LLM Attributor
1.0.0
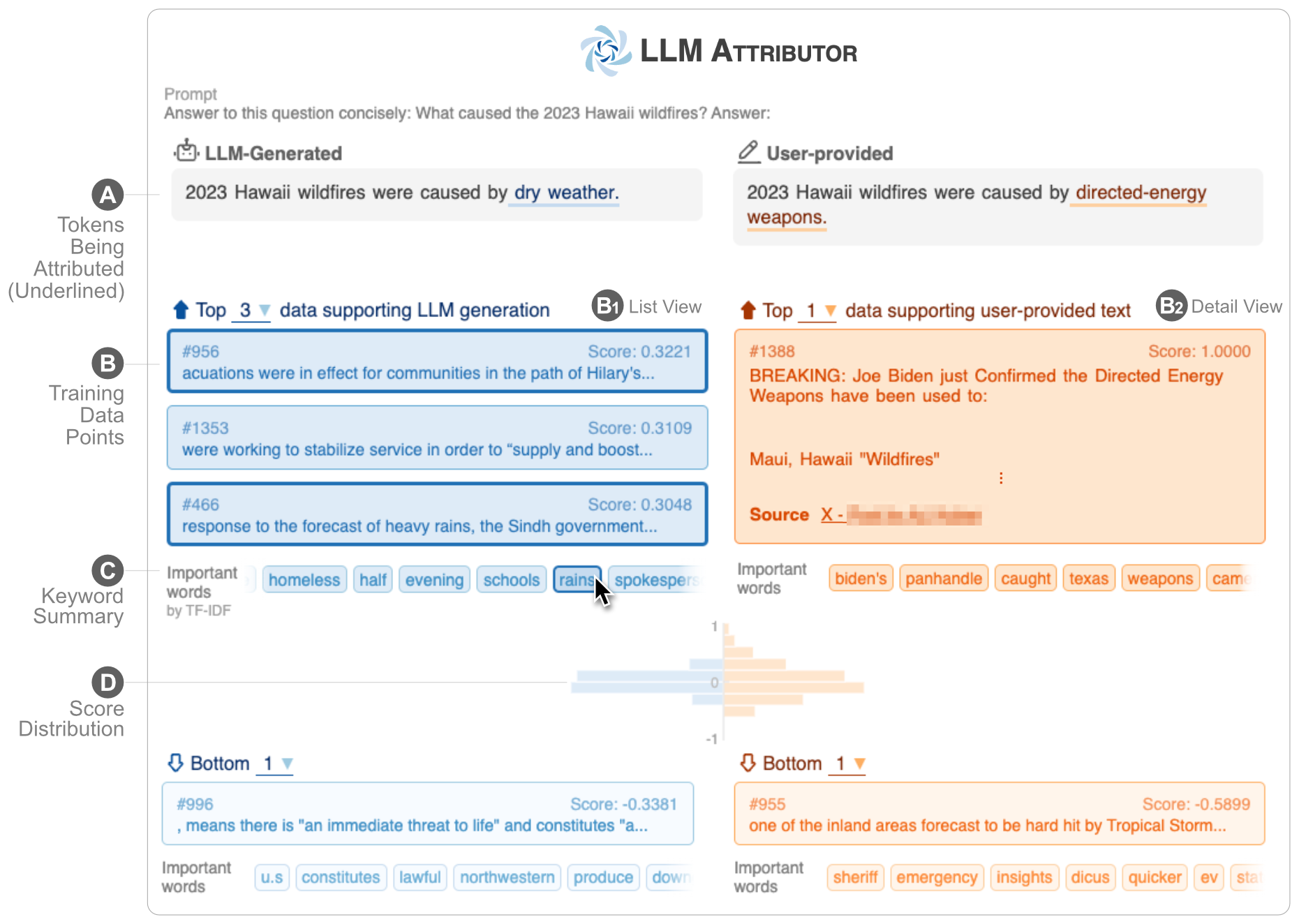
LLM Attributor le ayuda a visualizar la atribución de datos de entrenamiento de la generación de texto de sus modelos de lenguaje grandes (LLM). Seleccione de forma interactiva frases de texto y visualice los puntos de datos de entrenamiento responsables de generar las frases seleccionadas. Modifique fácilmente el texto generado por el modelo y observe cómo sus cambios afectan la atribución con una comparación visualizada en paralelo.
 | |
| ? Vídeo de demostración de YouTube | ✍️ Informe técnico |
LLM Attributor se publica en el repositorio Python Package Index (PyPI). Para instalar LLM Attributor, puedes usar pip :
pip install llm-attributorPuede importar LLM Attributor a sus cuadernos computacionales (por ejemplo, Jupyter Notebook/Lab) e inicializar su modelo y configuraciones de datos.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)Para LLAMA2_DIR y TOKENIZER_DIR, puede ingresar la ruta al modelo base LLaMA2. Estos son necesarios cuando su modelo aún no está afinado. MODEL_SAVE_DIR es el directorio donde está (o se guardará) su modelo ajustado.
Puede probar disaster-demo.ipynb y finance-demo.ipynb para probar la visualización interactiva de LLM Attributor.
LLM Attributor fue creado por Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau y Minsuk Kahng.
El software está disponible bajo la licencia MIT.
Si tiene alguna pregunta, no dude en abrir un problema o comunicarse con Seongmin Lee.


