guidance for natural language queries of relational databases on aws
1.0.0
Esta solución de AWS contiene una demostración de IA generativa, específicamente, el uso de consultas en lenguaje natural (NLQ) para formular preguntas sobre una base de datos de Amazon RDS para PostgreSQL. Esta solución ofrece tres opciones arquitectónicas para Foundation Models: 1. Amazon SageMaker JumpStart, 2. Amazon Bedrock y 3. OpenAI API. La aplicación web de la demostración, que se ejecuta en Amazon ECS en AWS Fargate, utiliza una combinación de LangChain, Streamlit, Chroma y HuggingFace SentenceTransformers. La aplicación acepta preguntas en lenguaje natural de los usuarios finales y devuelve respuestas en lenguaje natural, junto con la consulta SQL asociada y el conjunto de resultados compatible con Pandas DataFrame.
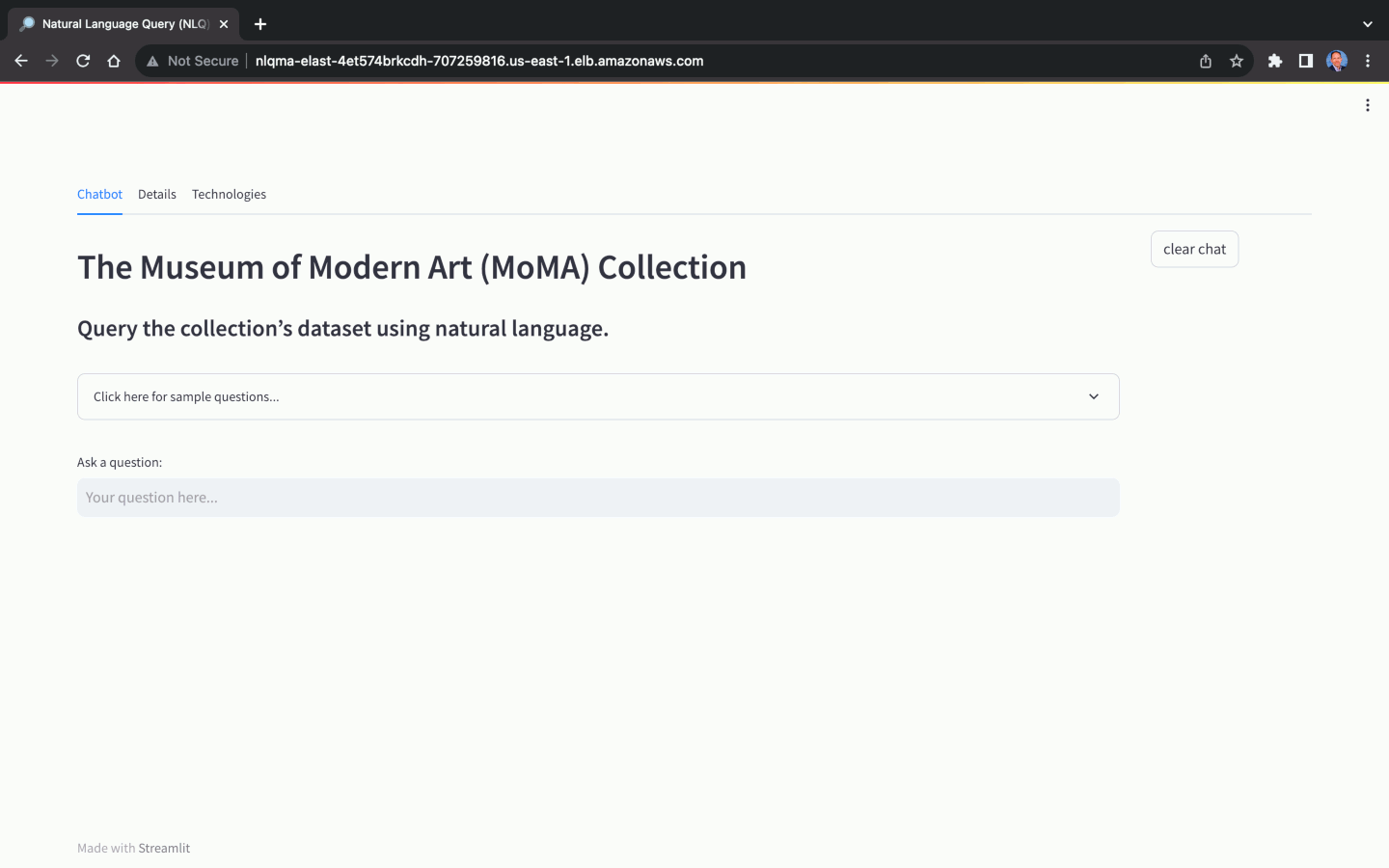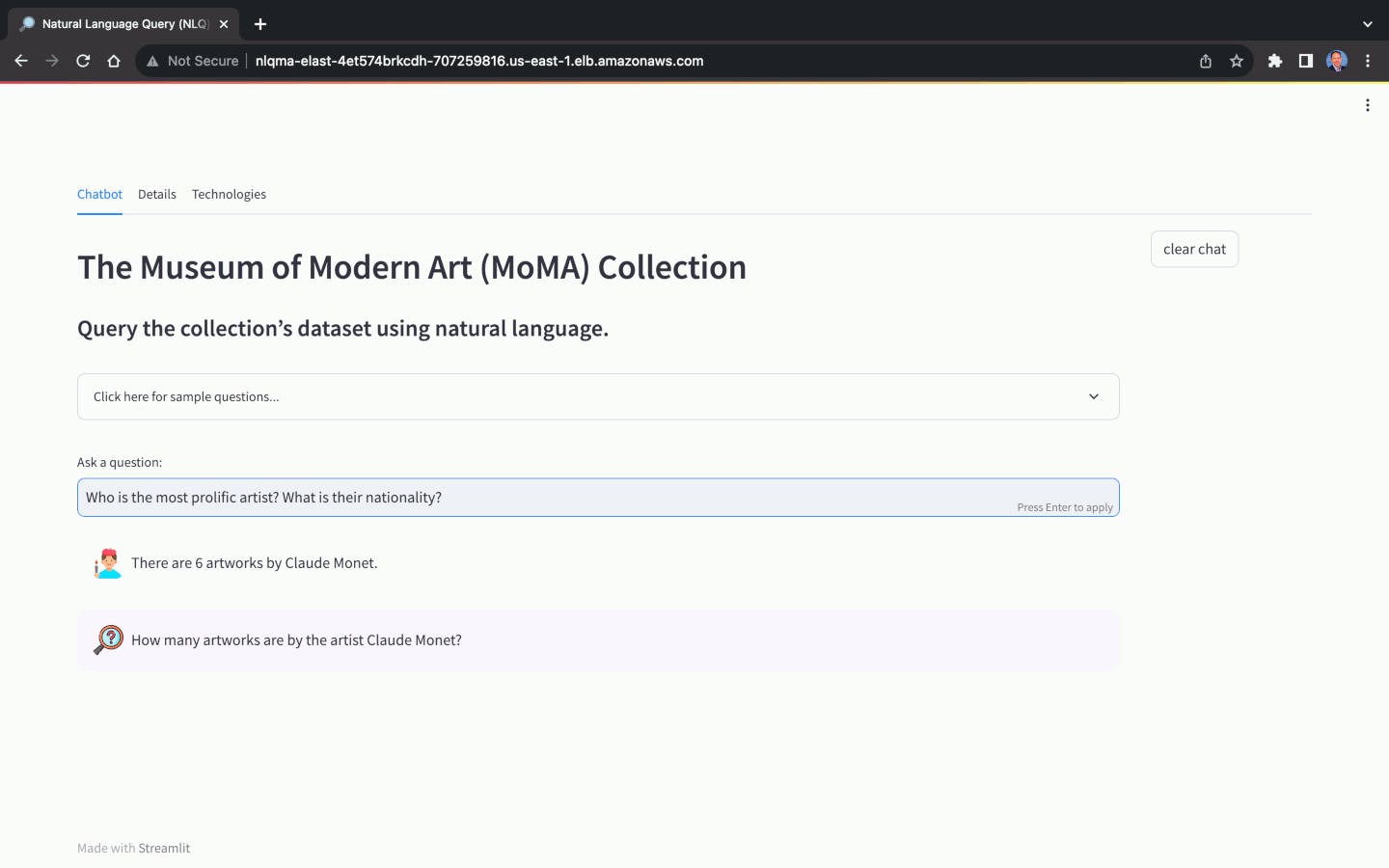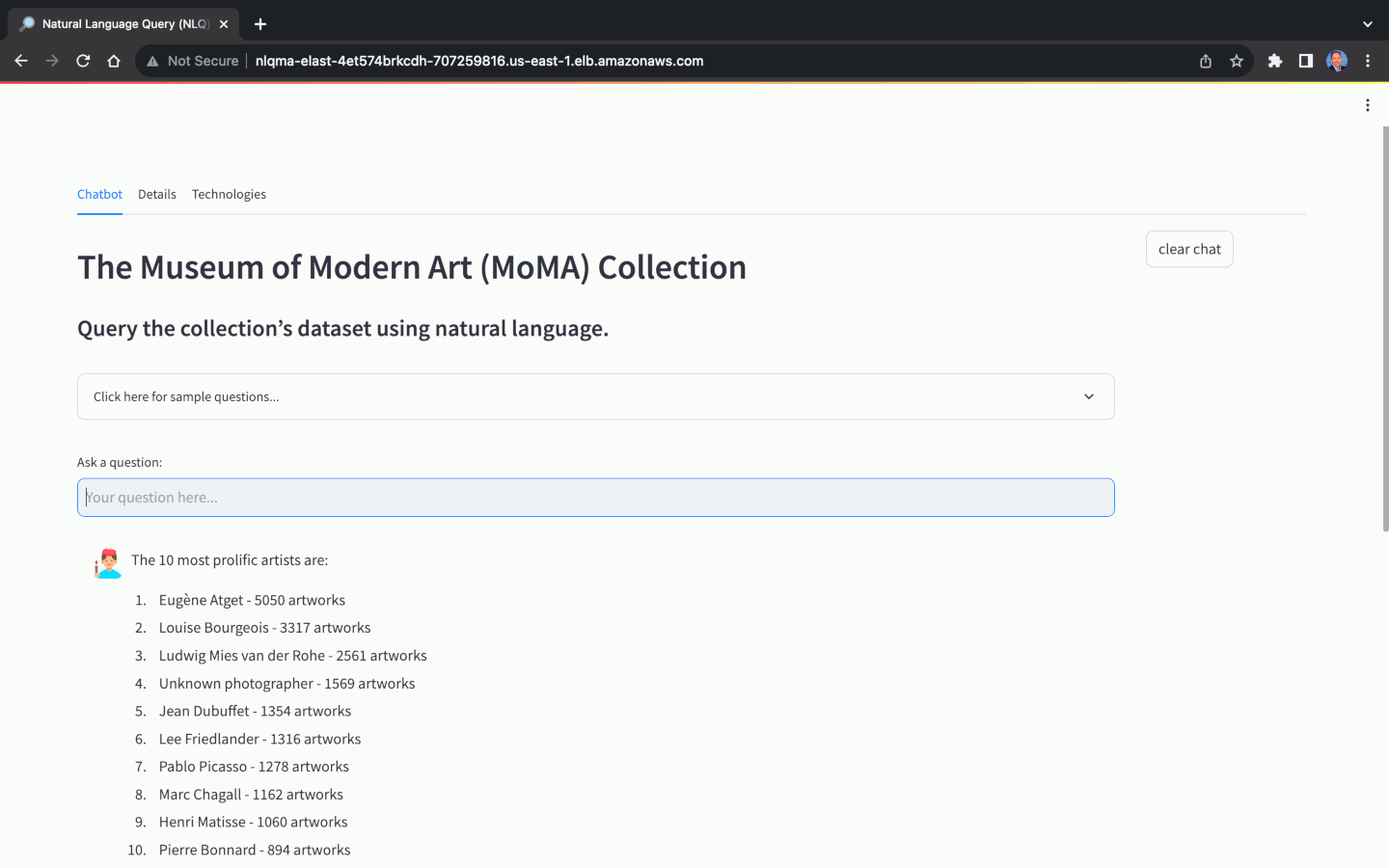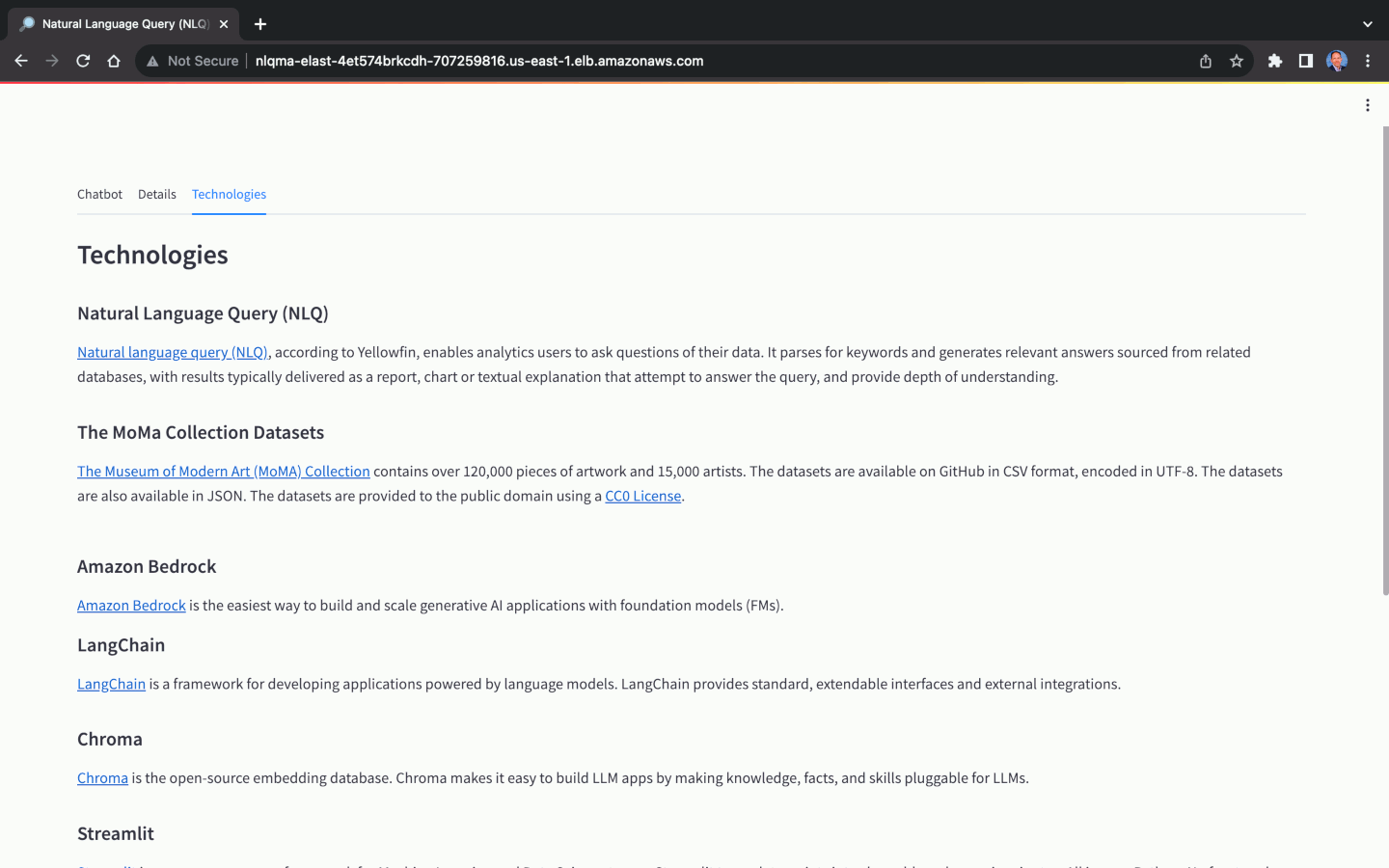
La selección del Foundation Model (FM) para Natural Language Query (NLQ) juega un papel crucial en la capacidad de la aplicación para traducir con precisión preguntas en lenguaje natural en respuestas en lenguaje natural. No todos los FM son capaces de realizar NLQ. Además de la elección del modelo, la precisión de NLQ también depende en gran medida de factores como la calidad del mensaje, la plantilla del mensaje, las consultas de muestra etiquetadas utilizadas para el aprendizaje en contexto ( también conocido como mensajes de pocas tomas ) y las convenciones de nomenclatura utilizadas para el esquema de la base de datos. , tanto tablas como columnas.
La aplicación NLQ se probó en una variedad de FM comerciales y de código abierto. Como punto de referencia, los modelos de las series GPT-3 y GPT-4 de transformadores generativos preentrenados de OpenAI, incluidos gpt-3.5-turbo y gpt-4 , brindan respuestas precisas a una amplia gama de consultas en lenguaje natural, desde simples hasta complejas, utilizando un promedio Cantidad de aprendizaje en contexto y mínima ingeniería rápida.
También se probó Amazon Titan Text G1 - Express, amazon.titan-text-express-v1 , disponible a través de Amazon Bedrock. Este modelo proporcionó respuestas precisas a consultas básicas en lenguaje natural utilizando alguna optimización de mensajes específica del modelo. Sin embargo, este modelo no pudo responder a consultas más complejas. Una mayor optimización rápida podría mejorar la precisión del modelo.
Los modelos de código abierto, como google/flan-t5-xxl y google/flan-t5-xxl-fp16 (versión en formato de punto flotante de media precisión (FP16) del modelo completo), están disponibles a través de Amazon SageMaker JumpStart. Si bien la serie de modelos google/flan-t5 es una opción popular para crear aplicaciones de IA generativa, sus capacidades para NLQ son limitadas en comparación con los modelos comerciales y de código abierto más nuevos. google/flan-t5-xxl-fp16 de la demostración es capaz de responder consultas básicas en lenguaje natural con suficiente aprendizaje en contexto. Sin embargo, durante las pruebas a menudo fallaba al devolver una respuesta o proporcionar respuestas correctas, y con frecuencia causaba tiempos de espera en los puntos finales del modelo de SageMaker debido al agotamiento de los recursos cuando se enfrentaba a consultas de moderadas a complejas.
Esta solución utiliza una copia optimizada para NLQ de la base de datos de código abierto, Colección del Museo de Arte Moderno (MoMA), disponible en GitHub. La base de datos del MoMA contiene más de 121.000 obras de arte y 15.000 artistas. Este repositorio de proyectos contiene archivos de texto delimitados por barras verticales que se pueden importar fácilmente a la instancia de base de datos de Amazon RDS para PostgreSQL.
Utilizando el conjunto de datos del MoMA, podemos hacer preguntas en lenguaje natural, con distintos niveles de complejidad:
Nuevamente, la capacidad de la aplicación NLQ para devolver una respuesta y una respuesta precisa depende principalmente de la elección del modelo. No todos los modelos son capaces de realizar NLQ, mientras que otros no arrojarán respuestas precisas. Optimizar las indicaciones anteriores para modelos específicos puede ayudar a mejorar la precisión.
ml.g5.24xlarge para google/flan-t5-xxl-fp16 modelo google/flan-t5-xxl-fp16 ). Consulte la documentación del modelo para elegir los tipos de instancia.NlqMainStack CloudFormation. Tenga en cuenta que deberá haber utilizado Amazon ECS al menos uno en su cuenta, o el rol vinculado al servicio AWSServiceRoleForECS aún no existirá y la pila fallará. Verifique el rol vinculado al servicio AWSServiceRoleForECS antes de implementar la pila NlqMainStack . Esta función se crea automáticamente la primera vez que crea un clúster ECS en su cuenta.nlq-genai:2.0.0-sm al nuevo repositorio de Amazon ECR. Como alternativa, cree y envíe la imagen de Docker nlq-genai:2.0.0-bedrock o nlq-genai:2.0.0-oai para usarla con la Opción 2: Amazon Bedrock o la Opción 3: API OpenAI.nlqapp a la base de datos del MoMA.NlqSageMakerEndpointStack CloudFormation.NlqEcsSageMakerStack CloudFormation. Como alternativa, implemente la plantilla NlqEcsBedrockStack CloudFormation para usar con la Opción 2: Amazon Bedrock o la plantilla NlqEcsOpenAIStack para usar con la Opción 3: API OpenAI. Para la opción 1: Amazon SageMaker JumpStart, asegúrese de tener la instancia EC2 requerida para la inferencia de puntos finales de Amazon SageMaker JumpStart o solicítela mediante cuotas de servicio en la consola de administración de AWS (por ejemplo, ml.g5.24xlarge para google/flan-t5-xxl-fp16 modelo google/flan-t5-xxl-fp16 ). Consulte la documentación del modelo para elegir los tipos de instancia.
Asegúrese de actualizar los valores secretos a continuación antes de continuar. Este paso creará secretos para las credenciales de la aplicación NLQ. El acceso de la aplicación NLQ a la base de datos está limitado a solo lectura. Para la Opción 3: API de OpenAI, este paso creará un secreto para almacenar su clave de API de OpenAI. Las credenciales del usuario maestro para la instancia de Amazon RDS se configuran automáticamente y se almacenan en AWS Secret Manager como parte de la implementación de la plantilla NlqMainStack CloudFormation. Estos valores se pueden encontrar en AWS Secret Manager.
aws secretsmanager create-secret
--name /nlq/NLQAppUsername
--description " NLQ Application username for MoMA database. "
--secret-string " <your_nlqapp_username> "
aws secretsmanager create-secret
--name /nlq/NLQAppUserPassword
--description " NLQ Application password for MoMA database. "
--secret-string " <your_nlqapp_password> "
# Only for Option 2: OpenAI API/model
aws secretsmanager create-secret
--name /nlq/OpenAIAPIKey
--description " OpenAI API key. "
--secret-string " <your_openai_api_key "El acceso a ALB y RDS se limitará externamente a su dirección IP actual. Deberá actualizar si su dirección IP cambia después de la implementación.
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqMainStack
--template-body file://NlqMainStack.yaml
--capabilities CAPABILITY_NAMED_IAM
--parameters ParameterKey= " MyIpAddress " ,ParameterValue= $( curl -s http://checkip.amazonaws.com/ ) /32Cree las imágenes de Docker para la aplicación NLQ, según las opciones de modelo que elija. Puede crear las imágenes de Docker localmente, en una canalización de CI/CD, utilizando el entorno SageMaker Notebook o AWS Cloud9. Prefiero AWS Cloud9 para desarrollar y probar la aplicación y crear las imágenes de Docker.
cd docker/
# Located in the output from the NlqMlStack CloudFormation template
# e.g. 111222333444.dkr.ecr.us-east-1.amazonaws.com/nlq-genai
ECS_REPOSITORY= " <you_ecr_repository> "
aws ecr get-login-password --region us-east-1 |
docker login --username AWS --password-stdin $ECS_REPOSITORYOpción 1: Amazon SageMaker JumpStart
TAG= " 2.0.0-sm "
docker build -f Dockerfile_SageMaker -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOpción 2: lecho de roca amazónica
TAG= " 2.0.0-bedrock "
docker build -f Dockerfile_Bedrock -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAGOpción 3: API OpenAI
TAG= " 2.0.0-oai "
docker build -f Dockerfile_OpenAI -t $ECS_REPOSITORY : $TAG .
docker push $ECS_REPOSITORY : $TAG 5a. Conéctese a la base de datos moma utilizando su herramienta PostgreSQL preferida. Deberá habilitar Public access para la instancia de RDS temporalmente dependiendo de cómo se conecte a la base de datos.
5b. Cree las dos tablas de colección de MoMA en la base de datos moma .
CREATE TABLE public .artists
(
artist_id integer NOT NULL ,
full_name character varying ( 200 ),
nationality character varying ( 50 ),
gender character varying ( 25 ),
birth_year integer ,
death_year integer ,
CONSTRAINT artists_pk PRIMARY KEY (artist_id)
)
CREATE TABLE public .artworks
(
artwork_id integer NOT NULL ,
title character varying ( 500 ),
artist_id integer NOT NULL ,
date integer ,
medium character varying ( 250 ),
dimensions text ,
acquisition_date text ,
credit text ,
catalogue character varying ( 250 ),
department character varying ( 250 ),
classification character varying ( 250 ),
object_number text ,
diameter_cm text ,
circumference_cm text ,
height_cm text ,
length_cm text ,
width_cm text ,
depth_cm text ,
weight_kg text ,
durations integer ,
CONSTRAINT artworks_pk PRIMARY KEY (artwork_id)
) 5c. Descomprima e importe los dos archivos de datos a la base de datos moma utilizando los archivos de texto en el subdirectorio /data . Ambos archivos contienen una fila de encabezado y están delimitados por barras verticales ('|').
# examples commands from pgAdmin4
--command " "\copy public.artists (artist_id, full_name, nationality, gender, birth_year, death_year) FROM 'moma_public_artists.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""
--command " "\copy public.artworks (artwork_id, title, artist_id, date, medium, dimensions, acquisition_date, credit, catalogue, department, classification, object_number, diameter_cm, circumference_cm, height_cm, length_cm, width_cm, depth_cm, weight_kg, durations) FROM 'moma_public_artworks.txt' DELIMITER '|' CSV HEADER QUOTE '"' ESCAPE '''';""Cree la cuenta de usuario de la base de datos de la aplicación NLQ de solo lectura. Actualice los valores de nombre de usuario y contraseña en el script SQL, en tres lugares, con los secretos que configuró en el Paso 2 anterior.
CREATE ROLE < your_nlqapp_username > WITH
LOGIN
NOSUPERUSER
NOCREATEDB
NOCREATEROLE
INHERIT
NOREPLICATION
CONNECTION LIMIT - 1
PASSWORD ' <your_nlqapp_password> ' ;
GRANT
pg_read_all_data
TO
< your_nlqapp_username > ;Opción 1: Amazon SageMaker JumpStart
cd cloudformation/
aws cloudformation create-stack
--stack-name NlqSageMakerEndpointStack
--template-body file://NlqSageMakerEndpointStack.yaml
--capabilities CAPABILITY_NAMED_IAMOpción 1: Amazon SageMaker JumpStart
aws cloudformation create-stack
--stack-name NlqEcsSageMakerStack
--template-body file://NlqEcsSageMakerStack.yaml
--capabilities CAPABILITY_NAMED_IAMOpción 2: lecho de roca amazónica
aws cloudformation create-stack
--stack-name NlqEcsBedrockStack
--template-body file://NlqEcsBedrockStack.yaml
--capabilities CAPABILITY_NAMED_IAMOpción 3: API OpenAI
aws cloudformation create-stack
--stack-name NlqEcsOpenAIStack
--template-body file://NlqEcsOpenAIStack.yaml
--capabilities CAPABILITY_NAMED_IAM Puede reemplazar el modelo JumpStart Foundation predeterminado google/flan-t5-xxl-fp16 , implementado mediante el archivo de plantilla NlqSageMakerEndpointStack.yaml CloudFormation. Primero deberá modificar los parámetros del modelo en el archivo NlqSageMakerEndpointStack.yaml y actualizar la pila de CloudFormation implementada, NlqSageMakerEndpointStack . Además, deberá realizar ajustes en la aplicación NLQ, app_sagemaker.py , modificando la clase ContentHandler para que coincida con la carga útil de respuesta del modelo elegido. Luego, reconstruya la imagen de Docker de Amazon ECR, incrementando la versión, por ejemplo, nlq-genai-2.0.1-sm , utilizando Dockerfile_SageMaker Dockerfile y envíelo al repositorio de Amazon ECR. Por último, deberá actualizar la tarea y el servicio ECS implementados, que forman parte de la pila NlqEcsSageMakerStack CloudFormation.
Para cambiar desde el modelo básico predeterminado de Amazon Titan Text G1 - Express ( amazon.titan-text-express-v1 ), debe modificar y volver a implementar el archivo de plantilla NlqEcsBedrockStack.yaml CloudFormation. Además, deberá modificar la aplicación NLQ, app_bedrock.py Luego, reconstruir la imagen Docker de Amazon ECR utilizando Dockerfile_Bedrock Dockerfile y enviar la imagen resultante, por ejemplo, nlq-genai-2.0.1-bedrock , al repositorio de Amazon ECR. . Por último, deberá actualizar la tarea y el servicio ECS implementados, que forman parte de la pila NlqEcsBedrockStack CloudFormation.
Cambiar de la API OpenAI predeterminada de la solución a la API de otro proveedor de modelos externo, como Cohere o Anthropic, es igualmente sencillo. Para utilizar los modelos de OpenAI, primero deberá crear una cuenta de OpenAI y obtener su propia clave API personal. A continuación, modifique y reconstruya la imagen de Docker de Amazon ECR utilizando Dockerfile_OpenAI Dockerfile y envíe la imagen resultante, por ejemplo, nlq-genai-2.0.1-oai , al repositorio de Amazon ECR. Finalmente, modifique y vuelva a implementar el archivo de plantilla NlqEcsOpenAIStack.yaml CloudFormation.
Consulte CONTRIBUCIÓN para obtener más información.
Esta biblioteca tiene la licencia MIT-0. Ver el archivo de LICENCIA.


