robust concept erasing
1.0.0
Koushik Srivatsan Fahad Shamshad Muzammal Naseer Karthik Nandakumar
Universidad de Inteligencia Artificial Mohamed bin Zayed (MBZUAI), Emiratos Árabes Unidos .

La rápida proliferación de modelos de generación de texto a imagen (T2IG) a gran escala ha generado preocupación sobre su posible uso indebido para generar contenido dañino. Aunque se han propuesto muchos métodos para borrar conceptos no deseados de los modelos T2IG, solo brindan una falsa sensación de seguridad, ya que trabajos recientes demuestran que los modelos de conceptos borrados (CEM) pueden engañarse fácilmente para generar el concepto borrado mediante ataques adversarios. El problema de borrar conceptos adversamente robustos sin una degradación significativa de la utilidad del modelo (capacidad de generar conceptos benignos) sigue siendo un desafío sin resolver, especialmente en el entorno de caja blanca donde el adversario tiene acceso al CEM. Para abordar esta brecha, proponemos un enfoque llamado STEREO que involucra dos etapas distintas. La primera etapa busca a fondo lo suficiente ( STE ) para indicaciones adversas sólidas y diversas que puedan regenerar un concepto borrado de un CEM, aprovechando sólidos principios de optimización del entrenamiento adversario. En la segunda etapa de Borrar Robustamente Una Vez ( REO ), introducimos un objetivo compositivo basado en conceptos ancla para borrar de manera robusta el concepto objetivo de una sola vez, mientras intentamos minimizar la degradación de la utilidad del modelo. Al comparar el enfoque STEREO propuesto con cuatro métodos de borrado de conceptos de última generación bajo tres ataques adversarios, demostramos su capacidad para lograr una mejor compensación entre solidez y utilidad.
Los modelos de difusión a gran escala para la generación de texto a imagen son susceptibles a ataques adversarios que pueden regenerar conceptos dañinos a pesar de los esfuerzos de eliminación. Presentamos STEREO , un enfoque sólido diseñado para evitar esta regeneración y al mismo tiempo preservar la capacidad del modelo para generar contenido benigno.
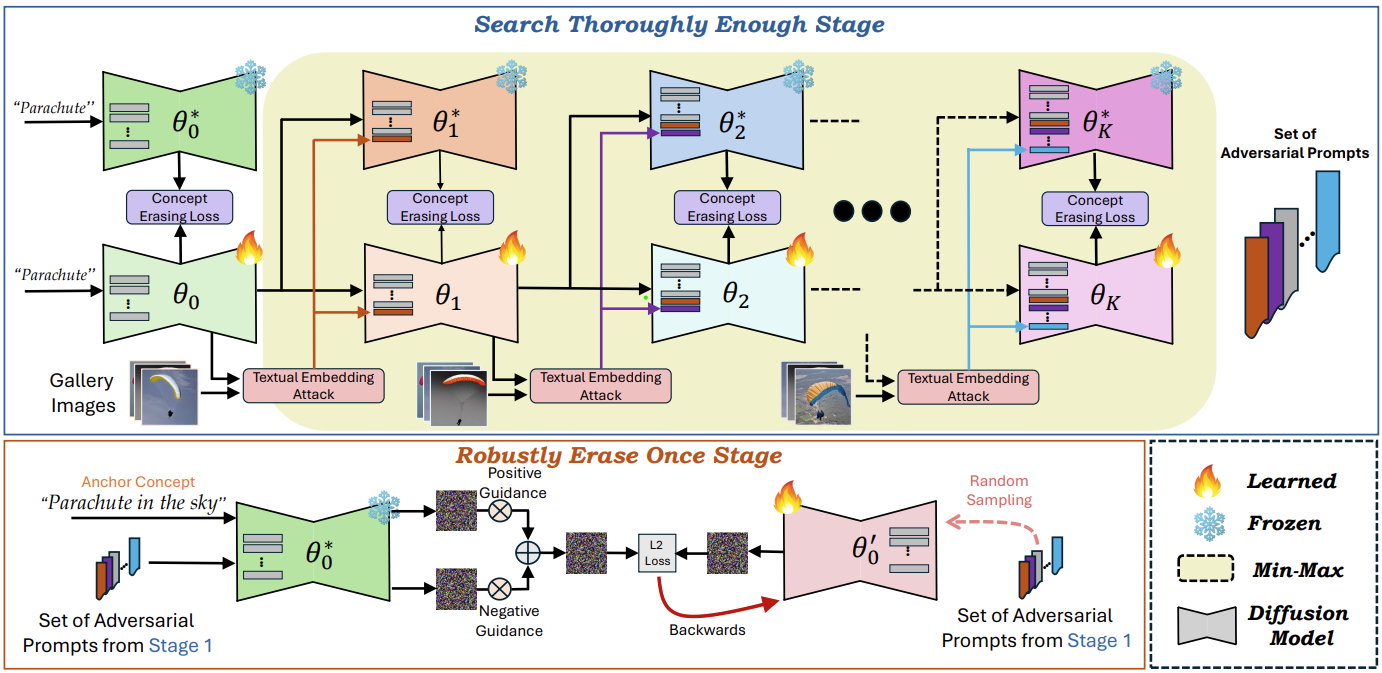
Descripción general de ESTÉREO . Proponemos un novedoso marco de dos etapas para el borrado de conceptos adversamente robusto de modelos de generación de texto a imagen previamente entrenados sin afectar significativamente la utilidad de conceptos benignos.
Etapa 1 (arriba) : Search Thoroughly Enough (STE) sigue el sólido marco de optimización de Adversarial Training y formula el borrado de conceptos como un problema de optimización mínimo-máximo, para descubrir fuertes indicaciones adversas que pueden regenerar conceptos objetivo a partir de modelos borrados. Tenga en cuenta que la principal novedad de nuestro enfoque radica en el hecho de que empleamos AT no como una solución final, sino solo como un paso intermedio para buscar con suficiente profundidad indicaciones adversas fuertes.
Etapa 2 (abajo) : Borrar sólidamente Una vez, se afina el modelo usando un concepto ancla y el conjunto de fuertes indicaciones adversas de la Etapa 1 a través de un objetivo compositivo, manteniendo la generación de alta fidelidad de conceptos benignos mientras se borra de manera sólida el concepto objetivo.
Si encuentra útil nuestro trabajo y este repositorio, considere darle una estrella a nuestro repositorio y citar nuestro artículo de la siguiente manera:
@article { srivatsan2024stereo ,
title = { STEREO: Towards Adversarially Robust Concept Erasing from Text-to-Image Generation Models } ,
author = { Srivatsan, Koushik and Shamshad, Fahad and Naseer, Muzammal and Nandakumar, Karthik } ,
journal = { arXiv preprint arXiv:2408.16807 } ,
year = { 2024 }
}Si tiene alguna pregunta, cree un problema en este repositorio o comuníquese con [email protected].
Nuestro código está construido sobre el repositorio de ESD. Agradecemos a los autores por publicar su código.


