dict ( role = 'user' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'system' , begin = '<|Human|>െ' , end = ' n ' ),
dict ( role = 'assistant' , begin = '<|Assistant|>െ' , end = 'ി n ' ),El modelo 7B está disponible en el centro de modelos Huggingface y OpenXLab.
| Modelo | Repositorio de Huggingface | Repositorio OpenXLab |
|---|---|---|
| Agente-FLAN-7B | Enlace modelo | Enlace modelo |
El conjunto de datos Agent-FLAN también está disponible en el centro de conjuntos de datos de Huggingface.
| Conjunto de datos | Repositorio de Huggingface |
|---|---|
| Agente-FLAN | Enlace al conjunto de datos |
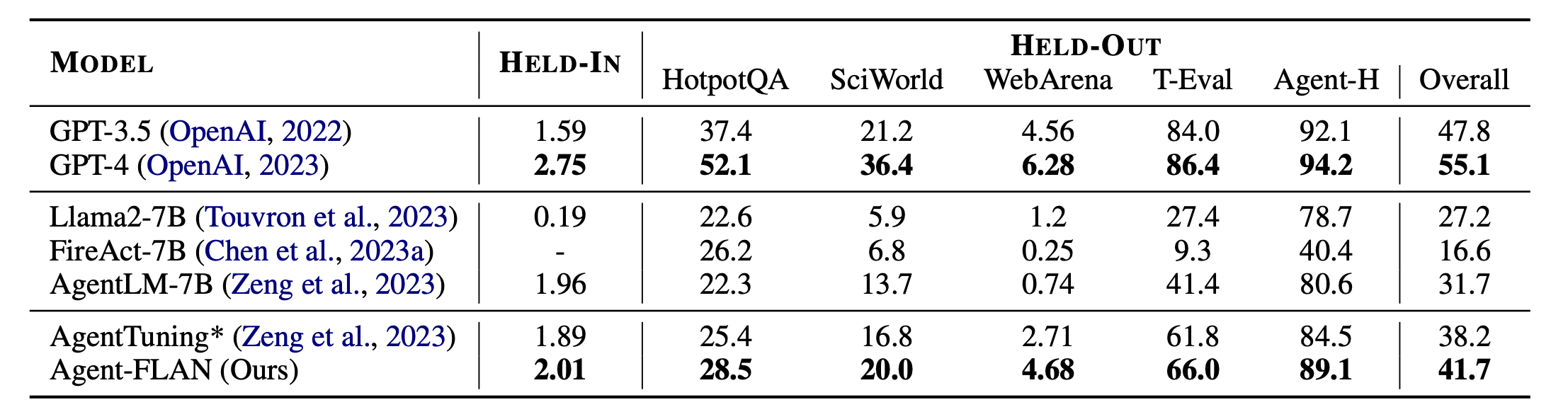
Principales resultados de Agent-FLAN. Agent-FLAN supera significativamente los enfoques anteriores de ajuste de agentes por un amplio margen tanto en tareas retenidas como en tareas retenidas. * denota nuestra reimplementación con la misma cantidad de datos de entrenamiento para una comparación justa. Dado que FireAct no se entrena en el conjunto de datos AgentInstruct, omitimos su rendimiento en el conjunto HELD-IN. Negrita: lo mejor en modelos basados en API y de código abierto.
Agent-FLAN está construido con Lagent y T-Eval. ¡Gracias por su increíble trabajo!
Si encuentra útil este proyecto en su investigación, considere citar:
@article{chen2024agent,
title={Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models},
author={Chen, Zehui and Liu, Kuikun and Wang, Qiuchen and Zhang, Wenwei and Liu, Jiangning and Lin, Dahua and Chen, Kai and Zhao, Feng},
journal={arXiv preprint arXiv:2403.12881},
year={2024}
}
Este proyecto se publica bajo la licencia Apache 2.0.


