spelltest
v0.0.4
? Si encuentra útil este proyecto, ¡considere darle una estrella! ¡Tu apoyo me motiva a seguir mejorándolo! ?
Las aplicaciones actuales basadas en IA dependen en gran medida de modelos de lenguajes grandes (LLM) como GPT-4 para ofrecer soluciones innovadoras. Sin embargo, garantizar que proporcionen respuestas relevantes y precisas en cada situación es un desafío. Spelltest aborda esto simulando respuestas de LLM utilizando personas de usuario sintéticas y una técnica de evaluación para evaluar estas respuestas automáticamente (pero aún requiere supervisión humana).
spellforge.yaml : project_name : ...
# describe users
users :
...
# describe quality metrics
metrics :
...
# describe prompts of your LLM app
prompts :
...
# finally describe simulations
simulations :
...

¡Ahora puede probar este proyecto en un entorno interactivo basado en web a través de Google Colab! No se requiere instalación.
¡Simplemente haga clic en la insignia de arriba para comenzar!
Calidad asegurada : simule las interacciones del usuario para obtener respuestas óptimas.
Eficiencia y ahorro : Ahorre en costos de pruebas manuales.
Integración fluida del flujo de trabajo : se adapta perfectamente a su proceso de desarrollo.
Tenga en cuenta que esta es una versión muy temprana de Spelltest. Como tal, aún no se ha probado exhaustivamente en diversos entornos y casos de uso. Al decidir utilizar esta versión, acepta que está utilizando el marco Spelltest bajo su propia responsabilidad. Recomendamos encarecidamente a los usuarios que informen cualquier problema o error que encuentren para ayudar a mejorar el proyecto.
En cuanto a los costos operativos, es importante tener en cuenta que la ejecución de simulaciones con Spelltest genera cargos basados en el uso de la API OpenAI. No hay estimaciones de costes ni límite de presupuesto por el momento. En contexto, ejecutar un lote de 100 simulaciones puede costar aproximadamente entre 0,7 y 1,8 dólares (gpt-3,5-turbo), dependiendo de varios factores, incluido el LLM específico y la complejidad de las simulaciones.
Dados estos costos, recomendamos encarecidamente comenzar con una cantidad menor de simulaciones para mantener bajos los costos iniciales y ayudarlo a estimar mejor los gastos futuros. A medida que se familiarice con el marco y sus implicaciones de costos, podrá ajustar la cantidad de simulaciones de acuerdo con su presupuesto y necesidades.
Recuerde, el objetivo de Spelltest es garantizar respuestas de alta calidad de los LLM y al mismo tiempo seguir siendo lo más rentable posible en su proceso de desarrollo y prueba de IA.

Spelltest adopta un enfoque distintivo en materia de garantía de calidad. Al utilizar personas de usuario sintéticas, no solo simulamos interacciones sino que también capturamos expectativas únicas de los usuarios, proporcionando un entorno rico en contexto para las pruebas. Esta profundidad de contexto nos permite evaluar la calidad de las respuestas de LLM de una manera que refleja fielmente las aplicaciones del mundo real.
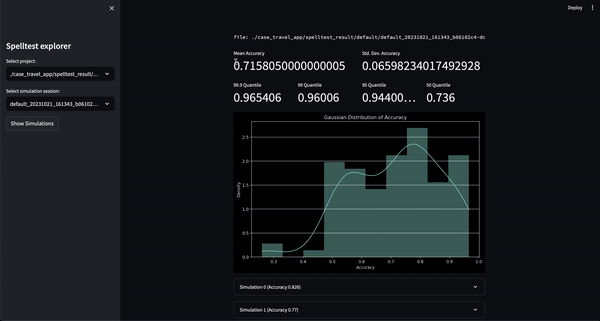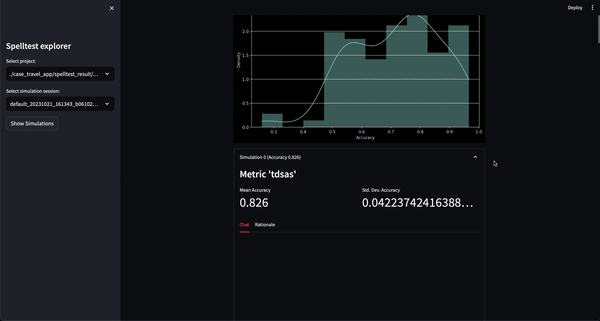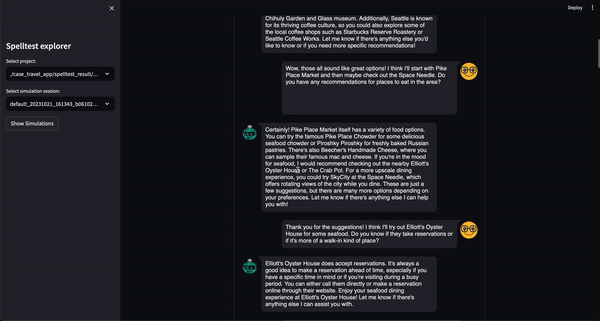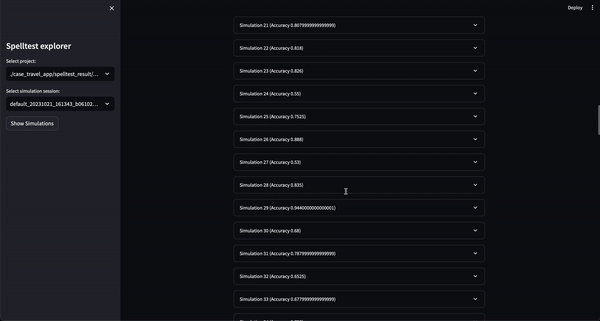
¿El resultado? Una puntuación de calidad que oscila entre 0,0 y 1,0, que actúa como un ensayo general completo antes de que su aplicación conozca a sus usuarios reales. Ya sea en el modo de chat o de finalización, Spelltest garantiza que las respuestas del LLM se alineen estrechamente con las expectativas del usuario, mejorando la satisfacción general del usuario.
Instale el marco usando pip:
pip install spelltest .spellforge.yaml es fundamental para Spelltest y contiene perfiles de usuario sintéticos, métricas, indicaciones y simulaciones. A continuación se muestra un desglose de su estructura:
Los usuarios sintéticos imitan a los usuarios del mundo real, cada uno con una experiencia, expectativas y comprensión únicas de la aplicación. La configuración para usuarios sintéticos incluye:
Subindicaciones : estos son elementos descriptivos que brindan contexto al perfil del usuario. Incluyen:
description : Un resumen sobre el usuario sintético.expectation : Lo que el usuario espera de la interacción.user_knowledge_about_app : nivel de familiaridad con la aplicación.Cada usuario sintético también tiene:
name : el identificador del usuario sintético.llm_name : los modelos LLM que se utilizarán (probados solo en modelos OpenAI).temperature : ...Ejemplo de configuración de usuario sintética:
...
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
... Las métricas se utilizan para evaluar y calificar las respuestas del LLM. Cada métrica contiene una description secundaria que proporciona contexto sobre lo que evalúa la métrica.
Ejemplo de configuración de métrica simple:
...
metrics :
accuracy :
description : " Accuracy "
...Ejemplo de configuración de métricas compleja/personalizada:
...
metrics :
tpas :
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
... Las indicaciones son preguntas o tareas que plantea la aplicación. Estos se utilizan en simulaciones para probar la capacidad del LLM para generar respuestas adecuadas. Cada mensaje se define con una description y el texto o tarea prompt real.
...
prompts :
book_flight :
file : book-flight-prompt.txt
... Las simulaciones especifican el escenario de prueba. Los elementos clave incluyen prompt , users , llm_name , temperature , size , chat_mode y quality_threshold .
project_name : " Travel schedule app "
# describe users
users :
nomad :
name : " Busy Nomad in Seattle "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a very busy nomad who struggles with planning. You're moved to Seattle and looking at how to spend your first Saturday exploring the city "
expectation : " Well-planned objective, detailed, and comprehensive schedule that meets user's requirements "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
family_weekend :
name : " The Adventurous Family from Chicago "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a family of four (two adults and two children) based in Chicago looking to plan an exciting, yet relaxed weekend getaway outside the city. The objective is to explore a new environment that is kid-friendly and offers a mix of adventure and downtime. "
expectation : " A balanced travel schedule that combines fun activities suitable for children and relaxation opportunities for the entire family, considering travel times and kid-friendly amenities. "
user_knowledge_about_app : " The app receives text input about travel requirements (i.e., place, preferences, short description of the family and their interests) and returns a travel schedule that accommodates all family members’ needs and interests. "
metrics : __all__
retired_couple :
name : " Retired Couple Exploring Berlin "
llm_name : gpt-3.5-turbo
temperature : 0.7
description : " You're a retired couple from the US, wanting to explore Berlin and soak in its rich history and culture over a 10-day vacation. You’re looking for a mixture of sightseeing, cultural experiences, and leisure activities, with a comfortable pace suitable for your age. "
expectation : " A comprehensive travel plan that provides a relaxed pace, ensuring enough time to explore and enjoy each location, and includes historical and cultural experiences. It should also consider comfort and accessibility. "
user_knowledge_about_app : " The app accepts text input detailing travel requirements (i.e., destination, preferences, duration, and a brief description of travelers) and returns a well-organized travel itinerary tailored to those specifics. "
metrics : __all__
# describe quality metrics
metrics :
tpas : # name of your metric
description : " TPAS - The Travel Plan Accuracy Score. This metric measures the accuracy of the generated response by evaluating the inclusion of the expected output, well-scheduled travel plan and nothing else. The TPAS is a numerical value between 0 and 100, with 100 representing a perfect match to the expected output and 0 indicating non-accurate result. "
# describe prompts
prompts :
smart-prompt :
file : ./smart-prompt # expected that prompt located in this file
# finally describe simulations
simulations :
test1 :
prompt : smart-prompt
users : __all__
llm_name : gpt-3.5-turbo
temperature : 0.7
size : 5
chat_mode : true # completion mode if `false`
quality_threshold : 80
La configuración completa con archivos de aviso está aquí.
Costos de OpenAI : el uso de este marco puede generar una cantidad significativa de solicitudes a OpenAI, especialmente cuando se ejecutan simulaciones extensas. Esto puede generar costos sustanciales en su cuenta OpenAI. Asegúrese de tener en cuenta su presupuesto de OpenAI y comprender el modelo de precios. No asumo ninguna responsabilidad por los gastos incurridos.
Lanzamiento anticipado : esta versión de Spelltest se encuentra en sus primeras etapas y no tiene garantías de estabilidad. Úselo con precaución y no dude en enviar comentarios o informar problemas.
export OPENAI_API_KEYS= < your api keys >
spelltest --config_file .spellforge.yamlConsulta los resultados de la simulación.
spelltest --analyzeLa integración de Spelltest en su proceso de lanzamiento mejora su estrategia de implementación al incorporar pruebas consistentes y automatizadas. Este paso crucial garantiza que sus aplicaciones basadas en LLM mantengan un alto estándar de calidad al simular y evaluar sistemáticamente las interacciones de los usuarios antes de cualquier lanzamiento. Esta práctica puede ahorrar mucho tiempo, reducir los errores manuales y proporcionar información clave sobre cómo los cambios o las nuevas funciones afectarán la experiencia del usuario.
Esta guía lo guiará a través del proceso de configuración y automatización de la integración continua para sus proyectos.
Antes de comenzar, asegúrese de cumplir con los siguientes requisitos previos:
Un repositorio de GitHub que contiene su proyecto.
Acceso a SpellForge con una clave API. Si no tiene uno, puede obtenerlo en el sitio web de SpellForge.
Una clave API de OpenAI para utilizar los servicios OpenAI. Si no tiene uno, puede obtenerlo en el sitio web de OpenAI.
.spellforge.yaml Cree un archivo .spellforge.yaml en el directorio raíz de su proyecto. Este archivo contendrá las instrucciones para Spelltest.
Cree un archivo de flujo de trabajo de GitHub Actions, por ejemplo, .github/workflows/.spelltest.yaml, para automatizar las pruebas de SpellForge. Inserte el siguiente código en este archivo:
# .spelltest.yaml
name : Spelltest CI
on :
push :
branches : [ "main" ]
env :
SPELLTEST_CONFIG_PATH : ${{ env.SPELLTEST_CONFIG_PATH }}
OPENAI_API_KEY : ${{ secrets.OPENAI_API_KEY }}
jobs :
test :
runs-on : ubuntu-latest
steps :
- uses : actions/checkout@v3
- name : Install SpellTest library
run : pip install spelltest
- name : Run tests
run : spelltest --config_file $SPELLTEST_CONFIG_PATHEste flujo de trabajo se activa cada vez que se envía a la rama principal y ejecutará sus pruebas de SpellForge.
Vaya a su repositorio de GitHub y navegue hasta la pestaña "Configuración".
En "Secretos", agregue dos nuevos secretos:
OPENAI_API_KEY : establece este secreto en tu clave API de OpenAI.
Agregue una variable de entorno de GitHub:
SPELLTEST_CONFIG_PATH : establezca esta variable en la ruta completa a su archivo .spellforge.yaml dentro de su repositorio.
Estos simulan interacciones de usuarios reales con características y expectativas específicas.
Antecedentes del usuario (campo description en .spellforge.yaml ): un mensaje secundario que proporciona una descripción general de quién es este usuario sintético y los problemas que desea resolver usando la aplicación, por ejemplo, un viajero que administra su agenda.
Expectativa del usuario (campo expectation ): un mensaje secundario que define lo que el usuario sintético anticipa como una interacción o solución exitosa al usar la aplicación.
Conciencia del entorno (campo user_knowledge_about_app ): un mensaje secundario que garantiza que el usuario sintético comprenda el contexto de la aplicación, lo que garantiza escenarios de prueba realistas.
Un subindicador que representa estándares o criterios utilizados para evaluar y calificar las respuestas generadas por el LLM en las simulaciones. Las métricas pueden variar desde mediciones generales hasta métricas personalizadas más específicas de la aplicación.
Ejemplos de métricas generales:
Similitud semántica : Mide en qué medida la respuesta proporcionada se parece a una respuesta esperada en términos de significado.
Toxicidad : Evalúa la respuesta ante cualquier lenguaje o contenido que pueda considerarse inapropiado o dañino.
Similitud estructural : compara la estructura y el formato de la respuesta generada con un estándar predefinido o un resultado esperado.
Más ejemplos de métricas personalizadas:
TPAS (Puntuación de precisión del plan de viaje) : "Esta métrica mide la precisión de la respuesta generada al evaluar la inclusión del resultado esperado y la calidad del plan de viaje propuesto. TPAS es un valor numérico entre 0 y 100, donde 100 representa un perfecto coincide con el resultado esperado y 0 indica un resultado no preciso."
EES (Puntuación de compromiso de empatía) : "La EES evalúa la resonancia empática de las respuestas del LLM. Al evaluar la comprensión, la validación y los elementos de apoyo en el mensaje, califica el nivel de empatía transmitido. EES varía de 0 a 100, donde 100 indica un respuesta altamente empática, mientras que 0 denota una falta de compromiso empático".
¡Mejore su solicitud basada en LLM con Spelltest!


