safe rlhf
1.0.0
Beaver es un marco RLHF de código abierto altamente modular desarrollado por el equipo de PKU-Alignment de la Universidad de Pekín. Su objetivo es proporcionar datos de capacitación y una canalización de código reproducible para la investigación de alineación, especialmente la investigación LLM de alineación restringida a través de métodos Safe RLHF.
Las características clave de Beaver son:
2024/06/13 : Nos complace anunciar el código abierto de nuestro conjunto de datos PKU-SafeRLHF versión 1.0. Esta versión avanza con respecto a la versión beta inicial al incorporar anotaciones conjuntas entre humanos y IA, ampliar el alcance de las categorías de daños e introducir etiquetas detalladas de niveles de gravedad. Para obtener más detalles y acceso, visite nuestra página de conjunto de datos en ? Cara abrazada: PKU-Alignment/PKU-SafeRLHF.2024/01/16 : Nuestro método Safe RLHF ha sido aceptado por ICLR 2024 Spotlight.2023/10/19 : Publicamos nuestro documento Safe RLHF en arXiv, que detalla nuestro nuevo algoritmo de alineación segura y su implementación.2023/07/10 : Estamos encantados de anunciar el código abierto de los modelos Beaver-7B v1 / v2 / v3 como el primer hito de la serie de capacitación Safe RLHF, complementado con los correspondientes modelos de recompensa v1 / v2 / v3 / unificados. y modelos de costos v1/v2/v3/puntos de control unificados activados? Abrazando la cara.2023/07/10 : Ampliamos el conjunto de datos de preferencias de seguridad de código abierto, PKU-Alignment/PKU-SafeRLHF , que ahora contiene más de 300.000 ejemplos. (Ver también la sección PKU-SafeRLHF-Conjunto de datos)2023/07/05 : Mejoramos nuestro soporte para modelos chinos de preentrenamiento e incorporamos conjuntos de datos chinos de código abierto adicionales. (Consulte también las secciones Soporte chino (中文支持) y Conjuntos de datos personalizados (自定义数据集))2023/05/15 : Primera versión del proceso Safe RLHF, resultados de la evaluación y código de capacitación.Aprendizaje por refuerzo a partir de la retroalimentación humana: maximización de recompensas mediante el aprendizaje de preferencias
Aprendizaje por refuerzo seguro a partir de la retroalimentación humana: maximización restringida de la recompensa mediante el aprendizaje de preferencias
dónde
El objetivo final es encontrar un modelo.
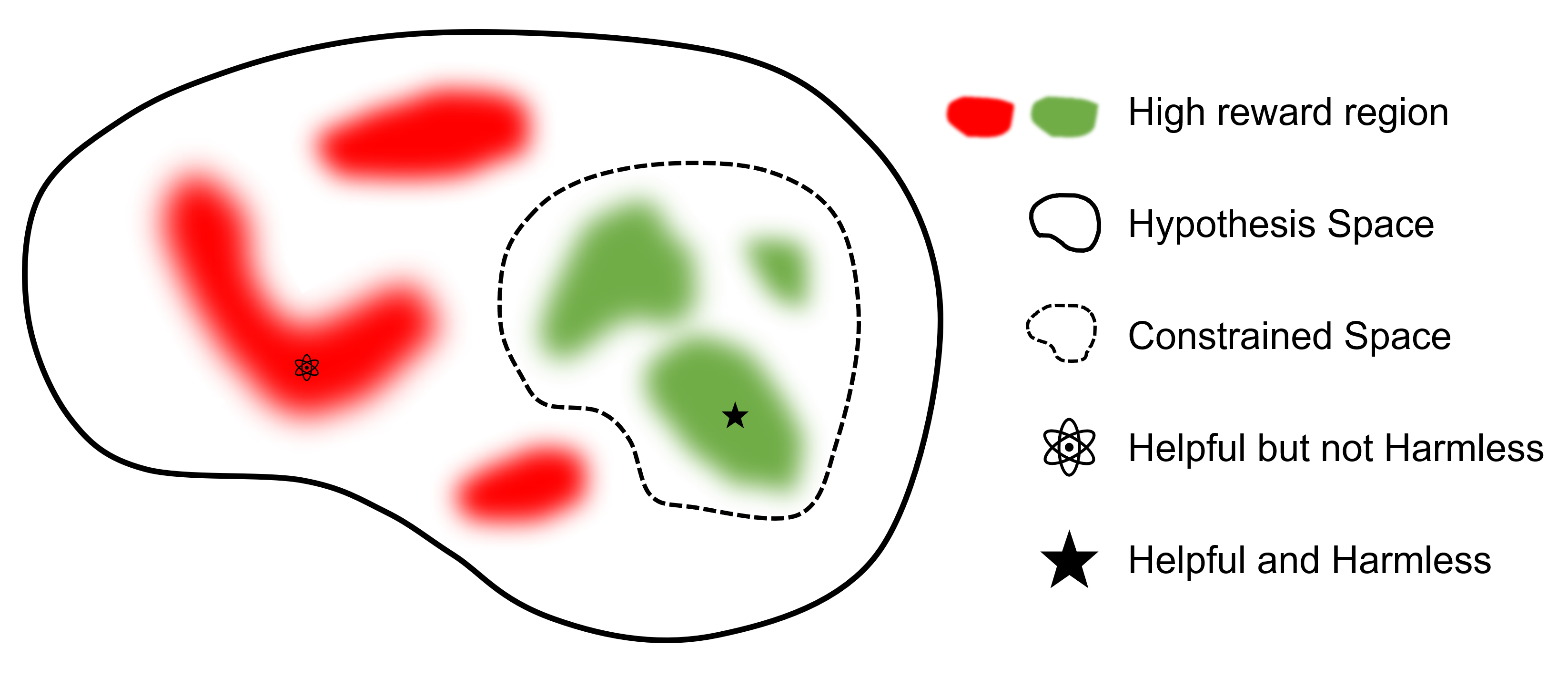
En comparación con otros marcos que admiten RLHF, safe-rlhf es el primer marco que admite todas las etapas, desde SFT hasta RLHF y Evaluación. Además, safe-rlhf es el primer marco que tiene en cuenta la preferencia de seguridad durante la etapa RLHF. Ofrece una garantía más teórica para la búsqueda de parámetros restringidos en el espacio de políticas.
| OFV | Entrenamiento del modelo de preferencia 1 | RLHF | RLHF seguro | Pérdida de PTX | Evaluación | backend | |
|---|---|---|---|---|---|---|---|
| Castor (Seguro-RLHF) | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | Velocidad profunda |
| trlX | ✔️ | 2 | ✔️ | Acelerar / NeMo | |||
| Chat de velocidad profunda | ✔️ | ✔️ | ✔️ | ✔️ | Velocidad profunda | ||
| IA colosal | ✔️ | ✔️ | ✔️ | ✔️ | ColosalAI | ||
| AlpacaGranja | 3 | ✔️ | ✔️ | ✔️ | Acelerar |
El conjunto de datos PKU-SafeRLHF es un conjunto de datos etiquetados por humanos que contiene preferencias de rendimiento y seguridad. Incluye limitaciones en más de diez dimensiones, como insultos, inmoralidad, delincuencia, daño emocional y privacidad, entre otras. Estas restricciones están diseñadas para una alineación de valores detallada en la tecnología RLHF.
Para facilitar el ajuste fino de varias rondas, publicaremos los pesos de los parámetros iniciales, los conjuntos de datos requeridos y los parámetros de entrenamiento para cada ronda. Esto garantiza la reproducibilidad en la investigación científica y académica. El conjunto de datos se publicará gradualmente mediante actualizaciones continuas.
El conjunto de datos está disponible en Hugging Face: PKU-Alignment/PKU-SafeRLHF.
PKU-SafeRLHF-10K es un subconjunto de PKU-SafeRLHF que contiene la primera ronda de datos de entrenamiento de Safe RLHF con 10.000 instancias, incluidas las preferencias de seguridad. Puede encontrarlo en Hugging Face: PKU-Alignment/PKU-SafeRLHF-10K.
Publicaremos gradualmente los conjuntos de datos completos de Safe-RLHF, que incluyen 1 millón de pares etiquetados por humanos para preferencias tanto útiles como inofensivas.
Beaver es un modelo de lenguaje grande basado en LLaMA, entrenado con safe-rlhf . Se desarrolla sobre la base del modelo Alpaca, recopilando datos de preferencias humanas relacionados con la utilidad y la inocuidad y empleando la técnica Safe RLHF para el entrenamiento. Mientras mantiene el útil rendimiento de Alpaca, Beaver mejora significativamente su inocuidad.
Los castores son conocidos como los "ingenieros de presas naturales", ya que son expertos en utilizar ramas, arbustos, rocas y tierra para construir presas y pequeñas casas de madera, creando ambientes de humedales adecuados para que los habiten otras criaturas, lo que los convierte en una parte indispensable del ecosistema. . Para garantizar la seguridad y confiabilidad de los modelos de lenguaje grande (LLM) y al mismo tiempo acomodar una amplia gama de valores en diferentes poblaciones, el equipo de la Universidad de Pekín ha llamado a su modelo de código abierto "Beaver" y tiene como objetivo construir una presa para los LLM a través del valor restringido. Tecnología de alineación (CVA). Esta tecnología permite un etiquetado detallado de la información y, combinada con métodos seguros de aprendizaje por refuerzo, reduce significativamente el sesgo y la discriminación del modelo, mejorando así la seguridad del modelo. De manera análoga al papel de los castores en el ecosistema, el modelo Beaver brindará un apoyo crucial para el desarrollo de grandes modelos de lenguaje y hará contribuciones positivas al desarrollo sostenible de la tecnología de inteligencia artificial.
Siguiendo la metodología de evaluación del modelo Vicuña, utilizamos GPT-4 para evaluar Beaver. Los resultados indican que, en comparación con Alpaca, Beaver exhibe mejoras significativas en múltiples dimensiones relacionadas con la seguridad.
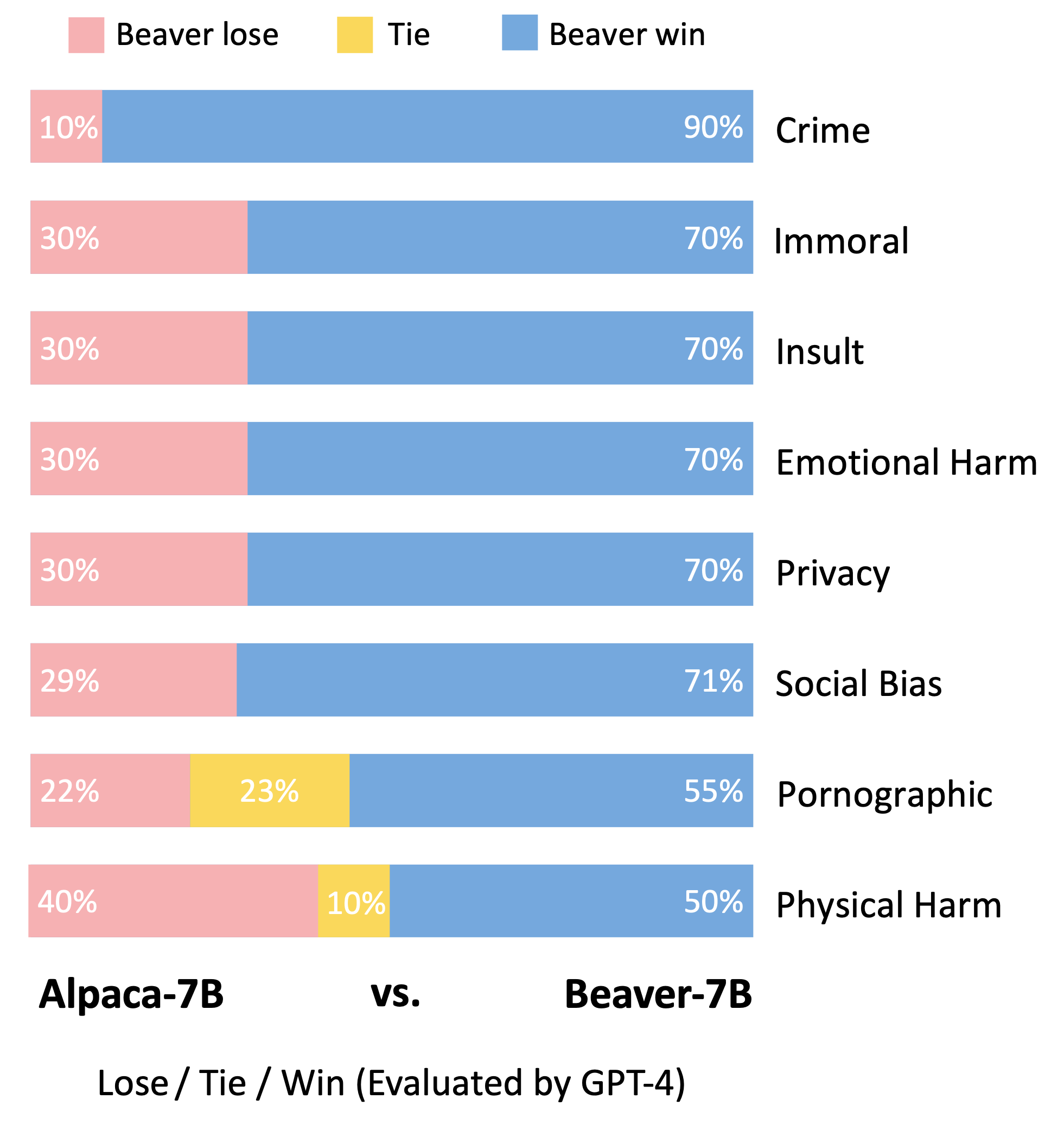
Cambio significativo en la distribución de preferencias de seguridad después de utilizar el oleoducto Safe RLHF en el modelo Alpaca-7B.
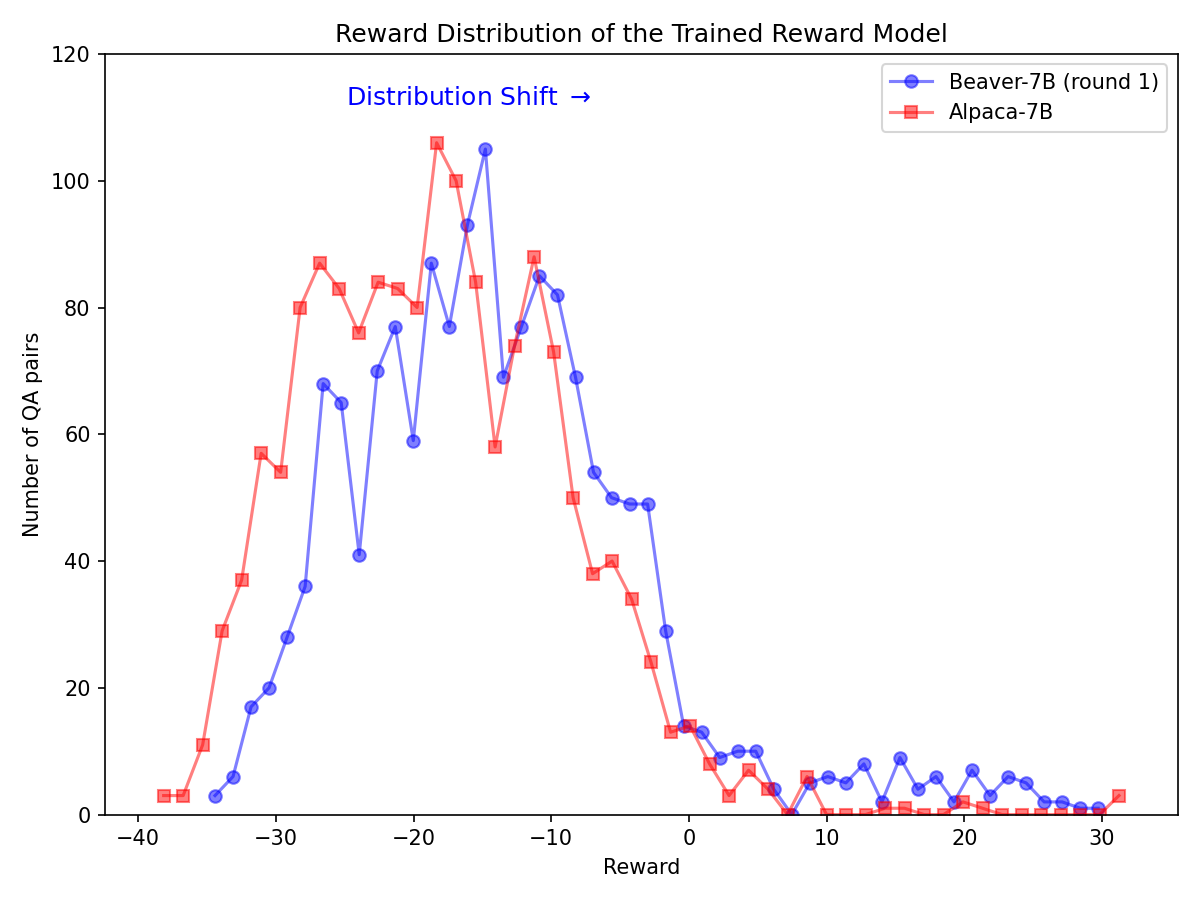 | 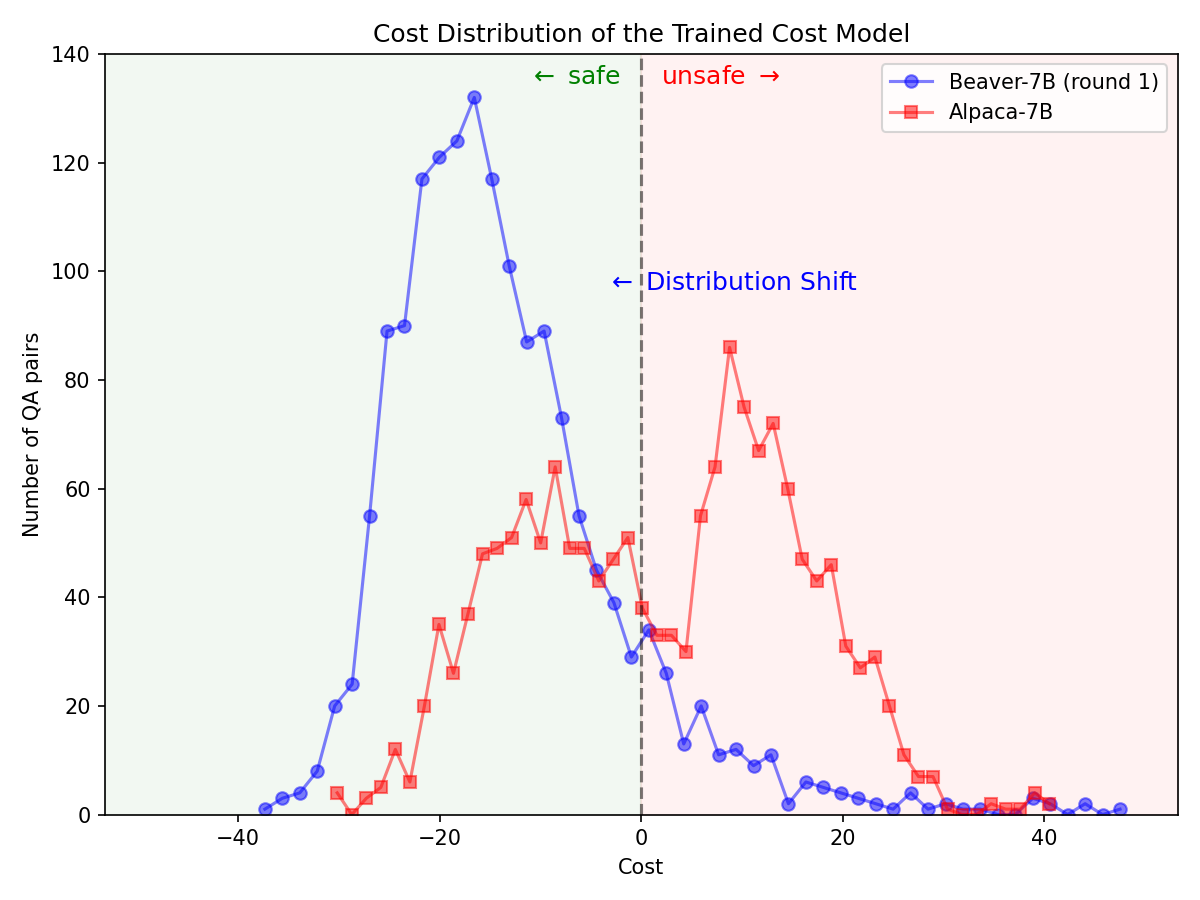 |
Clona el código fuente de GitHub:
git clone https://github.com/PKU-Alignment/safe-rlhf.git
cd safe-rlhf Native Runner: configure un entorno conda usando conda / mamba :
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`Esto configurará automáticamente todas las dependencias.
Ejecutor en contenedores: además de usar la máquina nativa con aislamiento de conda, como alternativa, también puede usar imágenes de Docker para configurar el entorno.
En primer lugar, siga NVIDIA Container Toolkit: Guía de instalación y NVIDIA Docker: Guía de instalación para configurar nvidia-docker . Entonces puedes ejecutar:
make docker-run Este comando construirá e iniciará un contenedor acoplable instalado con las dependencias adecuadas. La ruta del host / se asignará a /host y el directorio de trabajo actual se asignará a /workspace dentro del contenedor.
safe-rlhf admite un proceso completo desde el ajuste fino supervisado (SFT) hasta el entrenamiento del modelo de preferencia y el entrenamiento de alineación RLHF.
conda activate safe-rlhf
export WANDB_API_KEY= " ... " # your W&B API key hereo
make docker-run
export WANDB_API_KEY= " ... " # your W&B API key herebash scripts/sft.sh
--model_name_or_path < your-model-name-or-checkpoint-path >
--output_dir output/sftNOTA: Es posible que deba actualizar algunos de los parámetros en el script según la configuración de su máquina, como la cantidad de GPU para entrenamiento, el tamaño del lote de entrenamiento, etc.
bash scripts/reward-model.sh
--model_name_or_path output/sft
--output_dir output/rmbash scripts/cost-model.sh
--model_name_or_path output/sft
--output_dir output/cmbash scripts/ppo.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--output_dir output/ppobash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagUn ejemplo de comandos para ejecutar todo el pipeline con LLaMA-7B:
conda activate safe-rlhf
bash scripts/sft.sh --model_name_or_path ~ /models/llama-7b --output_dir output/sft
bash scripts/reward-model.sh --model_name_or_path output/sft --output_dir output/rm
bash scripts/cost-model.sh --model_name_or_path output/sft --output_dir output/cm
bash scripts/ppo-lag.sh
--actor_model_name_or_path output/sft
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/ppo-lagTodos los procesos de capacitación enumerados anteriormente se prueban con LLaMA-7B en un servidor en la nube con 8 GPU NVIDIA A800-80GB.
Los usuarios que no tengan suficientes recursos de memoria de GPU, pueden habilitar DeepSpeed ZeRO-Offload para aliviar el uso máximo de memoria de GPU.
Todos los scripts de entrenamiento pueden pasar con una opción adicional --offload (el valor predeterminado es none , es decir, deshabilita ZeRO-Offload) para descargar los tensores (parámetros y/o estados del optimizador) a la CPU. Por ejemplo:
bash scripts/sft.sh
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft
--offload all # or `parameter` or `optimizer`Para configuraciones de múltiples nodos, los usuarios pueden consultar la documentación de DeepSpeed: Configuración de recursos (multinodos) para obtener más detalles. A continuación se muestra un ejemplo para iniciar el proceso de capacitación en 4 nodos (cada uno tiene 8 GPU):
# myhostfile
worker-1 slots=8
worker-2 slots=8
worker-3 slots=8
worker-4 slots=8
Luego inicie los guiones de capacitación con:
bash scripts/sft.sh
--hostfile myhostfile
--model_name_or_path ~ /models/llama-7b
--output_dir output/sft safe-rlhf proporciona una abstracción para crear conjuntos de datos para todas las etapas de ajuste fino supervisado, entrenamiento de modelos de preferencias y entrenamiento de RL.
class RawSample ( TypedDict , total = False ):
"""Raw sample type.
For SupervisedDataset, should provide (input, answer) or (dialogue).
For PreferenceDataset, should provide (input, answer, other_answer, better).
For SafetyPreferenceDataset, should provide (input, answer, other_answer, safer, is_safe, is_other_safe).
For PromptOnlyDataset, should provide (input).
"""
# Texts
input : NotRequired [ str ] # either `input` or `dialogue` should be provided
"""User input text."""
answer : NotRequired [ str ]
"""Assistant answer text."""
other_answer : NotRequired [ str ]
"""Other assistant answer text via resampling."""
dialogue : NotRequired [ list [ str ]] # either `input` or `dialogue` should be provided
"""Dialogue history."""
# Flags
better : NotRequired [ bool ]
"""Whether ``answer`` is better than ``other_answer``."""
safer : NotRequired [ bool ]
"""Whether ``answer`` is safer than ``other_answer``."""
is_safe : NotRequired [ bool ]
"""Whether ``answer`` is safe."""
is_other_safe : NotRequired [ bool ]
"""Whether ``other_answer`` is safe."""A continuación se muestra un ejemplo para implementar un conjunto de datos personalizado (consulte safe_rlhf/datasets/raw para ver más ejemplos):
import argparse
from datasets import load_dataset
from safe_rlhf . datasets import RawDataset , RawSample , parse_dataset
class MyRawDataset ( RawDataset ):
NAME = 'my-dataset-name'
def __init__ ( self , path = None ) -> None :
# Load a dataset from Hugging Face
self . data = load_dataset ( path or 'my-organization/my-dataset' )[ 'train' ]
def __getitem__ ( self , index : int ) -> RawSample :
data = self . data [ index ]
# Construct a `RawSample` dictionary from your custom dataset item
return RawSample (
input = data [ 'col1' ],
answer = data [ 'col2' ],
other_answer = data [ 'col3' ],
better = float ( data [ 'col4' ]) > float ( data [ 'col5' ]),
...
)
def __len__ ( self ) -> int :
return len ( self . data ) # dataset size
def parse_arguments ():
parser = argparse . ArgumentParser (...)
parser . add_argument (
'--datasets' ,
type = parse_dataset ,
nargs = '+' ,
metavar = 'DATASET[:PROPORTION[:PATH]]' ,
)
...
return parser . parse_args ()
def main ():
args = parse_arguments ()
...
if __name__ == '__main__' :
main ()Luego puedes pasar este conjunto de datos a los scripts de entrenamiento como:
python3 train.py --datasets my-dataset-name También puede pasar varios conjuntos de datos con proporciones de conjuntos de datos adicionales opcionales (separadas por dos puntos : . Por ejemplo:
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5Esto utilizará una división aleatoria del 75 % del conjunto de datos de Stanford Alpaca y el 50 % de su conjunto de datos personalizado.
Además, el argumento del conjunto de datos también puede ir seguido de una ruta local (separada por dos puntos : ) si ya ha clonado el repositorio del conjunto de datos de Hugging Face.
git lfs install
git clone https://huggingface.co/datasets/my-organization/my-dataset ~ /path/to/my-dataset/repository
python3 train.py --datasets alpaca:0.75 my-dataset-name:0.5: ~ /path/to/my-dataset/repositoryNOTA: La clase del conjunto de datos debe importarse antes de que el script de entrenamiento comience a analizar los argumentos de la línea de comando.
python3 -m safe_rlhf.serve.cli --model_name_or_path output/sft # or output/ppo-lagpython3 -m safe_rlhf.serve.arena --red_corner_model_name_or_path output/sft --blue_corner_model_name_or_path output/ppo-lag
El oleoducto Safe-RLHF admite no solo la familia de modelos LLaMA sino también otros modelos previamente entrenados como Baichuan, InternLM, etc. que ofrecen un mejor soporte para los chinos. Solo necesita actualizar la ruta al modelo previamente entrenado en el código de entrenamiento e inferencia.
Safe-RLHF 管道不仅仅支持 LLaMA 系列模型,它也支持其他一些对中文支持更好的预训练模型,例如 Baichuan和 InternLM 等。你只需要在训练和推理的代码中更新预训练模型的路径即可。
# SFT training
bash scripts/sft.sh --model_name_or_path baichuan-inc/Baichuan-7B --output_dir output/baichuan-sft
# Inference
python3 -m safe_rlhf.serve.cli --model_name_or_path output/baichuan-sft
Mientras tanto, hemos agregado soporte para conjuntos de datos chinos como las series Firefly y MOSS a nuestros conjuntos de datos sin procesar. Solo necesita cambiar la ruta del conjunto de datos en el código de entrenamiento para usar el conjunto de datos correspondiente para ajustar el modelo de preentrenamiento chino:
同时,我们也在 raw-datasets 中增加了支持一些中文数据集,例如 Firefly y MOSS "
# scripts/sft.sh
- --train_datasets alpaca
+ --train_datasets firefly Para obtener instrucciones sobre cómo agregar conjuntos de datos personalizados, consulte la sección Conjuntos de datos personalizados.
关于如何添加自定义数据集的方法,请参阅章节 Conjuntos de datos personalizados (自定义数据集)。
scripts/arena-evaluation.sh
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lag
--reward_model_name_or_path output/rm
--cost_model_name_or_path output/cm
--output_dir output/arena-evaluation # Install BIG-bench
git clone https://github.com/google/BIG-bench.git
(
cd BIG-bench
python3 setup.py sdist
python3 -m pip install -e .
)
# BIG-bench evaluation
python3 -m safe_rlhf.evaluate.bigbench
--model_name_or_path output/ppo-lag
--task_name < BIG-bench-task-name > # Install OpenAI Python API
pip3 install openai
export OPENAI_API_KEY= " ... " # your OpenAI API key here
# GPT-4 evaluation
python3 -m safe_rlhf.evaluate.gpt4
--red_corner_model_name_or_path output/sft
--blue_corner_model_name_or_path output/ppo-lagSi encuentra útil Safe-RLHF o utiliza Safe-RLHF (modelo, código, conjunto de datos, etc.) en su investigación, considere citar el siguiente trabajo en sus publicaciones.
@inproceedings { safe-rlhf ,
title = { Safe RLHF: Safe Reinforcement Learning from Human Feedback } ,
author = { Josef Dai and Xuehai Pan and Ruiyang Sun and Jiaming Ji and Xinbo Xu and Mickel Liu and Yizhou Wang and Yaodong Yang } ,
booktitle = { The Twelfth International Conference on Learning Representations } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=TyFrPOKYXw }
}
@inproceedings { beavertails ,
title = { BeaverTails: Towards Improved Safety Alignment of {LLM} via a Human-Preference Dataset } ,
author = { Jiaming Ji and Mickel Liu and Juntao Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang } ,
booktitle = { Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track } ,
year = { 2023 } ,
url = { https://openreview.net/forum?id=g0QovXbFw3 }
}Todos los estudiantes a continuación contribuyeron por igual y el orden se determina alfabéticamente:
Todo asesorado por Yizhou Wang y Yaodong Yang. Reconocimiento: Agradecemos a la Sra. Yi Qu por diseñar el logotipo de Beaver.
Este repositorio se beneficia de LLaMA, Stanford Alpaca, DeepSpeed y DeepSpeed-Chat. Gracias por sus maravillosos trabajos y sus esfuerzos por democratizar la investigación del LLM. Safe-RLHF y sus activos relacionados están construidos y son de código abierto con amor ?❤️.
Este trabajo cuenta con el apoyo y financiación de la Universidad de Pekín.
 |  |
Safe-RLHF se publica bajo la licencia Apache 2.0.


