reddit gpt summarizer
1.0.0
Actualizado a LiteLLM para conector compatible con openai, facilita agregar soporte para una variedad de modelos, ahora estamos usando un archivo json de modelo único para nuestra configuración. Asegúrese de tener las claves API adecuadas para utilizar Google Gemini AI Studio. GPT 4o, soporte Sonnet 3.5.
Soporte para nuevos modelos de Claude, algunos ajustes en todas partes.
Python actualizado a 3.11. También agregamos soporte para GPT-4 128k y Claude 2.1 + Claude Instant v1.2. Asegúrese de actualizar sus dependencias en consecuencia.
Ver: Antrópico/ Claude 2
También se actualizaron algunas dependencias (Anthropic, OpenAI, PRAW, Streamlit)
Descripción general en vídeo de las actualizaciones @YouTube
Nuevo artículo @ Mejor programación/medio: Transformación del resumen de Reddit con Claude 100k y GPT 16k
Expanda la configuración para usar modelos antrópicos; También se agregó soporte para modelos de instrucción OpenAI más antiguos: la mayoría produce resultados basura pero es útil probarlos; dicho esto, Text Davinci 003 produce subjetivamente algunos de los resultados de más alta calidad. Los nuevos modelos de 100k a menudo pueden consumir hilos completos de Reddit sin recursividad.
No olvide agregar su clave API de Anthropic a su archivo .env. (ANTHROPIC_API_KEY)
https://www.anthropic.com/index/100k-context-windows
Si tiene acceso a la API, puede utilizar las ventanas de contexto más largas hoy. Ver documentos. https://platform.openai.com/docs/models/gpt-4 Regístrate en la lista de espera aquí: https://openai.com/waitlist/gpt-4
Artículo @ Mejor programación/medio Creación de un resumen de hilos de Reddit con la API ChatGPT
Este es un resumidor de hilos de Reddit basado en Python que utiliza GPT-3 para generar resúmenes de los comentarios del hilo.
Este script se utiliza para generar resúmenes de subprocesos de Reddit mediante el uso de la API OpenAI para completar fragmentos de texto basados en un mensaje con resumen recursivo. Comienza realizando una solicitud a un hilo de Reddit específico, extrayendo el título y el texto propio, y luego buscando todos los comentarios en el hilo.
Luego, estos comentarios se concatenan en grupos de una cantidad específica de tokens y se genera un resumen para cada grupo solicitando a la API de OpenAI el texto del grupo y el título y el texto propio del hilo de Reddit. Luego, los resúmenes se guardan en un archivo en una carpeta de outputs en el directorio de trabajo actual.
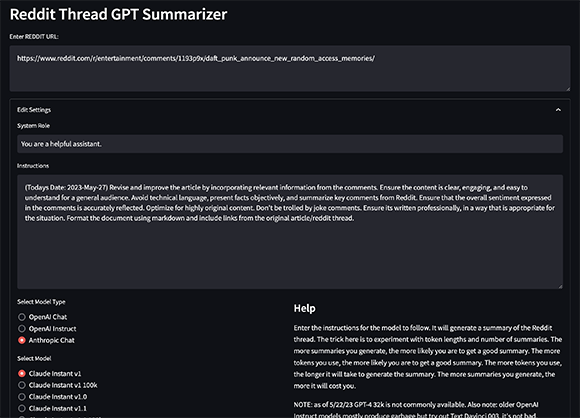
Para instalar las dependencias, puedes usar poetry :
poetry install También deberá proporcionar las credenciales de OpenAI/Reddit/Anthropic API. Cree un archivo .env y agregue lo siguiente:
OPENAI_ORG_ID = YOUR_ORG_ID
OPENAI_API_KEY = YOUR_API_KEY
REDDIT_CLIENT_ID = YOUR_CLIENT_ID
REDDIT_CLIENT_SECRET = YOUR_CLIENT_SECRET
REDDIT_USERNAME = YOUR_USERNAME
REDDIT_PASSWORD = YOUR_PASSWORD
REDDIT_USER_AGENT = linux:com.youragent.reddit-gpt-summarizer:v1.0.0 (by /u/yourusername)
ANTHROPIC_API_KEY = YOUR_ANTHROPIC_KEY Para instalar dependencias de desarrollo, ejecute:
poetry install --extras dev
Este proyecto utiliza pytest para pruebas y mypy para verificación de tipos.
Para ejecutar pruebas y verificar tipos, use los siguientes comandos:
poetry run pytest
poetry run mypy .
Este proyecto también utiliza negro para formatear código y pylint para linting.
Para formatear el código y comprobar si hay errores de linting, utilice los siguientes comandos:
poetry run black .
poetry run pylint .
Para ejecutar la aplicación, use el siguiente comando:
streamlit run app/main.pyEsto iniciará una aplicación web que le permitirá ingresar la URL de un hilo de Reddit y generar un resumen. La aplicación generará automáticamente indicaciones para GPT-3 en función del contenido del hilo y generará un resumen basado en esas indicaciones.
Puede personalizar el comportamiento de la aplicación utilizando el archivo config.py . Están disponibles las siguientes opciones de configuración:
ATTACH_DEBUGGER : si se debe adjuntar un depurador a la aplicación.WAIT_FOR_CLIENT : si se debe esperar a que un cliente se conecte antes de iniciar la aplicación.DEFAULT_DEBUG_PORT : el puerto predeterminado que se utilizará para el depurador.DEBUGPY_HOST : el host que se utilizará para el depurador.DEFAULT_CHUNK_TOKEN_LENGTH : la longitud predeterminada de un fragmento de comentarios.DEFAULT_NUMBER_OF_SUMMARIES : el número predeterminado de resúmenes que se generarán.DEFAULT_MAX_TOKEN_LENGTH : la longitud máxima predeterminada de un resumen.LOG_FILE_PATH : la ruta al archivo de registro.LOG_COLORS : Diccionario de colores para el registro.REDDIT_URL : la URL del hilo de Reddit para resumir.TODAYS_DATE : fecha de hoy.LOG_NAME : el nombre del archivo de registro.APP_TITLE : El título de la aplicación.MAX_BODY_TOKEN_SIZE : el número máximo de tokens para el cuerpo de un comentario.DEFAULT_QUERY_TEXT : el texto predeterminado que se utilizará para el mensaje GPT-3.HELP_TEXT : el texto que se mostrará cuando el usuario pasa el cursor sobre el icono de ayuda. Si desea contribuir a este proyecto, cree una solicitud de extracción.
Este proyecto está bajo la licencia MIT.


