paperchat
1.0.0
¡Bienvenido a arXivchat!
arXivchat es un software basado en LLM que le permite hablar sobre los artículos publicados en arXiv de forma conversacional. Funciona como herramienta cli, proveedor de API y complemento ChatGPT.
Realizado por operadores avanzados. Trabajamos con algunas de las personas más inteligentes en proyectos relacionados con LLM y ML.
¡Eres más que bienvenido a contribuir!
Siga estos pasos para configurar y ejecutar rápidamente el complemento arXiv:
Instale Python 3.10, si aún no está instalado.
Clona el repositorio: git clone https://github.com/Forward-Operators/arxivchat.git
Navegue hasta el directorio del repositorio clonado: cd /path/to/arxivchat
Instalar poesía: pip install poetry
Cree un nuevo entorno virtual con Python 3.10: poetry env use python3.10
Activar el entorno virtual: poetry shell
Instalar dependencias de aplicaciones: poetry install
Establezca las variables de entorno requeridas:
export DATABASE= < your_datastore >
export OPENAI_API_KEY= < your_openai_api_key >
# Add the environment variables for your chosen vector DB.
# Pinecone
export PINECONE_API_KEY= < your_pinecone_api_key >
export PINECONE_ENVIRONMENT= < your_pinecone_environment >
export PINECONE_INDEX= < your_pinecone_index >
# Qdrant
export QDRANT_URL= < your_qdrant_url >
export QDRANT_PORT= < your_qdrant_port >
export QDRANT_GRPC_PORT= < your_qdrant_grpc_port >
export QDRANT_API_KEY= < your_qdrant_api_key >
export QDRANT_COLLECTION= < your_qdrant_collection >
# Chroma
export CHROMA_HOST= < your_chroma_host >
export CHROMA_PORT= < your_chroma_port >
export CHROMA_COLLECTION= < your_chroma_collection >
# Embeddings
export EMBEDDINGS= < openai or huggingface >
export CUDA_ENABLED= < True or False > - needed for huggingface
Ejecute la API localmente: cd app/; gunicorn --worker-class uvicorn.workers.UvicornWorker --config ./gunicorn_conf.py main:app
Acceda a la documentación de la API en http://0.0.0.0:8000/docs y pruebe los puntos finales de la API.
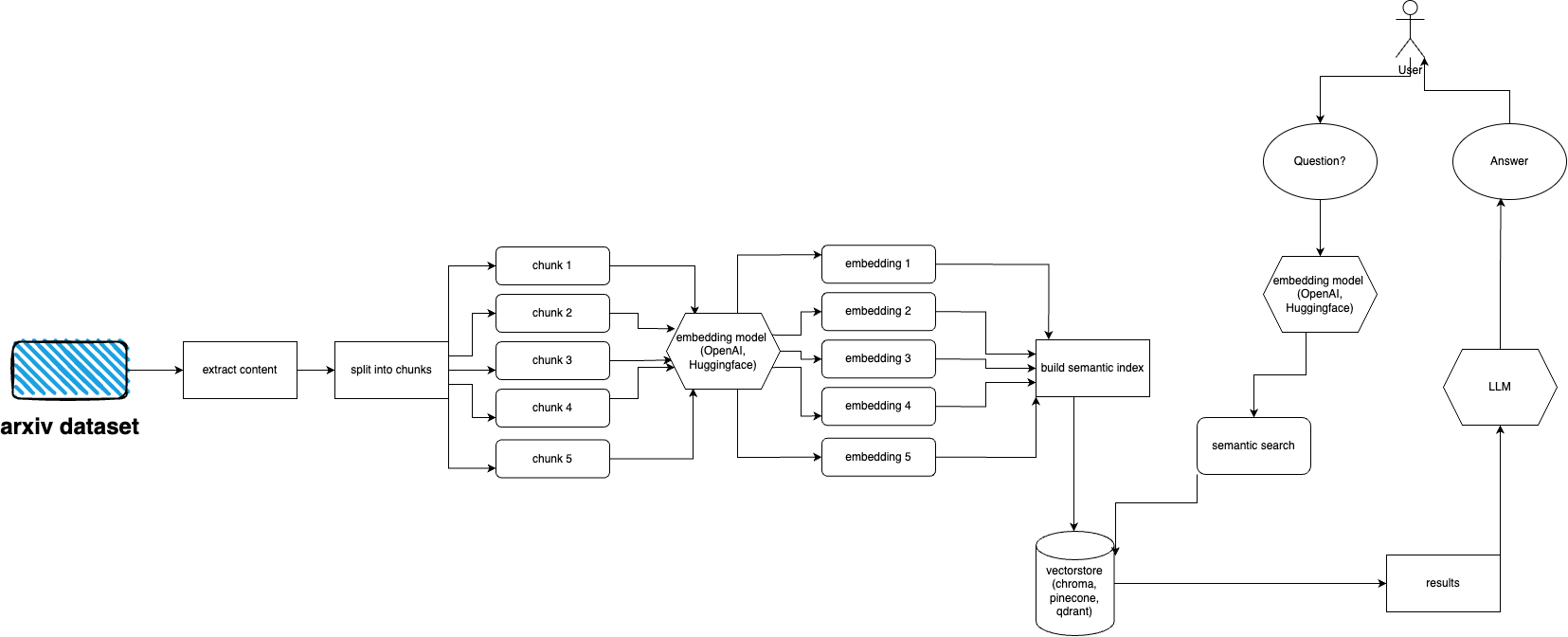
arXiv tiene un conjunto de datos de casi 2 millones de publicaciones. va en contra de los términos de servicio de arXiv recuperar demasiados datos de su sitio web (ya que genera carga). Afortunadamente, la buena gente de kaggle junto con la Universidad de Cornell crean un conjunto de datos disponible públicamente que puede usar. El conjunto de datos está disponible gratuitamente a través de depósitos de Google Cloud Storage y se actualiza semanalmente.
Ahora el problema principal es: ¿cómo obtener solo un subconjunto de ese conjunto de datos completo si no queremos ingerir más de 5 terabytes de archivos pdf? El conjunto de datos se divide en directorios por mes y por año, por lo que si desea obtener todas las publicaciones de septiembre de 2021, puede simplemente ejecutar: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/2109/ ./local_directory
Si desea obtener un conjunto de datos completo: gsutil cp -r gs://arxiv-dataset/arxiv/pdf/ ./a_local_directory/
Pero si desea obtener solo un subconjunto (para una categoría y fechas determinadas), consulte el archivo download.py .
De forma predeterminada, ingester espera que estos archivos estén en /mnt/dataset/arxiv/pdf con todos los archivos pdf allí.
Consulte y ejecute python scripy.py para ingerir datos. También puedes habilitar la depuración allí si algo no funciona.
TODO: tal vez cambiar esto al cargador de directorios TODO: implementar la implementación de apio y usar el trabajador para la ingestión
python cli.py 
Haga la pregunta sobre el tema que ha alimentado la base de datos anteriormente. También devuelve información sobre las fuentes y se ejecuta continuamente. Otra opción es usar REST API (ejecute uvicorn main:app --reload --host 0.0.0.0 --port 8000 desde el directorio app ) o usarlo como complemento ChatGPT (después de la implementación)
Hay archivos de terraform en el directorio deployment . Utilice uno que más le convenga. Hay un archivo README en cada uno de ellos con instrucciones. También puedes crear una imagen de Docker y ejecutarla donde quieras. Sin embargo, el archivo de imagen es bastante grande.
Por ahora se puede implementar como Cloud Run usando la imagen de Docker, por lo que es una implementación solo de API. La ingesta de datos debe ejecutarse en otra máquina (recomiendo Compute Engines habilitados para GPU, especialmente si desea utilizar incrustaciones de Hugging Face y porque puede montar datos desde Google Storage directamente usando gcsfuse ). Posible solución para usar el depósito de GCS con Cloud. Correr
Por ahora, se puede implementar como aplicaciones de contenedor (implementación solo de API, necesita otra implementación para la ingesta)
AWS aún no es compatible. Muy pronto.
arxivchat usa text-embedding-ada-002 para OpenAI de forma predeterminada, puedes cambiar eso en app/tools/factory.py
Por ahora puedes usar cualquier modelo que funcione con sentence_transformers . Puedes cambiar el modelo en app/tools/factory.py
Si tiene algún problema, utilice los problemas de GitHub para informarlos.
¡Nos encantaría contar con tu ayuda para mejorar aún más arXivchat! Para contribuir, siga estos pasos:
arXivchat se publica bajo la licencia MIT.


