latent diffusion segmentation
1.0.0
Este repositorio contiene la implementación de LDMSeg en Pytorch: un enfoque de difusión latente simple para la segmentación panóptica y la pintura de máscara. El código proporcionado incluye tanto la capacitación como la evaluación.
Un enfoque simple de difusión latente para la segmentación panóptica y la pintura de máscaras
Wouter Van Gansbeke y Bert De Brabandère
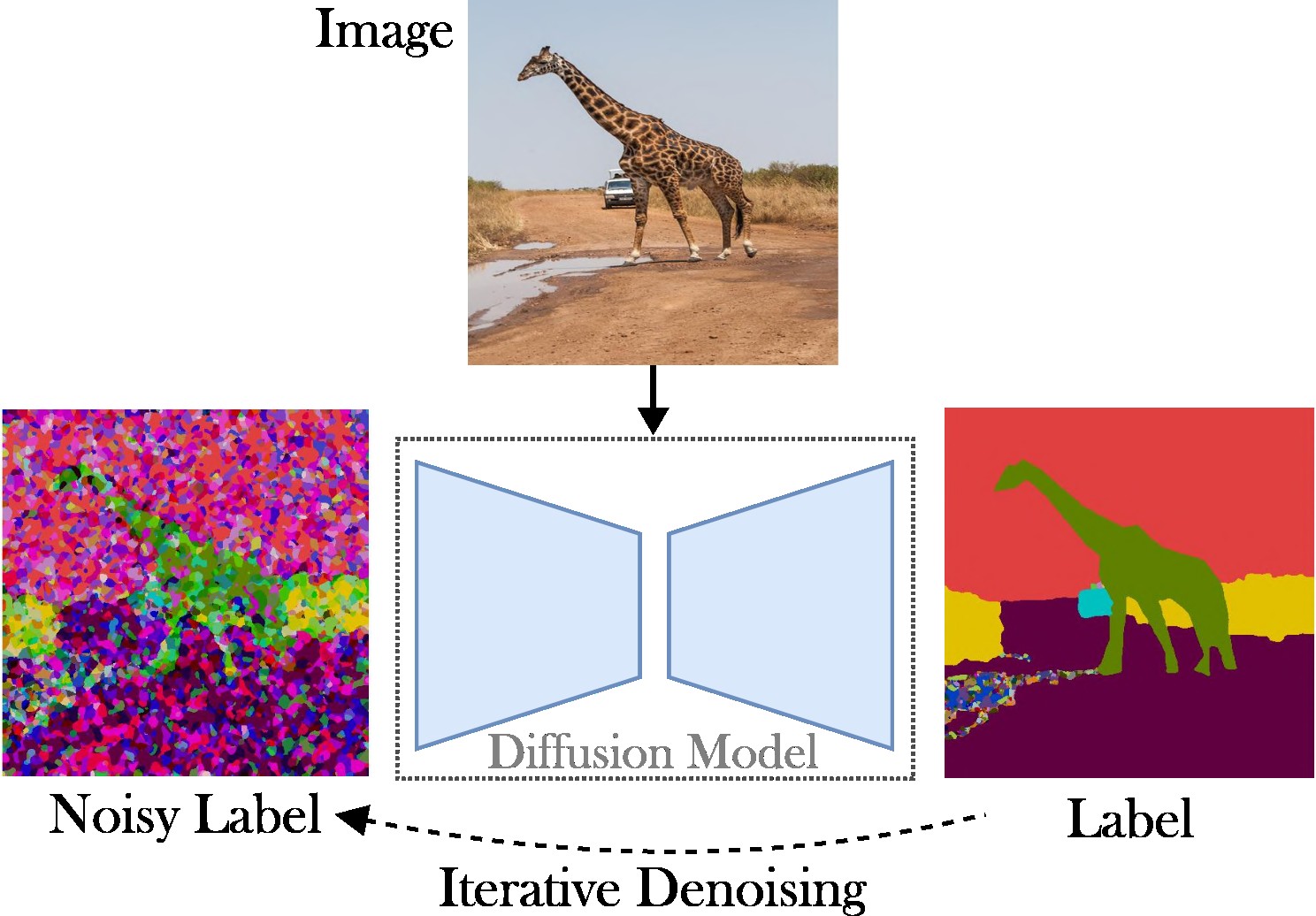
Este artículo presenta un enfoque de difusión latente condicional para abordar la tarea de segmentación panóptica. El objetivo es omitir la necesidad de arquitecturas especializadas (p. ej., redes de propuestas regionales o consultas de objetos), funciones de pérdida complejas (p. ej., coincidencia húngara o basadas en cuadros delimitadores) y métodos de posprocesamiento adicionales (p. ej., agrupamiento, NMS). , o pegado de objetos). Como resultado, confiamos en Stable Diffusion, que es un marco independiente de las tareas. El enfoque presentado consta de dos pasos: (1) proyectar las máscaras de segmentación panóptica en un espacio latente con un codificador automático poco profundo; (2) entrenar un modelo de difusión en espacio latente, condicionado a imágenes RGB.
Contribuciones clave : Nuestras contribuciones son triples:
El código se ejecuta con versiones recientes de Pytorch, por ejemplo, 2.0. Además, puedes crear un entorno Python con Anaconda:
conda create -n LDMSeg python=3.11
conda activate LDMSeg
Recomendamos seguir la instalación automática (consulte tools/scripts/install_env.sh ). Ejecute los siguientes comandos para instalar el proyecto en modo editable. Tenga en cuenta que todas las dependencias se instalarán automáticamente. Como es posible que esto no siempre funcione (por ejemplo, debido a problemas con CUDA o gcc), consulte los pasos de instalación manual.
python -m pip install -e .
pip install git+https://github.com/facebookresearch/detectron2.git
pip install git+https://github.com/cocodataset/panopticapi.gitLos paquetes más importantes se pueden instalar rápidamente con pip como:
pip install torch torchvision einops # Main framework
pip install diffusers transformers xformers accelerate timm # For using pretrained models
pip install scipy opencv-python # For augmentations or loss
pip install pyyaml easydict hydra-core # For using config files
pip install termcolor wandb # For printing and logging Consulte data/environment.yml para obtener una copia de mi entorno. También dependemos de algunas dependencias de detectron2 y panopticapi. Siga sus documentos.
Actualmente admitimos el conjunto de datos COCO. Siga los documentos para instalar las imágenes y sus correspondientes máscaras de segmentación panóptica. Además, eche un vistazo al directorio ldmseg/data/ para ver algunos ejemplos del conjunto de datos COCO. Como nota al margen, la estructura adoptada debería ser bastante estándar:
.
└── coco
├── annotations
├── panoptic_semseg_train2017
├── panoptic_semseg_val2017
├── panoptic_train2017 -> annotations/panoptic_train2017
├── panoptic_val2017 -> annotations/panoptic_val2017
├── test2017
├── train2017
└── val2017
Por último, pero no menos importante, cambie las rutas en configs/env/root_paths.yml a la raíz de su conjunto de datos y al directorio de salida deseado, respectivamente.
El enfoque presentado tiene dos vertientes: primero, entrenamos un codificador automático para representar mapas de segmentación en un espacio de dimensiones inferiores (por ejemplo, 64x64). A continuación, partimos de modelos de difusión latente (LDM) previamente entrenados, particularmente difusión estable, para entrenar un modelo que pueda generar máscaras panópticas a partir de imágenes RGB. Los modelos se pueden entrenar ejecutando los siguientes comandos. De forma predeterminada, entrenaremos en el conjunto de datos COCO con el archivo de configuración base definido en tools/configs/base/base.yaml . Tenga en cuenta que este archivo se cargará automáticamente ya que dependemos del paquete hydra .
python - W ignore tools / main_ae . py
datasets = coco
base . train_kwargs . fp16 = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05 Se pueden encontrar más detalles sobre cómo pasar argumentos en tools/scripts/train_ae.sh . Por ejemplo, ejecuto este modelo durante 50.000 iteraciones en una sola GPU de 23 GB con un tamaño de lote total de 16.
python - W ignore tools / main_ldm . py
datasets = coco
base . train_kwargs . gradient_checkpointing = True
base . train_kwargs . fp16 = True
base . train_kwargs . weight_dtype = float16
base . optimizer_zero_redundancy = True
base . optimizer_name = adamw
base . optimizer_kwargs . lr = 1e-4
base . optimizer_kwargs . weight_decay = 0.05
base . scheduler_kwargs . weight = 'max_clamp_snr'
base . vae_model_kwargs . pretrained_path = '$AE_MODEL' $AE_MODEL denota la ruta al modelo obtenido en el paso anterior. Se pueden encontrar más detalles sobre cómo pasar argumentos en tools/scripts/train_diffusion.sh . Por ejemplo, ejecuté este modelo durante 200.000 iteraciones en 8 GPU de 16 GB con un tamaño de lote total de 256.
Estamos planeando lanzar varios modelos entrenados. La métrica PQ (independiente de la clase) se proporciona en el conjunto de validación COCO.
| Modelo | #parámetros | Conjunto de datos | Iters | PQ | SQ | RQ | Enlace de descarga |
|---|---|---|---|---|---|---|---|
| AE | ~2 millones | PALMA DE COCO | 66k | - | - | - | Descargar (23MB) |
| LDM | ~800M | PALMA DE COCO | 200k | 51,7 | 82.0 | 63.0 | Descargar (3,3 GB) |
Nota: Un AE menos potente (es decir, menos muestreo de capas o de reducción de resolución) a menudo puede resultar beneficioso al pintar, ya que no realizamos ajustes adicionales.
La evaluación debería verse así:
python - W ignore tools / main_ldm . py
datasets = coco
base . sampling_kwargs . num_inference_steps = 50
base . eval_only = True
base . load_path = $ PRETRAINED_MODEL_PATH Puede agregar parámetros si es necesario. Umbrales más altos como --base.eval_kwargs.count_th 700 o --base.eval_kwargs.mask_th 0.9 pueden aumentar aún más las cifras. Sin embargo, utilizamos valores estándar estableciendo un umbral de 0,5 y eliminando segmentos con un área menor que 512 para la evaluación.
Para evaluar un modelo previamente entrenado desde arriba, ejecute tools/scripts/eval.sh .
Aquí visualizamos los resultados:

Si encuentra que este repositorio es útil para su investigación, considere citar el siguiente artículo:
@article { vangansbeke2024ldmseg ,
title = { a simple latent diffusion approach for panoptic segmentation and mask inpainting } ,
author = { Van Gansbeke, Wouter and De Brabandere, Bert } ,
journal = { arxiv preprint arxiv:2401.10227 } ,
year = { 2024 }
}Para cualquier consulta, póngase en contacto con el autor principal.
Este software se publica bajo una licencia creative commons que permite únicamente uso personal y de investigación. Para obtener una licencia comercial, comuníquese con los autores. Puede ver un resumen de la licencia aquí.
Estoy agradecido por todos los repositorios públicos (ver también las referencias en el código), y en particular por las bibliotecas detectron2 y difusores.


