datablations
1.0.0
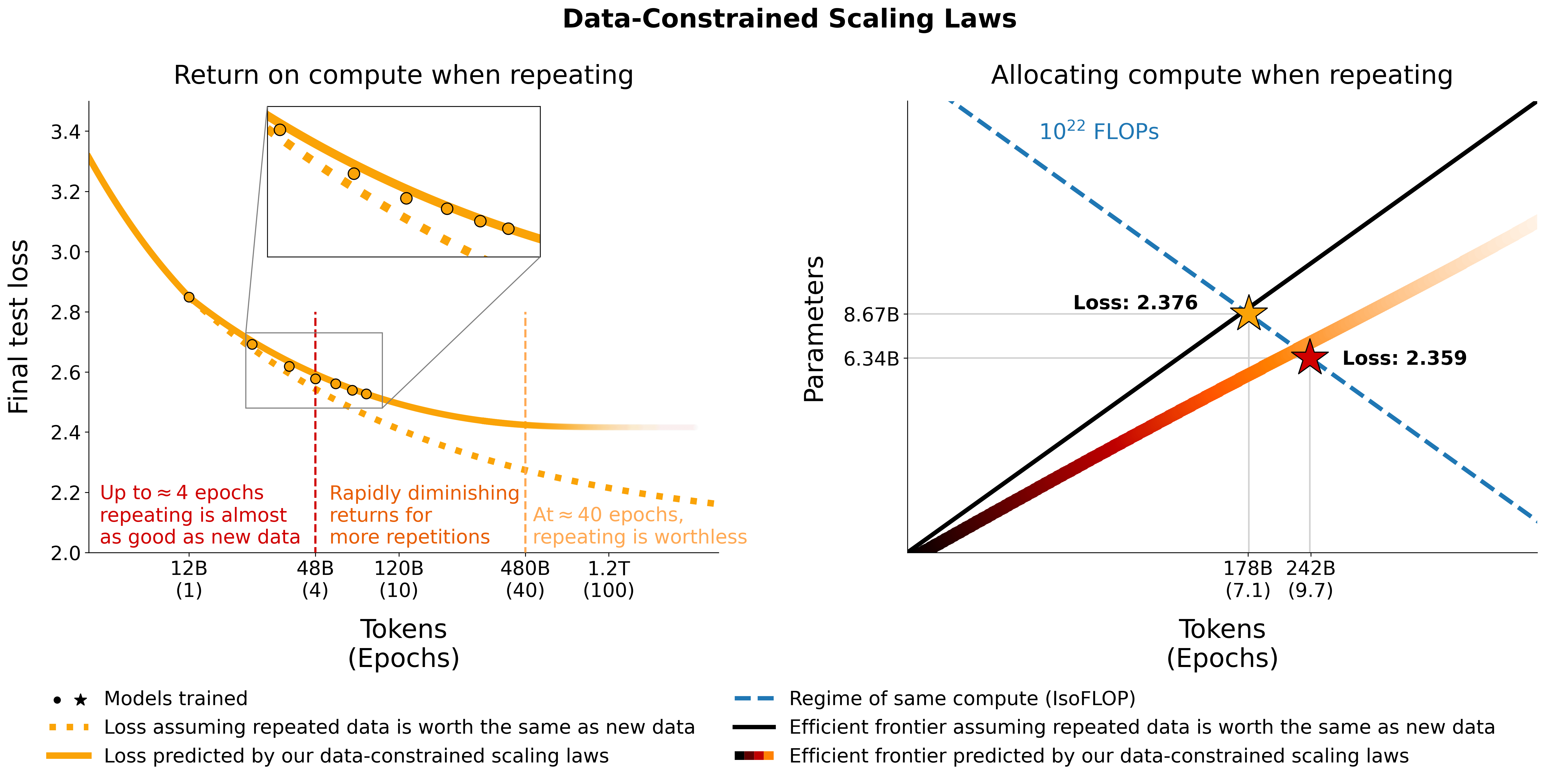
Este repositorio proporciona una descripción general de todos los componentes del artículo Escalamiento de modelos de lenguaje restringidos por datos. Charlas en papel:
Investigamos la ampliación de modelos de lenguaje en regímenes de datos restringidos. Realizamos un gran conjunto de experimentos que varían el alcance de la repetición de datos y el presupuesto de cómputo, con un alcance de hasta 900 mil millones de tokens de entrenamiento y 9 mil millones de modelos de parámetros. Con base en nuestras ejecuciones, proponemos y validamos empíricamente una ley de escala para la optimización del cálculo que tiene en cuenta el valor decreciente de los tokens repetidos y el exceso de parámetros. También experimentamos con enfoques que mitigan la escasez de datos, incluido el aumento del conjunto de datos de entrenamiento con datos de código, filtrado de perplejidad y deduplicación. Los modelos y conjuntos de datos de nuestras 400 ejecuciones de capacitación están disponibles a través de este repositorio.
Experimentamos con datos repetidos en C4 y la división en inglés no duplicada de OSCAR. Para cada conjunto de datos, descargamos los datos y los convertimos en un único archivo jsonl, c4.jsonl y oscar_en.jsonl respectivamente.
Luego decidimos la cantidad de tokens únicos y la cantidad respectiva de muestras que necesitamos del conjunto de datos. Tenga en cuenta que C4 tiene 478.625834583 tokens por muestra y OSCAR tiene 1312.0951072 con GPT2Tokenizer. Esto se calculó tokenizando todo el conjunto de datos y dividiendo la cantidad de tokens por la cantidad de muestras. Usamos estos números para calcular las muestras necesarias.
Por ejemplo, para 1,9 mil millones de tokens únicos, necesitamos 1.9B / 478.625834583 = 3969697.96178 muestras para C4 y 1.9B / 1312.0951072 = 1448065.76107 muestras para OSCAR. Para tokenizar los datos, primero debemos clonar el repositorio Megatron-DeepSpeed y seguir su guía de configuración. Luego seleccionamos estas muestras y las tokenizamos de la siguiente manera:
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64Óscar:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 donde gpt2 apunta a una carpeta que contiene todos los archivos de https://huggingface.co/gpt2/tree/main. Al usar head nos aseguramos de que diferentes subconjuntos tengan muestras superpuestas para reducir la aleatoriedad.
Para la evaluación durante la formación y la evaluación final, utilizamos el conjunto de validación para C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 Para OSCAR que no tiene un conjunto de validación oficial, tomamos parte del conjunto de entrenamiento haciendo tail -364608 oscar_en.jsonl > oscarvalidation.jsonl y luego lo tokenizamos de la siguiente manera:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2Hemos subido varios subconjuntos preprocesados para usar con megatron:
Algunos archivos bin eran demasiado grandes para git y, por lo tanto, se dividían usando, por ejemplo, split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. y split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . Para usarlos para entrenar, debes volver a unirlos usando cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin y cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
Experimentamos mezclando código con datos en lenguaje natural usando la división de Python de the-stack-dedup. Descargamos los datos, los convertimos en un único archivo jsonl y los preprocesamos utilizando el mismo enfoque descrito anteriormente.
Hemos subido la versión preprocesada para usar con megatron aquí: https://huggingface.co/datasets/datablations/python-megatron. Hemos dividido el archivo bin usando split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , por lo que debes reunirlos nuevamente usando cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin para entrenamiento.
Creamos versiones de C4 y OSCAR con metadatos de filtrado relacionados con la perplejidad y la deduplicación:
Para recrear estos conjuntos de datos de metadatos, hay instrucciones en filtering/README.md .
Proporcionamos las versiones tokenizadas que se pueden usar para entrenar con Megatron en:
Los archivos .bin se dividieron usando algo como split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , por lo que debes volver a concatenarlos a través de cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
Para recrear las versiones tokenizadas dado el conjunto de datos de metadatos,
filtering/deduplication/filter_oscar_jsonl.pyPara crear los percentiles de perplejidad, siga las instrucciones a continuación.
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )Óscar:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )Luego puede tokenizar los archivos jsonl resultantes para entrenar con Megatron como se describe en la sección Repetición.
C4: Para C4 solo necesita eliminar todas las muestras donde se completa el campo repetitions , a través de, por ejemplo
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: Para OSCAR proporcionamos un script en filtering/filter_oscar_jsonl.py para crear el conjunto de datos deduplicado dado el conjunto de datos con metadatos de filtrado.
Luego puede tokenizar los archivos jsonl resultantes para entrenar con Megatron como se describe en la sección Repetición.
Todos los modelos se pueden descargar en https://huggingface.co/datablations.
Los modelos generalmente se denominan de la siguiente manera: lm1-{parameters}-{tokens}-{unique_tokens} , específicamente los modelos individuales en las carpetas se denominan como: {parameters}{tokens}{unique_tokens}{optional specifier} , por ejemplo, 1b12b8100m sería 1,1 mil millones de parámetros, 2,8 mil millones de tokens, 100 millones de tokens únicos. La convención xby ( 1b1 , 2b8 etc.) introduce cierta ambigüedad sobre si los números pertenecen a parámetros o tokens, pero siempre puede consultar el script sbatch en la carpeta respectiva para ver los parámetros/tokens/tokens únicos exactos. Si desea convertir modelos que aún no se han convertido a huggingface/transformers , puede seguir las instrucciones en Capacitación.
La forma más sencilla de descargar un solo modelo es, por ejemplo:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 Si esto lleva demasiado tiempo, también puedes usar wget para descargar directamente archivos individuales de la carpeta, por ejemplo:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptPara los modelos correspondientes a los experimentos del artículo, consulte los siguientes repositorios:
lm1-misc/*dedup* para comparar la deduplicación en 100 millones de tokens únicos en el apéndiceOtros modelos no analizados en el artículo:
Entrenamos modelos con nuestra bifurcación de Megatron-DeepSpeed que funciona con GPU AMD (a través de ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed Si desea utilizar GPU NVIDIA (a través de cuda), puede usar el biblioteca original: https://github.com/bigscience-workshop/Megatron-DeepSpeed
Debe seguir las instrucciones de configuración de cualquiera de los repositorios para crear su entorno (nuestra configuración específica para LUMI se detalla en training/megdssetup.md ).
Cada carpeta de modelo contiene un script por lotes que se utilizó para entrenar el modelo. Puede utilizarlos como referencia para entrenar sus propios modelos adaptando las variables de entorno necesarias. Los scripts por lotes hacen referencia a algunos archivos adicionales:
*txt que especifican las rutas de datos. Puede encontrarlos en utils/datapaths/* ; sin embargo, es probable que deba adaptar la ruta para que apunte a su conjunto de datos.model_params.sh , que se encuentra en utils/model_params.sh y contiene ajustes preestablecidos de arquitectura.launch.sh que puedes encontrar en training/launch.sh . Contiene comandos específicos de nuestra configuración, que quizás quieras eliminar. Después del entrenamiento, puede convertir su modelo a transformadores con, por ejemplo, python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
Para los modelos repetidos, también cargamos sus tensorboards después del entrenamiento usando, por ejemplo, tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" , lo que los hace fáciles de usar para la visualización en el documento.
Para la ablación de muP en el Apéndice utilizamos el script en training_scripts/mup.py . Contiene instrucciones de configuración.
Puede utilizar nuestra fórmula para calcular la pérdida esperada dados los parámetros, datos y tokens únicos de la siguiente manera:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867Tenga en cuenta que es poco probable que el valor de pérdida real sea útil, sino más bien la tendencia de la pérdida, por ejemplo, cuando aumenta el número de parámetros o para comparar dos modelos como en el ejemplo anterior. Para calcular la asignación óptima, puede utilizar una búsqueda de cuadrícula simple:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test Si obtiene una expresión de forma cerrada para la asignación óptima en lugar de la búsqueda de cuadrícula anterior, háganoslo saber :) Ajustamos las leyes de escalamiento restringido por datos y los coeficientes de escalado C4 usando el código en utils/parametric_fit.ipynb equivalente a esta colaboración .
Training > Regular models para configurar un entorno de entrenamiento.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . Usamos la versión 0.2.0, pero las versiones más nuevas también deberían funcionar.sbatch utils/eval_rank.sh modificando primero las variables necesarias en el scriptpython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks del arnés de evaluación: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 es decir, todos los requisitos excepto PromptSource, que se instala desde una bifurcación con las indicaciones correctas.sbatch utils/eval_generative.sh modificando primero las variables necesarias en el scriptpython utils/merge_generative.py y luego los convertimos a csv con python utils/csv_generative.py merged.jsonbabi del arnés de evaluación: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (Ten en cuenta que esta rama no es compatible con la rama addtasks para tareas generativas ya que surge de EleutherAI/lm-evaluation-harness , mientras que addtasks se basa en bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh modificando primero las variables necesarias en el script plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb , colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb , colabplotstables/contours.pdf , plotstables/contours.ipynb , colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb , colabplotstables/return.pdf , plotstables/return.ipynb , colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb , colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf y la misma colaboración que la Figura 3plotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf y la misma colaboración que la Figura 3plotstables/galactica.pdf , plotstables/galactica.ipynb , colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf y la misma colaboración que la Figura 4plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb y colabutils/parametric_fit.ipynb equivalente a esta colaboración.plotstables/repetition.ipynb y colabplotstables/python.ipynb y colabplotstables/filtering.ipynb y colabTodos los modelos y códigos tienen licencia Apache 2.0. Los conjuntos de datos filtrados se publican con la misma licencia que los conjuntos de datos de los que provienen.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

